Part III: Core C# Types: Design and Deep Understanding
Part III of the C# Mastery Guide focuses on the core types and language features that form the backbone of C# programming. This section provides a deep understanding of classes, structs, interfaces, and other fundamental constructs, exploring their design, memory management, and advanced features introduced in recent C# versions.
Table of Contents
7. Classes: Reference Types and Object-Oriented Design Deep Dive
- 7.1. The Anatomy of a Class: Object Headers, understanding instance vs. static members, static constructors, and the
beforefieldinitflag. - 7.2. Constructors Deep Dive: Instance and static constructors, Object Initializers, Primary Constructors (C# 12), and derived class constructor resolution.
- 7.3. The
thisKeyword: Instance Reference and Context: Comprehensive coverage ofthisfor referring to the current instance and its contextual uses. - 7.4. Core Class Members: Properties, Indexers, and Events: Compiler transformations,
init-only setters,requiredmembers (C# 11),fieldkeyword (C# 11), and event mechanics. - 7.5. Class Inheritance: Foundations and Basic Design: How the CLR implements inheritance, the
basekeyword, and object slicing considerations. - 7.6. Polymorphism Deep Dive:
virtual,abstract,override, andnew: The concept of runtime polymorphism, method overriding, abstract members, and method hiding. - 7.7. Virtual Dispatch and V-Tables: A deep dive into virtual method tables (V-tables) and how the CLR uses them for dynamic dispatch.
- 7.8. The
sealedKeyword: Usingsealedon types and methods to control inheritance and overriding, and its impact on performance. - 7.9. Type Conversions: Implicit, Explicit, Casting, and Safe Type Checks: Built-in conversions, explicit casting, and the
isandaskeywords for safe type checking. - 7.10. Operator Overloading and User-Defined Conversion Operators: How
op_methods enable custom operator behavior and type conversions. - 7.11. Parameter Modifiers:
ref,out,in, andrefVariables: Detailsref,out,inparameter modifiers for passing arguments by reference, along withreflocals and return types for direct memory aliases, emphasizing their distinct effects on value and reference types. - 7.12. Method Resolution Deep Dive: Overloading and Overload Resolution: Method overloading and the compiler’s algorithm for selecting the best method in complex scenarios, including inheritance.
- 7.13. Nested Types and Local Functions: Their IL representation, scope rules, and implications for closures.
8. Structs: Value Types and Performance Deep Dive
- 8.1. The Anatomy, Memory Layout, and Boxing of a Struct: Detailed memory layout on stack vs. heap, and the performance implications of boxing.
- 8.2. Struct Constructors and Initialization: Understanding default and Primary Constructors (C# 12),
readonlystructs, and field initialization. - 8.3. Struct Identity: Implementing
Equals()andGetHashCode(): Best practices for implementingEquals()andGetHashCode()for structs to ensure correctness and performance. - 8.4. Passing Structs:
in,ref,outParameters Revisited: Detailed IL and performance implications of passing structs byin,ref, andout. - 8.5. High-Performance Types:
ref struct,readonly ref struct, andref fields(C# 11): Deep dive into stack-only types likeref structand their role in high-performance APIs likeSpan<T>. - 8.6. Structs vs. Classes: Choosing the Right Type: A comprehensive comparison of structs vs. classes, guiding optimal type choice and performance trade-offs.
9. Interfaces: Contracts, Implementation, and Modern Features
- 9.1. The Anatomy of an Interface: Understanding interfaces as contracts without state, and their representation in IL.
- 9.2. Interface Dispatch: How interface method calls work via Interface Method Tables (IMTs), a mechanism distinct from class v-tables.
- 9.3. Interface Type Variables and Casting: Understanding interface type variables, their casting rules, and how they differ from class inheritance
- 9.4. Explicit vs. Implicit Implementation: How explicit implementation hides members and resolves naming conflicts when implementing multiple interfaces.
- 9.5. Interface and Inheritance: How interfaces can be used in inheritance hierarchies, including re-implementing inherited interfaces.
- 9.6. Modern Interface Features:
- Default Interface Methods (DIM) (C# 8): Adding default implementations to interfaces without breaking existing implementers.
- Static Abstract & Virtual Members in Interfaces (C# 11): The foundational feature enabling Generic Math, allowing polymorphism on static methods for a wide range of types.
10. Essential C# Interfaces: Design and Usage Patterns
- 10.1. Core Value Type Interfaces:
IComparable<T>,IComparer<T>,IEquatable<T>,IFormattable,IParsable<T>,ISpanFormattable,ISpanParsable<T>– their design, implementation, and compiler integration for type comparison, formatting, and parsing. - 10.2.
IEnumerable: The Magic Behindforeachand Iterator Methods: Understanding howIEnumerable<T>andIEnumerator<T>enable iteration over collections, the mechanics ofyield return, and the compiler-generated state machines that allow deferred execution. - 10.3. Collection Interfaces:
ICollection<T>,IList<T>,ISet<T>,IDictionary<TKey, TValue>and their read-only counterparts – understanding their contracts, common implementations, and performance characteristics. - 10.4. Resource Management:
IDisposable:IDisposableand theDisposemethod for deterministic resource cleanup, and its role in theusingpattern. - 10.5. Mathematical and Numeric Interfaces (Generic Math): A detailed look at interfaces like
IAdditionOperators<TSelf, TOther, TResult>,INumber<TSelf>, and others introduced in C# 11, and how they enable generic algorithms over numeric types.
Here is the summarized version of Chapter 10, formatted as requested for the Table of Contents:
11. Fundamental C# Types: Core Data Structures and Utilities
- 11.1. Strings: Immutability,
StringBuilder, and Performance: A comprehensive exploration ofstring’s immutable nature, string interning, performance considerations, andStringBuilderfor efficient mutable string operations. - 11.2. Enumerations (
enum): Underlying Types, Flags, and Best Practices: Understandingenuminternals, underlying integral types, the[Flags]attribute, and best practices for defining and consuming enumerations. - 11.3. Arrays and
List<T>: Memory, Performance, and Related Types: A deep dive intoSystem.ArrayandList<T>internals, including memory layout, dynamic resizing, and efficient interaction withSpan<T>andReadOnlySpan<T>. - 11.4. Hash-Based Collections:
Dictionary<TKey, TValue>andHashSet<T>: Examining the internal mechanisms of hash tables, including hashing algorithms, collision resolution, and the performance characteristics of these widely used collections. - 11.5. Tuples and
ValueTuple: Structure, Memory, and Modern Usage: Differentiating betweenTupleandValueTuple, exploring their memory layout, performance, and modern use for lightweight data aggregation. - 11.6. I/O Streams and Readers/Writers: Covering the
Streamhierarchy, and the internal workings, buffering, and resource management ofStreamReader/WriterandStringReader/Writerfor character-based I/O. - 11.7. Date, Time, and Unique Identifiers: A detailed look at the internal representations and best practices for handling temporal data with
DateTime,DateTimeOffset,DateOnly,TimeOnly, and unique identifiers withGuid. - 11.8.
Lazy<T>: Deferred Initialization and Resource Management: Understanding howLazy<T>enables efficient, on-demand object creation, its thread-safety mechanisms, and its use in optimizing resource allocation. - 11.9.
Random: Pseudorandomness, Seeding, and Thread Safety: Exploring the internal algorithms behind pseudorandom number generation, the importance of proper seeding, and considerations for thread safety when usingRandominstances. - 11.10.
Regex: Regular Expression Compilation and Performance: A deep dive into theRegexclass, covering its internal state machine, the performance implications of compiled vs. interpreted regular expressions, and strategies for optimizing regex usage.
11. Delegates, Lambdas, and Eventing: Functional Programming Foundations
- 11.1. Delegates Under the Hood: First-class functions in C#, the
MulticastDelegateclass, and the internals ofAction,FuncandPredicategeneric delegates. - 11.2. The
eventKeyword: Compiler generation ofadd_andremove_methods, ensuring thread safety for event subscriptions, and best practices for event design usingEventHandler<T>andEventHandlerdelegates. - 11.3. Lambdas and Closures: How the compiler transforms lambda expressions into hidden classes, and the precise mechanics of variable capture (closures) and their performance implications.
- 11.4. Expression Trees: Representing C# code as data structures (
System.Linq.Expressions.Expression) for runtime interpretation and modification, primarily used by LINQ providers (e.g., LINQ to SQL).
12. Modern Type Design: Records, Immutability, and Data Structures
- 12.1. Record Classes (
record classC# 9): Internals of compiler-generated methods for immutability, value-based equality,withexpressions, andToStringoverrides. - 12.2. Record Structs (
record structC# 10): Applying value-based equality, immutability, andwithexpressions to value types, and their memory layout considerations. - 12.3.
readonlyModifier Beyond Fields: Deep dive intoreadonly structandreadonly members(C# 8), ensuring immutability at the type and member level. - 12.4. Immutability Patterns: Strategies for designing and enforcing immutable types in C#, including the Builder pattern for complex object creation.
- 12.5. Frozen Collections (
System.Collections.Immutable): The immutable collection types provided bySystem.Collections.Immutableand their benefits for concurrent and predictable data structures.
13. Nullability, Safety, and Defensive Programming
- 13.1. The
nullKeyword: Hownullreferences are represented in the CLR and the ubiquitousNullReferenceException. - 13.2. Nullable Reference Types (NRTs) (C# 8+): The compiler’s flow analysis for nullability, nullable annotations (
?), the null-forgiving operator (!), and#nullable enable/disabledirectives. The philosophical shift towards compile-time null safety. - 13.3. Nullable Value Types (
Nullable<T>): The struct’s internals,HasValue,Value, and implicit conversions to and from the underlying type. - 13.4. Null Coalescing and Conditional Operators: The
??,??=,?., and!. operators, their IL representation, and how they improve code safety and readability by handling nulls concisely. - 13.5.
requiredMembers (C# 11): Ensuring proper initialization of members at compile-time for objects, enforcing design contracts. - 13.6. The
nameofOperator: Usingnameofto obtain the string name of a variable, type, or member at compile time, improving refactoring safety and debugging/logging. - 13.7.
throwexpressions (C# 7): Usingthrowas an expression to make error handling more concise in ternary operations, lambda bodies, or property accessors.
7. Classes: Reference Types and Object-Oriented Design Deep Dive
In C#, classes serve as the blueprints for objects, embodying the principles of object-oriented programming. As reference types, instances of classes are allocated on the managed heap, their lifetimes governed by the garbage collector. This chapter moves beyond basic class usage to dissect their internal structure, initialization semantics, member behaviors, and the foundational concepts of inheritance and polymorphism, ultimately aiming to foster an expert-level understanding of how C# classes truly operate from source code to native execution.
7.1. The Anatomy of a Class
To truly understand how classes work, we must first look under the hood at how an object instance is represented in memory and how its members are structured. This low-level view provides crucial insights into performance and runtime behavior.
Object Headers and the MethodTable Pointer
When you instantiate a class using new, the Common Language Runtime (CLR) allocates a block of memory on the managed heap. This memory isn’t just for your instance’s fields; it includes crucial metadata managed by the CLR.
Every object on the managed heap starts with an Object Header. In modern .NET (e.g., .NET 6+), this header typically occupies 8 bytes on a 64-bit system (or 4 bytes on a 32-bit system) and contains two primary components:
- Sync Block Index (or Monitor Table Index): This portion is used for thread synchronization (e.g.,
lockstatements) and storing various flags for the garbage collector (GC), such as object age, whether it’s pinned, etc. It’s often lazily initialized. - MethodTable Pointer (MT Ptr): This is arguably the most important part for understanding object behavior. It’s a pointer to the type’s MethodTable (also known as Type Handle or Class Object), which resides in a special area of memory called the AppDomain’s loader heap. The MethodTable is essentially the CLR’s internal representation of the class itself, containing:
- Information about the type’s base class.
- Interface implementations.
- Metadata about the type’s fields (names, types, offsets).
- Pointers to JIT-compiled native code for all type methods, including instance methods, static methods, and constructors.
- Pointers to the methods implemented by the type. For virtual methods, this will typically include a pointer to the Virtual Method Table (V-Table), which we’ll explore in detail in section 7.7.
This view of the Method Table is heavily simplified and it is explained in more detail in Chapter 3
Conceptual Diagram of an Object in Memory:
[Managed Heap]
+-------------------+
| [Object Header] | <-- object reference (lives on stack) (8 bytes on 64-bit)
| - Sync Block |
| - MethodTable Ptr | ----> [AppDomain's Loader Heap]
+-------------------+ +-----------------------+
| Instance Field 1 | | MethodTable |
| Instance Feild 2 | +-----------------------+
| ... | | Base Type MT Pointer |
+-------------------+ | Interface Map |
| Field Layout Info |
| Ptr to Method 1 Code |
| Ptr to Method 2 Code |
| ... |
| (Ptr to V-Table) |
+-----------------------+
When you call a method on an object, the CLR uses the MethodTable pointer to find the correct method implementation for that object’s specific type. This is crucial for runtime polymorphism.
Understanding Instance vs. Static Members
C# differentiates between members that belong to a specific instance of a class and those that belong to the type itself.
-
Instance Members:
- Fields: These hold data unique to each object instance. They are allocated within the memory block of the object itself on the managed heap.
- Methods: These operate on the data of a specific object instance. They are invoked via an object reference, and implicitly receive the
thispointer (explained in 7.3) to access the instance’s fields and other methods. - Properties, Indexers, Events: These are syntactic sugar for instance methods (as detailed in 7.4) and thus also belong to instances.
public class Car { // Instance field public string Model { get; set; } // Instance method public void Drive() { Console.WriteLine($"Driving {Model}"); } } // Usage: Car myCar = new Car { Model = "Sedan" }; // 'Model' belongs to 'myCar' myCar.Drive(); // 'Drive' operates on 'myCar' -
Static Members:
- Fields: These hold data that is shared by all instances of the class, or data that pertains to the type as a whole. Static fields are allocated in a special memory region within the AppDomain’s loader heap (part of the MethodTable’s associated data), not within individual object instances.
- Methods: These operations do not operate on a specific instance’s data. They are invoked directly on the type name and do not have access to the
thispointer. They are typically used for utility functions, factory methods, or operations that affect the class as a whole. - Properties, Events: Can also be static, behaving similarly to static methods/fields.
public class Car { // Static field: shared by all Car objects public static int NumberOfCarsCreated { get; private set; } = 0; // Static method: operates on type-level data public static void DisplayTotalCars() { Console.WriteLine($"Total cars created: {NumberOfCarsCreated}"); } public Car() // Instance constructor { NumberOfCarsCreated++; // Increments the static field } } // Usage: Car car1 = new Car(); Car car2 = new Car(); Car.DisplayTotalCars(); // Output: Total cars created: 2
Static Constructors and their Execution Order
A static constructor is a special parameterless constructor that belongs to the type itself, not to any specific instance. Its primary purpose is to initialize static fields or to perform any one-time setup for the type.
For more details on static constructors, see the C# Language Specification.
Key characteristics and guarantees:
- Parameterless and Public/Private: Static constructors cannot have parameters and are implicitly
private. You cannot specifypublic,protected,internal, orprivateexplicitly. - No Explicit Invocation: You cannot call a static constructor directly from your code. The CLR automatically invokes it.
- Guaranteed Single Execution: The CLR guarantees that a static constructor will execute at most once for a given AppDomain.
-
Guaranteed Execution Timing: The static constructor is guaranteed to run before any of the following events occur for that type:
- The first instance of the type is created.
- Any static member of the type (including static methods, properties, or fields, but excluding literal constants) is accessed.
This guarantee ensures that static fields are in a valid state and any type-specific setup is completed before the type is used.
class BaseClass { static BaseClass() => Console.WriteLine("BaseClass static constructor"); public BaseClass() => Console.WriteLine("BaseClass instance constructor"); } class DerivedClass : BaseClass { static DerivedClass() => Console.WriteLine("DerivedClass static constructor"); public DerivedClass() => Console.WriteLine("DerivedClass instance constructor"); } // Creating an instance of DerivedClass Console.WriteLine("Creating a new DerivedClass instance..."); DerivedClass obj = new DerivedClass(); Console.WriteLine("Instance created!"); // Output: // Creating a new DerivedClass instance... // DerivedClass static constructor // BaseClass static constructor // BaseClass instance constructor // DerivedClass instance constructor // Instance created!Notice that all static constructors in the inheritance chain are executed before any instance constructor. This ensures that the base class is fully initialized before the derived class’s static constructor runs.
The beforefieldinit Flag
The CLR’s guarantee for static constructors (execution before any static member access or instance creation) comes with a performance cost: it requires runtime checks. To optimize this, the C# compiler (and other .NET language compilers) often emit a special flag called beforefieldinit into the type’s metadata.
- What
beforefieldinitdoes: When a type has thebeforefieldinitflag (which is the default behavior for types without an explicitly declared static constructor), the CLR is allowed to initialize static fields at any point before their first static field access. This often means the static fields are initialized when the type is first loaded by the CLR, which can be much earlier than when they are actually used. This avoids the runtime checks associated with guaranteeing static constructor execution time. - When it’s present: The C# compiler adds the
beforefieldinitflag to a type if it does not have a static constructor but does have static field initializers. - When it’s absent: If you explicitly declare an empty static constructor (
static MyClass() { }), or any static constructor at all, the C# compiler will not emit thebeforefieldinitflag. In this case, the CLR will strictly adhere to the static constructor guarantees (execution before first static member access or instance creation).
Understanding beforefieldinit is crucial for debugging subtle timing issues related to static field initialization and for understanding the CLR’s optimization strategies. For most applications, the default beforefieldinit behavior is harmless and beneficial for performance, but it’s important to be aware of when it’s not applied due to an explicit static constructor.
Declaring and Instantiating New Type Instances
C# offers several syntactic options for declaring and instantiating new objects. The choice of syntax can affect code readability, type inference, and sometimes brevity. Here are the most common patterns:
1. Explicit Type Declaration with Constructor
Car c = new Car();
- Explanation: The variable
cis explicitly declared as typeCar, and a new instance is created using theCarconstructor. - When to use: When you want to be explicit about the variable’s type, which can improve code clarity, especially for readers unfamiliar with the type.
2. Explicit Type Declaration with Target-Typed new (C# 9+)
Car c = new();
- Explanation: The variable
cis declared as typeCar, and thenew()expression infers the type from the variable declaration. This is called “target-typednew.” - When to use: When the type is already clear from the context, this reduces redundancy and keeps code concise.
3. Implicitly Typed Local Variable (var)
var c = new Car();
- Explanation: The
varkeyword tells the compiler to infer the variable’s type from the right-hand side (new Car()), socis of typeCar. - When to use: When the type is obvious from the right-hand side or when working with anonymous types or generics.
4. With Object Initializer
All the above forms can be combined with object initializers for setting properties at creation:
Car c1 = new Car { Model = "Sedan" };
Car c2 = new() { Model = "SUV" };
var c3 = new Car { Model = "Coupe" };
Best Practice:
Choose the syntax that makes your code most readable and maintainable for your team. Use explicit types when clarity is needed, and leverage type inference or target-typed new for brevity when the type is obvious.
7.2. Constructors Deep Dive
Constructors are special methods responsible for initializing the state of an object. C# offers several types of constructors and initialization patterns, each serving a distinct purpose in ensuring an object is ready for use.
Instance Constructors: Purpose, Overloading, and Initialization Flow
An instance constructor is a method called to create and initialize an instance of a class. Unlike regular methods, it has the same name as the class and no return type (not even void).
- Purpose: To set the initial state of the object’s instance fields. This often involves taking parameters to provide initial values for these fields.
- Overloading: A class can have multiple instance constructors, as long as each has a unique signature (different number or types of parameters). This allows for flexible object creation based on different initialization requirements.
- Default Constructor: If you don’t provide any instance constructors, C# automatically provides a public, parameterless default constructor. This default constructor initializes all instance fields to their default values (e.g.,
0for numeric types,nullfor reference types,defaultfor value types). If you define any instance constructor, the default constructor is suppressed, and you must explicitly define a parameterless constructor if you need one.
Initialization Flow within an Instance Constructor:
When an instance of a class is created, the following steps occur in sequence:
- Field Initializers: Any field initializers (e.g.,
public int Value = 10;) are executed. These run before the constructor body. - Base Constructor Call: If the class inherits from another class (which all classes implicitly do from
object), the base class’s constructor is called. This happens before the derived class’s constructor body executes. If no explicitbase(...)call is made, the parameterless constructor of the base class is implicitly called (either the default constructor or the one you defined). Note that if the base class has no parameterless constructor, you must explicitly call a base constructor with parameters. - Constructor Body: The code within the body of the current constructor is executed.
class Person
{
public string Name { get; }
public int Age { get; }
// Default constructor, leverages the constructor with parameters
public Person() : this("Unknown", 0)
{
Console.WriteLine($"Person: parameterless constructor: Name={Name}, Age={Age}");
}
// Constructor with parameters
public Person(string name, int age)
{
Name = name;
Age = age;
Console.WriteLine($"Person: constructor with Name={Name}, Age={Age}");
}
}
class Employee : Person
{
public string Position { get; }
// Implicitly calls base()
public Employee()
{
Position = "Unknown";
Console.WriteLine($"Employee: parameterless constructor: Position={Position}");
}
// Calls another constructor in this class
public Employee(string position) : this(position, "Unknown", 0)
{
Console.WriteLine($"Employee: constructor with Position={position}");
}
// Calls base(name, age)
public Employee(string position, string name, int age) : base(name, age)
{
Position = position;
Console.WriteLine($"Employee: constructor with Position={position}, Name={name}, Age={age}");
}
}
// Usage:
Console.WriteLine("Creating Employee():");
var e1 = new Employee();
Console.WriteLine("\nCreating Employee(\"Developer\"):");
var e2 = new Employee("Developer");
Console.WriteLine("\nCreating Employee(\"Manager\", \"Alice\", 35):");
var e3 = new Employee("Manager", "Alice", 35);
// Output:
// Creating Employee():
// Person: constructor with Name=Unknown, Age=0
// Person: parameterless constructor: Name=Unknown, Age=0
// Employee: parameterless constructor: Position=Unknown
// Creating Employee("Developer"):
// Person: constructor with Name=Unknown, Age=0
// Employee: constructor with Position=Developer, Name=Unknown, Age=0
// Employee: constructor with Position=Developer
// Creating Employee("Manager", "Alice", 35):
// Person: constructor with Name=Alice, Age=35
// Employee: constructor with Position=Manager, Name=Alice, Age=35
Object Initializer Notation (new T { ... })
Object initializer notation is a convenient C# syntax that allows you to assign values to public fields or properties of an object after its constructor has been called, all within a single expression. It is purely syntactic sugar; the compiler transforms it into explicit assignments.
public class Product
{
public int Id { get; set; }
public string Name { get; set; }
public decimal Price { get; set; }
public Product() // Parameterless constructor
{
Console.WriteLine("Product() constructor called.");
}
public Product(int id) // Constructor with ID
{
Id = id;
Console.WriteLine($"Product({id}) constructor called.");
}
}
// Usage:
// Without object initializer
Product p1 = new Product();
p1.Id = 1;
p1.Name = "Laptop";
p1.Price = 1200m;
// With object initializer
Product p2 = new Product // Product() constructor is called first
{
Id = 2,
Name = "Mouse",
Price = 25m
};
// Object initializer with a parameterized constructor
Product p3 = new Product(3) // Product(3) constructor is called first
{
Name = "Keyboard",
Price = 75m
};
How it works (Compiler Transformation):
The compiler transforms p2 = new Product { Id = 2, Name = "Mouse" }; into something conceptually similar to:
Product temp = new Product(); // Calls the constructor
temp.Id = 2; // Then assigns properties/fields
temp.Name = "Mouse";
Product p2 = temp; // Finally assigns the result to the variable
Key Points:
- Execution Order: The constructor is always executed first, followed by the assignments from the object initializer.
- Accessibility: Only public or accessible (e.g.,
internalwithin the same assembly) properties and fields can be set via object initializers. init-only setters andrequiredmembers: Object initializers are particularly useful withinit-only setters (C# 9) to create immutable-like objects where properties can only be set during construction or via an object initializer. They are also crucial for fulfillingrequiredmember (C# 11) initialization guarantees at compile-time. We will revisit these concepts in section 7.4.
Static Constructors: Revisited for Context
While covered in 7.1, it’s worth briefly reiterating static constructors here to clearly contrast them with instance constructors.
- Instance Constructors: Initialize instances of a class. Run every time an object is created. Can be overloaded.
- Static Constructors: Initialize the type itself (its static members). Run at most once. Cannot be overloaded or explicitly called. Their execution timing is guaranteed by the CLR (or optimized by
beforefieldinitif no explicit static constructor).
They both play a role in initialization but operate at different scopes (instance-level vs. type-level).
Primary Constructors (C# 12) for Classes
Introduced in C# 12, Primary Constructors provide a concise way to declare constructor parameters directly in the class (or struct/record) declaration. These parameters are then available throughout the class body, making it ideal for types that primarily initialize their state via constructor arguments.
- Syntax: Parameters are declared directly within the parentheses after the class name.
- Scope and Usage:
- Primary constructor parameters are in scope throughout the entire class body (including field initializers, property accessors, methods, and nested types).
- They are implicitly not fields. If you want to store them as fields, you must explicitly assign them to instance fields or properties.
- They are available to the implicitly generated
ToString(),Equals(),GetHashCode()for records.
- Base Constructor Calls: Primary constructors can directly call a base class constructor using the
base(...)syntax, similar to traditional constructors. - No Other Explicit Constructors: If a class has a primary constructor, every other constructor you define must chain to it.
// Traditional way (for comparison)
public class TraditionalPerson
{
public string Name { get; }
public int Age { get; }
public TraditionalPerson(string name, int age)
{
Name = name;
Age = age;
}
}
// Using Primary Constructor (C# 12)
public class ModernPerson(string name, int age) // Primary Constructor
{
// 'name' and 'age' are available throughout the class body
public string Name { get; } = name; // Assigning to a property
public int Age { get; } = age;
public void Greet()
{
Console.WriteLine($"Hello, my name is {name} and I am {age} years old."); // Directly using parameter
}
// You can still have a parameterless constructor, but it must chain:
public ModernPerson() : this("Default") // Chains to the primary constructor
{
Console.WriteLine("Default ModernPerson created.");
}
public ModernPerson(string name) : this(name, 0) // Overloaded constructor
{
Console.WriteLine($"ModernPerson created with name: {name}");
}
}
// Primary constructor with base call
public class Employee(string name, int age, string employeeId) : ModernPerson(name, age)
{
public string EmployeeId { get; } = employeeId;
public void Work()
{
Console.WriteLine($"{Name} (ID: {EmployeeId}) is working.");
}
}
// Usage and output:
Console.WriteLine("ModernPerson primary constructor example:");
ModernPerson person1 = new ModernPerson("Alice", 30);
person1.Greet();
// Hello, my name is Alice and I am 30 years old.
Console.WriteLine("\nModernPerson() chained parameterless ctor example:");
ModernPerson person2 = new ModernPerson();
// ModernPerson created with name: Default
// Default ModernPerson created.
person2.Greet();
// Hello, my name is Default and I am 0 years old.
Console.WriteLine("\nEmployee example using primary constructor:");
Employee emp1 = new Employee("Bob", 45, "EMP123");
emp1.Greet();
// Hello, my name is Bob and I am 45 years old.
emp1.Work();
// Bob (ID: EMP123) is working.
Primary constructors reduce boilerplate, especially for data-carrying types like records, and improve readability by consolidating parameter declarations with the class definition.
While they are a powerful feature, they are not a replacement for traditional constructors in all scenarios. They shine in cases where the class primarily exists to hold data and where constructor parameters can be directly mapped to properties or fields. However, for more complex initialization logic or when multiple constructors with different signatures are needed, traditional constructors may still be preferable.
Derived Class Constructor Resolution
When a derived class instance is created, a crucial part of the initialization flow (as briefly mentioned in instance constructors) is the calling of a base class constructor. This process ensures that the base portion of the object is correctly initialized before the derived portion.
- Constructor Chaining: Every instance constructor in a derived class must implicitly or explicitly call a constructor in its direct base class. This creates a “chain” of constructor calls, starting from the most derived class and proceeding up the inheritance hierarchy to the
objectclass. - Implicit Base Constructor Call: If you do not explicitly call a base constructor using
base(...), the compiler implicitly adds a call to the parameterless constructor of the base class.- Requirement: This means the base class must have an accessible parameterless constructor. If it doesn’t, you’ll get a compile-time error.
- Explicit Base Constructor Call: You can explicitly choose which base constructor to call using the
basekeyword followed by parentheses containing the arguments for the base constructor. This allows you to pass specific values from the derived constructor’s parameters (or other expressions) to the base class’s initialization logic. - Chaining to Other Constructors: You can also chain to other constructors in the same class using
this(...), note that this eventually leads to a base constructor call as well.
Execution Order of the Constructor Chain:
The most important rule to remember is that the base class’s constructor always executes fully before the derived class’s constructor body begins execution.
Consider the hierarchy Animal -> Dog:
public class Animal
{
public string Species { get; set; }
public Animal(string species)
{
Console.WriteLine($"Animal({species}) constructor called.");
Species = species;
}
public Animal() : this("Unknown") // Chains to the parameterized constructor
{
Console.WriteLine("Animal() default constructor called.");
}
}
public class Dog : Animal
{
public string Breed { get; set; }
// Derived constructor implicitly calls base()'s parameterless constructor
public Dog()
{
Console.WriteLine("Dog() constructor called.");
Breed = "Mixed";
}
// Derived constructor explicitly calls base(string species)
public Dog(string species, string breed) : base(species)
{
Console.WriteLine($"Dog({species}, {breed}) constructor called.");
Breed = breed;
}
// Another derived constructor explicitly calls base()
public Dog(string breed) : base()
{
Console.WriteLine($"Dog({breed}) constructor called.");
Breed = breed;
}
}
Console.WriteLine("--- Creating Dog 1 (implicit base call) ---");
Dog dog1 = new Dog();
// Output:
// Animal(Unknown) constructor called.
// Animal() default constructor called.
// Dog() constructor called.
Console.WriteLine($"Dog 1: {dog1.Species}, {dog1.Breed}\n"); // Unknown, Mixed
Console.WriteLine("--- Creating Dog 2 (explicit base call with species) ---");
Dog dog2 = new Dog("Canine", "Golden Retriever");
// Output:
// Animal(Canine) constructor called.
// Dog(Canine, Golden Retriever) constructor called.
Console.WriteLine($"Dog 2: {dog2.Species}, {dog2.Breed}\n"); // Canine, Golden Retriever
Console.WriteLine("--- Creating Dog 3 (explicit base call to default) ---");
Dog dog3 = new Dog("Poodle");
// Output:
// Animal(Unknown) constructor called.
// Animal() default constructor called.
// Dog(Poodle) constructor called.
Console.WriteLine($"Dog 3: {dog3.Species}, {dog3.Breed}\n"); // Unknown, Poodle
This meticulous constructor chaining ensures that the “base part” of a derived object is always fully initialized and consistent before the derived class adds its own specific state. This is fundamental to maintaining the integrity of the object’s inheritance hierarchy.
7.3. The this Keyword: Instance Reference and Context
The this keyword in C# is a special read-only reference that points to the current instance of the class or struct in which it is used. It is available only within instance members (instance constructors, methods, properties, indexers, and event accessors). Static members, belonging to the type itself rather than an instance, cannot use this.
Referring to the Current Instance’s Members
The most common use of this is to explicitly refer to a member of the current object. While often optional (the compiler usually infers this), it becomes necessary for disambiguation.
public class Calculator
{
private int _result; // Backing field
public int Result // Property
{
get { return _result; }
set { _result = value; }
}
public void Add(int value)
{
// Disambiguation: 'value' is a parameter, 'this._result' refers to the instance field
this._result += value;
// Or: this.Result += value; // Accessing via property
}
public void Reset()
{
this.Result = 0; // Explicitly calling the setter of the Result property on this instance
}
}
Using this explicitly for fields/properties, even when not strictly necessary for disambiguation, can sometimes improve code readability by clearly indicating that a member belongs to the instance.
Passing the Current Instance as an Argument
this is also used when you need to pass a reference to the current object as an argument to a method, especially when implementing patterns like Observer or when a method requires a reference to its caller or context.
public class Logger
{
public void LogActivity(object source, string activity)
{
Console.WriteLine($"[{source.GetType().Name}] {activity}");
}
}
public class Worker
{
private Logger _logger = new Logger();
public void PerformTask()
{
// Pass 'this' (the current Worker instance) as the source of the log message
_logger.LogActivity(this, "Performing a complex task.");
}
}
Worker worker = new Worker();
worker.PerformTask();
// Output: [Worker] Performing a complex task.
Other Contextual Uses
-
Constructor Chaining: As mentioned before,
this(...)is used to call another constructor in the same class, allowing for flexible initialization patterns.public class Person { public string Name { get; } public int Age { get; } // Main constructor public Person(string name, int age) { Name = name; Age = age; } // Chained constructor public Person(string name) : this(name, 0) {} } -
Indexers: The
thiskeyword is used in the declaration of indexers to represent the instance on which the indexer operates.public class StringCollection { private string[] data = new string[10]; // Indexer: allows accessing data like an array (e.g., myCollection[0]) public string this[int index] { get { return data[index]; } set { data[index] = value; } } } -
Events: In event handlers,
thiscan be used to refer to the instance that raised the event, allowing subscribers to know the context of the event.public class Button { public event EventHandler Clicked; public void Click() { // Raise the Clicked event, passing 'this' as the sender Clicked?.Invoke(this, EventArgs.Empty); } } -
Extension Methods: When defining extension methods,
thisis used in the method signature to indicate that the method extends the type specified bythis.public static class ListExtensions { // Extension method for List<T> public static void PrintAll<T>(this List<T> list) { foreach (var item in list) { Console.WriteLine(item); } } } List<int> numbers = new List<int> { 1, 2, 3 }; numbers.PrintAll(); // Calls the extension method // syntax sugar for: ListExtensions.PrintAll(numbers);
In essence, the this keyword serves as an unambiguous reference to the current object, enabling clear access to its members, facilitating constructor chaining, and providing a means to pass the object itself as a parameter. It solidifies the object-oriented paradigm by always pointing back to the specific instance in focus.
7.4. Core Class Members: Properties, Indexers, and Events
Classes define their behavior and expose their data through members. While fields directly store data, C# provides richer abstractions like properties, indexers, and events, which are ultimately translated by the compiler into methods, offering more control and flexibility.
Properties: Compiler Transformation, init-only Setters, required Members, and field Keyword
Properties are member that provide a flexible mechanism to read, write, or compute the value of a private field. They are often referred to as “smart fields” because they encapsulate the underlying data access with methods, allowing for validation, logging, or other logic.
Compiler Transformation (get_, set_ methods):
At the IL (Intermediate Language) level, a property is not a field. It’s a pair of methods: a get_ method for reading the value and a set_ method for writing the value.
public class User
{
private string _userName; // Backing field
public string UserName // Property
{
get { return _userName; } // get_UserName() method
set { _userName = value; } // set_UserName(string value) method
}
}
When you write user.UserName = "Alice";, the compiler emits a call to user.set_UserName("Alice");. When you write string name = user.UserName;, it emits a call to user.get_UserName();.
Auto-Implemented Properties: For simple properties where no extra logic is needed in the getter or setter, C# provides auto-implemented properties. The compiler automatically creates a private, anonymous backing field.
public string Email { get; set; } // Compiler generates a private backing field for Email
Expression-bodied Properties (=> Notation):
C# allows properties to be implemented using the concise expression-bodied member syntax, introduced in C# 6. This uses the => (lambda arrow) notation to define a property whose getter simply returns the result of a single expression.
public class Circle
{
public double Radius { get; set; }
public double Area => Math.PI * Radius * Radius;
}
// Usage:
var c = new Circle { Radius = 3 };
Console.WriteLine(c.Area); // Output: 28.2743338823081
This is functionally equivalent to:
public double Area
{
get { return Math.PI * Radius * Radius; }
}
Key Points:
- Expression-bodied properties are read-only (getter-only).
- They do not have an automatically generated backing field; they compute the value dynamically each time accessed.
- They are ideal for computed properties that return a value based on other fields or properties.
init-only setters (C# 9):
Introduced in C# 9, init-only setters allow a property to be set only during object construction (either via a constructor or an object initializer) and then become immutable. This is incredibly useful for creating objects that are “immutable after creation.”
public class ImmutablePoint
{
public int X { get; init; } // Can only be set in constructor or object initializer
public int Y { get; init; }
// Constructor can set init-only properties
public ImmutablePoint(int x, int y)
{
X = x;
Y = y;
}
}
// Usage:
ImmutablePoint p1 = new ImmutablePoint(10, 20); // OK
// p1.X = 5; // Compile-time error: Init-only property cannot be assigned outside of initialization.
ImmutablePoint p2 = new ImmutablePoint { X = 30, Y = 40 }; // OK: Object initializer works
// p2.Y = 50; // Compile-time error
required members (C# 11):
C# 11 introduced the required modifier for properties and fields. This modifier indicates that a member must be initialized by all constructors of the containing type, or by an object initializer, at compile time. This provides compile-time guarantees that critical properties are never left uninitialized.
public class Configuration
{
public required string ApiKey { get; set; } // Must be initialized
public required Uri BaseUrl { get; init; } // Must be initialized, and then immutable
public int TimeoutSeconds { get; set; } = 30; // Optional, has default
}
// Usage:
// Configuration config1 = new Configuration(); // Compile-time error: ApiKey and BaseUrl are required
Configuration config2 = new Configuration // OK: All required members initialized
{
ApiKey = "mysecretkey",
BaseUrl = new Uri("[https://api.example.com](https://api.example.com)")
};
// You can also initialize via constructor (if a constructor assigns them)
public class AnotherConfig
{
public required string SettingA { get; set; }
public required int SettingB { get; init; }
public AnotherConfig(string a, int b) // Constructor initializes required members
{
SettingA = a;
SettingB = b;
}
}
// AnotherConfig cfg = new AnotherConfig(); // Error if no parameterless ctor
AnotherConfig cfg2 = new AnotherConfig("ValueA", 123); // OK
// AnotherConfig cfg3 = new AnotherConfig { SettingA = "ValueA" }; // Error: SettingB is required
The field keyword (C# 11+ preview):
In C# 11, the field keyword was introduced to provide a way to directly reference the auto-generated backing field from within property accessors (get/set/init). This simplifies scenarios where you need to perform validation or side-effects without recursively calling the accessor itself. Note that as of C# 13, this feature is still in preview and may change in future releases. If you wish to use it, you need to enable preview features in your project settings.
For more details on the field keyword, see the C# Language Specification.
public class Item
{
private string _name; // Traditional backing field
public string Name // Property using traditional backing field
{
get => _name;
set
{
if (string.IsNullOrWhiteSpace(value))
throw new ArgumentException("Name cannot be empty.");
_name = value;
}
}
// Property using 'field' keyword (C# 11+ preview)
public int Quantity
{
get => field; // Reads directly from the auto-generated backing field
set
{
if (value < 0)
throw new ArgumentOutOfRangeException(nameof(value), "Quantity cannot be negative.");
field = value; // Assigns directly to the auto-generated backing field
}
}
}
Before field, you’d typically need to explicitly declare a private backing field for Quantity if you wanted to add logic to its accessors without recursion. The field keyword simplifies this by giving you a direct reference to the compiler-generated backing field.
Indexers
Indexers are a special kind of property that allows objects to be indexed in the same way as arrays or collections. They provide a more natural syntax for accessing elements contained within an object.
- Syntax: Declared using
this[]followed by parameters, much like a method. - Compiler Transformation: Like properties, indexers are compiled into
get_Itemandset_Itemmethods (e.g.,get_Item(int index),set_Item(int index, string value)).
class StringList
{
private List<string> _strings = new();
public int Count => _strings.Count;
public void Add(string s) => _strings.Add(s);
// Single-parameter indexer: get string
public string this[int index] {
get => _strings[index];
set => _strings[index] = value;
}
// Two-parameter indexer: get char at (stringIndex, charIndex)
public char this[int stringIndex, int charIndex] {
get => _strings[stringIndex][charIndex];
}
}
// Usage:
var list = new StringList();
list.Add("Hello");
list.Add("World");
list.Add("CSharp");
// Print strings
for (int i = 0; i < list.Count; i++)
Console.WriteLine($"{i}: {list[i]}");
// Access individual characters
Console.WriteLine($"\nCharacter at (0,1): {list[0, 1]}"); // e
Console.WriteLine($"Character at (1,2): {list[1, 2]}"); // r
// Try to Modify a character
// list[2, 0] = 'c'; // error: read-only indexer
// Output:
// 0: Hello
// 1: World
// 2: CSharp
//
// Character at (0,1): e
// Character at (1,2): r
Events
Events in C# provide a mechanism for a class or object to notify other classes or objects when something interesting happens. They are a core component of the Observer (or Publish-Subscribe) design pattern. At their core, events are built upon delegates (which we will cover in depth in Chapter 11).
- Mechanism: An event acts as a list of delegate instances (event handlers) that are invoked when the event is “raised” or “fired.”
- Compiler Transformation (
add_,remove_methods): Similar to properties, events are not directly fields. The compiler transforms an event declaration into two methods: anadd_method (to subscribe an event handler) and aremove_method (to unsubscribe an event handler). These methods typically add or remove delegates from an underlying delegate field.
// Define a simple delegate for demonstration
public delegate void ValueChangedHandler(string newValue);
// Using Action<T> or Func<T> is often preferred in modern C#
// public event Action<string> ValueChanged;
public class DataStore
{
private string _data;
// Declare an event using the custom delegate
public event ValueChangedHandler DataChanged;
public string Data
{
get { return _data; }
set
{
if (_data != value)
{
_data = value;
// Raise the event
OnDataChanged(value);
}
}
}
// A protected virtual method to raise the event
// This allows derived classes to override the event raising logic
protected virtual void OnDataChanged(string newValue)
{
// Null-conditional operator (?.) is used for thread-safe event invocation
// It checks if DataChanged is not null before invoking
DataChanged?.Invoke(newValue);
}
}
public class DataDisplay
{
public void OnDataStoreDataChanged(string newData)
{
Console.WriteLine($"Display: Data changed to '{newData}'");
}
}
DataStore store = new DataStore();
DataDisplay display = new DataDisplay();
// Subscribe to the event: Compiler calls store.add_DataChanged(display.OnDataStoreDataChanged)
store.DataChanged += display.OnDataStoreDataChanged;
store.Data = "Initial data"; // Output: Display: Data changed to 'Initial data'
store.Data = "Updated data"; // Output: Display: Data changed to 'Updated data'
// Unsubscribe from the event: Compiler calls store.remove_DataChanged(display.OnDataStoreDataChanged)
store.DataChanged -= display.OnDataStoreDataChanged;
store.Data = "Final data"; // No output, as handler is unsubscribed
Custom Event Accessors:
Just as properties can have custom get/set logic, events can have custom add/remove accessors. This is used for advanced scenarios, such as when you want to store event handlers in a custom data structure (e.g., to conserve memory for many events) rather than the compiler-generated delegate field.
using System.ComponentModel; // Using EventHandlerList for custom event storage
public class CustomEventSource
{
// Custom storage for event handlers
private EventHandlerList _eventHandlers = new EventHandlerList();
private static readonly object DataChangedEventKey = new object();
public event EventHandler DataChanged
{
add { _eventHandlers.AddHandler(DataChangedEventKey, value); }
remove { _eventHandlers.RemoveHandler(DataChangedEventKey, value); }
}
protected virtual void OnDataChanged(EventArgs e)
{
EventHandler handler = (EventHandler)_eventHandlers[DataChangedEventKey];
handler?.Invoke(this, e);
}
public void SimulateDataUpdate()
{
Console.WriteLine("Simulating data update.");
OnDataChanged(EventArgs.Empty);
}
}
// EventHandlerList is a system class often used in WinForms/WPF for events
// For a general application, you might implement a custom list of delegates.
In this section, we focused on the fundamental mechanics of events and their compiler transformations. A deeper dive into delegates, event patterns, and common event arguments (EventArgs) will be covered in Chapter 11.
7.5. Class Inheritance: Foundations and Basic Design
Inheritance is a cornerstone of object-oriented programming, allowing you to define a new class (the derived class or subclass) based on an existing class (the base class or superclass). This establishes an “is-a” relationship (e.g., a Dog is an Animal), promoting code reuse, extensibility, and polymorphism.
How the CLR Implements Inheritance
In C#, a class can inherit from only a single direct base class (single inheritance), although it can implement multiple interfaces (multiple interface inheritance, which is distinct from class inheritance). All classes implicitly or explicitly derive from System.Object.
Memory Layout of Derived Class Instances: When you create an instance of a derived class, its memory footprint on the managed heap includes the fields of all its base classes, in addition to its own declared fields. The base class’s fields are typically laid out first, followed by the derived class’s fields.
Conceptual Diagram of Derived Object in Memory:
[Managed Heap]
+-----------------------------------+
| Object Header |
| (MethodTable Ptr) | ----> [AppDomain's Loader Heap]
+-----------------------------------+ +---------------------------+
| Base Class Field 1 | | MethodTable (Derived) |
| Base Class Field 2 | +---------------------------+
| ... | | Ptr to Base MethodTable |
| Base Class Field N | | Derived Field Info |
+-----------------------------------+ | Ptr to Derived Method 1 |
| Derived Class Field 1 | | Ptr to Derived Method 2 |
| Derived Class Field 2 | | ... |
| ... | | (Ptr to V-Table) |
| Derived Class Field M | +---------------------------+
+-----------------------------------+
The MethodTable of the derived class points to its base class’s MethodTable, forming a chain that the CLR can traverse to find inherited members and resolve method calls.
Method Lookup:
When an instance method is called on an object, the CLR uses the object’s MethodTable pointer to find the method. If the method isn’t found directly in the current type’s MethodTable, the CLR follows the chain up to the base class’s MethodTable, and so on, until the method is found or the object class is reached. This process is fundamental to how inherited methods are invoked and will be elaborated upon in 7.10 (Method Resolution Deep Dive).
Use of the base Keyword
The base keyword serves two primary purposes within a derived class:
- Calling a Base Class Constructor: As discussed in 7.2,
base(...)is used in a derived class’s constructor to explicitly invoke a specific constructor of its direct base class. This ensures the base portion of the object is correctly initialized before the derived part. -
Accessing Shadowed Base Class Members: If a derived class declares a member (field, property, or method) with the same name as an inherited member from its base class, the derived member shadows (or hides) the base member. The
basekeyword allows you to explicitly access the hidden base member.public class Vehicle { public string Model { get; set; } = "Generic Vehicle"; public void StartEngine() { Console.WriteLine("Vehicle engine started."); } } public class Car : Vehicle { // Shadows Vehicle.Model (implicit hiding) public string Model { get; set; } = "Sports Car"; // Compiler Warning: implicitly hides inherited member public void Accelerate() { Console.WriteLine("Car accelerating."); } public new void StartEngine() // Hides Vehicle.StartEngine explicitly { Console.WriteLine("Car engine started with a roar!"); base.StartEngine(); // Calls the base class's StartEngine method } public void DisplayModels() { Console.WriteLine($"Car's Model: {this.Model}"); // Refers to Car.Model Console.WriteLine($"Vehicle's Model (via base): {base.Model}"); // Refers to Vehicle.Model } } Car myCar = new Car(); myCar.DisplayModels(); // Output: // Car's Model: Sports Car // Vehicle's Model (via base): Generic Vehicle myCar.StartEngine(); // Output: // Car engine started with a roar! // Vehicle engine started.While
newexplicit hiding is allowed, it’s generally discouraged in favor ofoverridefor polymorphism (discussed in 7.6), as hiding can lead to unexpected behavior depending on the declared type of the reference. Implicit hiding (withoutnew) generates a compiler warning.
Object Slicing Considerations
Object slicing is a concept found in languages like C++ where a derived class object, when assigned to a base class value (not a reference/pointer), can lose its derived-specific data, effectively being “sliced” down to just the base class portion.
In C#, object slicing DOES NOT occur. This is a crucial distinction due to C#’s type system and how reference types are handled. When you assign an instance of a derived class to a base class variable, you are not copying the object’s value or creating a new object. Instead, you are simply assigning the reference to the existing derived class object to a variable of the base class type. The object on the heap remains a full derived class instance.
Key Takeaways (Part 1)
- Object Memory: Class instances (
objects) reside on the managed heap, starting with an Object Header containing a MethodTable pointer linking to type metadata. - Member Types: Understand the fundamental difference between instance members (belong to each object, accessed via
this) and static members (belong to the type, shared by all instances). - Static Constructors: Guaranteed to run at most once per AppDomain, strictly before the first instance creation or static member access.
beforefieldinit: A compiler optimization that allows static fields (without an explicit static constructor) to be initialized earlier, potentially before their first usage, for performance.- Instance Constructors: Initialize individual object instances; they can be overloaded and implicitly or explicitly call base constructors.
- Object Initializers: A C# syntactic sugar (
new T { ... }) that assigns values to properties/fields after the constructor has executed, offering concise object setup. - Primary Constructors (C# 12): A modern, concise syntax for constructor parameters, making them available throughout the class body and streamlining base constructor calls.
- Constructor Chaining: Every derived class constructor implicitly or explicitly calls a base class constructor, ensuring the base object’s initialization completes before the derived object’s.
- The
thisKeyword: Unambiguously refers to the current instance, used for member access, passing the object, and constructor chaining (this(...)). - Properties: Syntactic sugar for
get_andset_methods, offering controlled data access. Includesinit-only setters (C# 9),requiredmembers (C# 11), and thefieldkeyword (C# 11). - Indexers: Provide array-like access (
this[]) to objects, compiled intoget_Itemandset_Itemmethods. - Events: A notification mechanism built on delegates, compiled into
add_andremove_methods. - Inheritance Foundation: Establishes an “is-a” relationship; derived objects include base class fields in their memory layout.
baseKeyword: Used to call base constructors or access shadowed base members.- No Object Slicing in C#: Due to reference type semantics, assigning a derived object to a base class variable only changes the reference type, not the underlying object’s structure on the heap.
7.6. Polymorphism Deep Dive: virtual, abstract, override, and new
Polymorphism, literally meaning “many forms,” is one of the pillars of object-oriented programming. In C#, it primarily refers to runtime polymorphism (also known as dynamic dispatch), where the specific method implementation that gets executed is determined at runtime, based on the actual type of the object, rather than the compile-time type of the variable. This mechanism allows you to write flexible, extensible code that can operate on a base type while invoking specialized behavior in derived types.
The Concept of Runtime Polymorphism
Imagine a drawing application where you have various shapes: circles, squares, triangles. All are Shapes. If you have a list of Shape objects, you want to be able to call a Draw() method on each one, and have the correct Draw() implementation (e.g., Circle.Draw(), Square.Draw()) be invoked, even though you’re holding them all as Shape references. This is precisely what runtime polymorphism enables.
At its core, polymorphism allows a derived class object to be treated as a base class object, yet retain its specific derived behavior for certain methods.
virtual Methods and the override Keyword: Enabling Dynamic Behavior
The virtual and override keywords are the primary tools for achieving runtime polymorphism in C#.
-
virtualKeyword:- Applied to a method, property, indexer, or event in a base class.
- It signals to the CLR that this member’s implementation might be replaced by a derived class.
- Declaring a member
virtualmeans that when it’s invoked through a base class reference, the CLR must perform a runtime lookup to determine the actual type of the object and execute that type’s specific implementation (if overridden). - C# Language Reference: virtual
-
overrideKeyword:- Applied to a method, property, indexer, or event in a derived class.
- It explicitly indicates that this member provides a new implementation for a
virtual(orabstract) member inherited from a base class. - The
overridemethod must have the exact same signature (name, parameters, return type) and accessibility as the base class’svirtualmember. - C# Language Reference: override
Example: virtual and override in action
public class Animal
{
public virtual void MakeSound() // 'virtual' allows derived classes to change behavior
{
Console.WriteLine("Animal makes a sound.");
}
public void Eat() // Non-virtual method
{
Console.WriteLine("Animal eats food.");
}
}
public class Dog : Animal
{
public override void MakeSound() // 'override' provides Dog's specific behavior
{
Console.WriteLine("Dog barks: Woof! Woof!");
}
public new void Eat() // This is hiding, not overriding. See below.
{
Console.WriteLine("Dog eagerly eats kibble.");
}
}
public class Cat : Animal
{
public override void MakeSound() // Another specific behavior
{
Console.WriteLine("Cat meows: Meow.");
}
}
// Usage:
Animal myAnimal = new Animal();
Dog myDog = new Dog();
Cat myCat = new Cat();
Console.WriteLine("--- Direct Calls ---");
myAnimal.MakeSound(); // Output: Animal makes a sound.
myDog.MakeSound(); // Output: Dog barks: Woof! Woof!
myCat.MakeSound(); // Output: Cat meows: Meow.
myDog.Eat(); // Output: Dog eagerly eats kibble.
Console.WriteLine("\n--- Polymorphic Calls via Base Reference ---");
Animal animalAnimalRef = new Animal();
Animal animalDogRef = new Dog();
Animal animalCatRef = new Cat();
animalAnimalRef.MakeSound(); // Output: Animal makes a sound. (runtime type is Animal)
animalDogRef.MakeSound(); // Output: Dog barks: Woof! Woof! (runtime type is Dog)
animalCatRef.MakeSound(); // Output: Cat meows: Meow. (runtime type is Cat)
animalDogRef.Eat(); // Output: Animal eats food. (runtime type is Dog, but 'Eat' is not virtual, so Base's Eat is called)
Explanation: When animalDogRef.MakeSound() is called, even though animalDogRef is declared as an Animal (compile-time type), the CLR determines that the object it actually points to at runtime is a Dog. Because MakeSound is virtual in Animal and overriden in Dog, the Dog’s MakeSound implementation is invoked. This is dynamic dispatch.
For animalDogRef.Eat(), since Eat is not virtual in Animal, the call is resolved at compile time based on the Animal reference. The Dog’s new Eat() method is entirely ignored in this polymorphic context. This highlights the crucial difference between override and new.
base Keyword in Polymorphism: Accessing Base Class Members
When you override a method, you can still call the base class’s version of that method using the base keyword. This is useful when you want to extend the base behavior rather than completely replace it.
class Logger
{
// Virtual property for a suffix
public virtual string Suffix => "";
// Virtual log method
public virtual void Log(string message)
{
Console.WriteLine($"{message}{Suffix}");
}
}
class PrefixedLogger : Logger
{
private readonly string _prefix;
public PrefixedLogger(string prefix)
{
_prefix = prefix;
}
// overrides Suffix too
public override string Suffix => " [logged]";
// Override Log to add prefix and delegate to base
public override void Log(string message)
{
string prefixedMessage = $"{_prefix}: {message}";
base.Log(prefixedMessage);
}
}
Logger logger = new PrefixedLogger("INFO");
logger.Log("Hello world");
// Output: INFO: Hello world [logged]
abstract Classes and Methods: Enforcing Derived Implementations
The abstract keyword allows you to define members that must be implemented by non-abstract derived classes. It’s used to establish a contract.
-
abstractMember (typically Method/Property):- Declared in an
abstractclass. - Has no implementation (no method body).
- Forces non-abstract derived classes to
overrideit. - C# Language Reference: abstract
- Declared in an
-
abstractClass:- A class declared with the
abstractmodifier. - Cannot be instantiated directly using
new. You can only create instances of its non-abstract derived classes. - Can contain
abstractmembers, but doesn’t have to. Can also contain concrete (non-abstract) members. - Serves as a base class that provides common functionality while leaving specific implementations to its descendants.
- A class declared with the
Example: abstract methods and classes
public abstract class Shape // Abstract class: cannot be instantiated
{
public string Name { get; set; }
public Shape(string name)
{
Name = name;
}
public virtual void DisplayInfo() // Concrete virtual method
{
Console.WriteLine($"This is a {Name} shape.");
}
public abstract double GetArea(); // Abstract method: must be overridden by non-abstract derived classes
}
public class Circle : Shape
{
public double Radius { get; set; }
public Circle(string name, double radius) : base(name)
{
Radius = radius;
}
public override double GetArea() => return Math.PI * Radius * Radius;
public override void DisplayInfo() // Can override virtual methods
{
base.DisplayInfo(); // Call base implementation
Console.WriteLine($" Radius: {Radius}");
Console.WriteLine($" Area: {GetArea():F2}");
}
}
public class Rectangle : Shape
{
public double Width { get; set; }
public double Height { get; set; }
public Rectangle(string name, double width, double height) : base(name)
{
Width = width;
Height = height;
}
public override double GetArea() => return Width * Height;
}
// Shape s = new Shape("Generic"); // Compile-time error: Cannot create an instance of the abstract type or interface 'Shape'
Shape circle = new Circle("My Circle", 5);
Shape rectangle = new Rectangle("My Rectangle", 4, 6);
// Polymorphic calls
Console.WriteLine($"Circle Area: {circle.GetArea():F2}"); // Output: Circle Area: 78.54
Console.WriteLine($"Rectangle Area: {rectangle.GetArea():F2}"); // Output: Rectangle Area: 24.00
circle.DisplayInfo();
// Output:
// This is a My Circle shape.
// Radius: 5
// Area: 78.54
abstract methods enforce a contract: any concrete (non-abstract) derived class must provide an implementation for these methods. This ensures that certain essential behaviors are always present in complete (non-abstract) types within the hierarchy.
Method Hiding (new Keyword) vs. Method Overriding
This is a common point of confusion for developers. While override enables polymorphism, the new keyword explicitly hides an inherited member. They behave very differently regarding runtime dispatch.
newKeyword:- Applied to a member in a derived class that has the same name as an inherited member from a base class (whether the base member is
virtualor not). - It tells the compiler, “I know there’s a member with this name in the base class, but I want to declare a new, independent member with this name in this class.”
- Crucially,
newdoes NOT enable runtime polymorphism. The method that gets called depends on the compile-time type of the variable used to make the call, not the runtime type of the object. - C# Language Reference: new Modifier
- Applied to a member in a derived class that has the same name as an inherited member from a base class (whether the base member is
Recommendation: In most scenarios, override is preferred over new for methods that you intend to be specialized in derived classes. Hiding (new) can lead to confusing and error-prone behavior, as the method invoked depends on how the object is referenced. Use new sparingly, typically only when you must introduce a member with the same name as an inherited one but do not intend for it to participate in polymorphism.
What Can Be Virtual and What Cannot
Understanding what types of members can be declared virtual (and thus abstract or override) is crucial:
-
Can be
virtual(andabstract,override):- Instance Methods: The most common use case.
- Instance Properties:
get,set, andinitaccessors can be virtual. You must override both if both exist, or only the one that exists. - Instance Indexers: Similar to properties, their
get_Itemandset_Itemmethods can be virtual. - Instance Events: Their
add_andremove_accessors can be virtual.
-
Cannot be
virtual(orabstract,override):- Static Members: Static methods, fields, properties, indexers, or events cannot be virtual. They belong to the type, not an instance, so there’s no runtime instance to dispatch on.
- Fields: Fields are storage locations, not behaviors. Polymorphism applies to behavior (methods), not data storage directly.
- Constructors: Constructors are special methods for object instantiation. They are not inherited or polymorphic in the same way regular methods are. Their chaining mechanism handles base class initialization (as discussed in 7.2).
- Destructors (Finalizers): These are also special methods. While the CLR manages their execution hierarchy, they cannot be explicitly declared as
virtualoroverridein C# code. - Non-virtual Private Methods: Private methods are not accessible from derived classes, so they cannot be overridden.
7.7. Virtual Dispatch and V-Tables
To truly grasp how runtime polymorphism works, we must delve into the internal mechanics that the .NET CLR employs: Virtual Method Tables (V-Tables). This mechanism is responsible for determining which specific method implementation to call when a virtual method is invoked on a reference to a base type.
Recap: MethodTable (from 7.1)
As established in Section 7.1, every object on the managed heap has an Object Header which contains a pointer to its type’s MethodTable. The MethodTable is the CLR’s internal representation of a type, holding essential metadata and pointers to the type’s methods. For types that use polymorphism, the MethodTable plays a central role in dynamic dispatch.
Virtual Method Tables (V-Tables)
When a class declares virtual methods or overrides virtual (or abstract) methods from its base class, its MethodTable contains, or points to, a Virtual Method Table (V-Table). A V-Table is essentially an array of method pointers. Each entry in this array corresponds to a virtual method that the class implements or inherits.
- Base Class V-Table: The base class defines the initial structure of the V-Table. Each
virtualmethod declared in the base class gets an entry in this table. This entry points to the base class’s implementation of that method. - Derived Class V-Table: When a derived class inherits from a base class:
- It typically gets its own V-Table.
- For any
virtualmethod that the derived classoverrides, the corresponding entry in the derived class’s V-Table will point to the derived class’s implementation. - For
virtualmethods that the derived class does not override, the entry in the derived class’s V-Table will point to the base class’s implementation (or the implementation further up the chain). - This ensures that the V-Table always points to the most-derived implementation for each virtual slot.
Conceptual Diagram of V-Tables and Dispatch:
Let’s consider our Animal and Dog example:
[AppDomain's Loader Heap]
+---------------------------+ +-----------------------------------+
| Animal MethodTable | | Animal V-Table |
+---------------------------+ +-----------------------------------+
| ... | ----> | Slot 0: Ptr to Animal.MakeSound() |
| Ptr to Animal V-Table | | ... (other virtual methods) |
+---------------------------+ +-----------------------------------+
ʌ
|
|
+---------------------------+ +-----------------------------------------+
| Dog MethodTable | | Dog V-Table |
+---------------------------+ +-----------------------------------------+
| ... | ----> | Slot 0: Ptr to Dog.MakeSound() |
| Ptr to Dog V-Table | | ... (other virtual methods from Animal) |
+---------------------------+ +-----------------------------------------+
How Dynamic Dispatch Works (The V-Table Lookup Process)
When you call a virtual method (e.g., animalDogRef.MakeSound() where animalDogRef is of type Animal but points to a Dog object), the CLR performs the following steps at runtime:
- Retrieve Object Header: The CLR gets the object reference (e.g.,
animalDogRef) and looks at the object’s header on the heap. - Get MethodTable Pointer: From the object header, it retrieves the pointer to the object’s actual runtime type’s MethodTable (in this case, the
Dog’s MethodTable). - Access V-Table: From the MethodTable, it obtains the pointer to the V-Table of the
Dogtype. - Lookup Method Slot: The CLR knows (from compile-time analysis of the
Animal.MakeSoundmethod) which specific “slot” or index in the V-Table corresponds to theMakeSoundmethod. - Invoke Method: It then retrieves the method pointer from that V-Table slot (which, for
Dog, points toDog.MakeSound()) and invokes that method.
This process ensures that the correct, most-derived implementation of the virtual method is always called, regardless of the compile-time type of the variable holding the object reference. This is the essence of dynamic dispatch.
Performance Implications of Virtual Calls
While powerful, virtual method calls do incur a small performance overhead compared to non-virtual (direct) calls. This overhead comes from:
- Indirection: A virtual call requires an extra layer of indirection (looking up the MethodTable, then the V-Table, then the method pointer) compared to a direct call, where the JIT compiler can simply inline the method call or jump directly to its known address.
- Reduced Inlining Opportunities: Historically, virtual calls were harder for the JIT compiler to inline (i.e., replace the method call with the method’s body directly at the call site), which is a significant optimization.
However, modern JIT compilers (like RyuJIT in .NET Core/.NET 5+) are highly optimized and can perform various tricks to mitigate this overhead:
- Devirtualization: If the JIT can determine with certainty the exact runtime type of the object at a particular call site (e.g., if the object was just instantiated, or if the type is
sealed), it can “devirtualize” the call, turning it into a direct (non-virtual) call. This is a very common and effective optimization. - Profile-Guided Optimization (PGO): The JIT can gather runtime data and use it to optimize frequently called virtual methods, even if they can’t be fully devirtualized.
- Inlining: Even if not fully devirtualized, modern JITs are much better at inlining methods, reducing call overhead.
Conclusion on Performance: While a theoretical overhead exists, for most applications, the performance difference between virtual and non-virtual calls is negligible and far outweighed by the design benefits of polymorphism (flexibility, extensibility, maintainability). Only in extremely performance-critical inner loops where millions of virtual calls are made should this theoretical overhead be a primary concern.
7.8. The sealed Keyword
The sealed keyword in C# provides a mechanism to control inheritance and method overriding, serving both design and performance purposes.
Using sealed on Classes to Prevent Inheritance
When you declare a class as sealed, you are explicitly stating that no other class can inherit from it. This means the class cannot be a base class for any other class.
- Purpose:
- Design Control: To prevent developers from extending a class in ways that might break its intended behavior or invariants. This ensures the class’s contract remains consistent.
- Security: To prevent malicious code from overriding methods or altering behavior.
- Optimization Hint: As discussed below, it can provide a hint for JIT compiler optimizations.
- Finality: When the design of a class is considered complete and stable, with no foreseen need for further extension.
Example:
public sealed class FinalConfiguration // No class can inherit from FinalConfiguration
{
public string ConnectionString { get; } = "default";
public FinalConfiguration() { }
// No virtual methods needed, as it cannot be extended
}
// public class DerivedConfig : FinalConfiguration {} // Compile-time error: 'DerivedConfig': cannot derive from sealed type 'FinalConfiguration'
Examples of sealed classes in the .NET Framework include many of the primitive types like int, double or System.String. These types are designed to be final, ensuring their behavior is consistent and predictable. While not explicitly marked as sealed, there are also certain special types which classes cannot explicitly inherit from. These are System.Enum, System.ValueType, System.Delegate and System.Array.
Using sealed on override Methods to Prevent Further Overriding
You can also apply the sealed keyword to an override method in a derived class. This prevents any further derived classes (grandchildren, great-grandchildren, etc.) from overriding that specific method again. It effectively “stops the virtual chain” for that particular method at that level of the hierarchy.
- Purpose:
- Control Implementation: To ensure that a specific implementation of a virtual method, provided at a certain level in the inheritance hierarchy, is the final one and cannot be changed by subsequent derived classes.
- Performance (Devirtualization): As with sealed classes, it provides a valuable hint to the JIT compiler.
Example:
class PdfUtility
{
public virtual void Save(string filePath)
{
Console.WriteLine($"Saving PDF to {filePath}.");
}
public virtual void Print()
{
Console.WriteLine("Printing PDF.");
}
}
class SecurePdfUtility : PdfUtility
{
// override and seal the Save method
public sealed override void Save(string filePath)
{
Console.WriteLine("Performing security checks before saving...");
base.Save(filePath);
}
// override Print but leave it open for further overrides
public override void Print()
{
Console.WriteLine("Secure printing of PDF.");
}
}
// Trying to override Save here would result in a compiler error
class CustomSecurePdfUtility : SecurePdfUtility
{
// This is allowed, because Print is not sealed:
public override void Print()
{
Console.WriteLine("Custom secure print logic.");
}
// Error: This would NOT compile:
// public override void Save(string filePath)
// {
// Console.WriteLine("Trying to bypass security...");
// }
}
// Usage and output:
var basicPdf = new PdfUtility();
basicPdf.Save("document.pdf");
// Saving PDF to document.pdf.
basicPdf.Print();
// Printing PDF.
var securePdf = new SecurePdfUtility();
securePdf.Save("secure-document.pdf");
// Performing security checks before saving...
// Saving PDF to secure-document.pdf.
securePdf.Print();
// Secure printing of PDF.
var customSecurePdf = new CustomSecurePdfUtility();
customSecurePdf.Save("custom-secure.pdf");
// Performing security checks before saving...
// Saving PDF to custom-secure.pdf.
customSecurePdf.Print();
// Custom secure print logic.
Impact on Performance (Devirtualization)
The sealed keyword provides a direct hint to the JIT (Just-In-Time) compiler, potentially enabling a significant optimization known as devirtualization.
-
Devirtualization Explained:
- When a method is
virtual, the CLR has to perform a V-Table lookup at runtime to determine which implementation to call (dynamic dispatch). - If a method is declared
sealed override, or if it belongs to asealedclass, the JIT compiler knows with certainty that no other class can provide a different implementation of that method. - In such cases, the JIT can replace the costly virtual call (V-Table lookup) with a direct call to the known method implementation. This eliminates the indirection and allows for better inlining, making the call almost as fast as a non-virtual method call.
- When a method is
-
Benefits:
- Reduced Overhead: Eliminates the V-Table lookup, saving CPU cycles.
- Improved Inlining: Direct calls are easier for the JIT to inline, further reducing call overhead.
-
Trade-offs:
- While beneficial for performance, sealing a class or an
overridemethod reduces the extensibility of your code. You sacrifice future flexibility for current design control and potential minor performance gains. - It’s a design decision that should be made carefully. For many applications, the performance benefit of
sealedis negligible compared to the loss of extensibility. However, in highly performance-critical libraries or specific hot paths, it can be a valuable tool.
- While beneficial for performance, sealing a class or an
Decades of experience teach us that “optimization by default” can lead to premature optimization and restricted design. Use sealed strategically: when the design is intentionally final, when security dictates, or when profiling explicitly identifies a virtual call as a bottleneck in a hot path.
Key Takeaways (Part 2)
- Runtime Polymorphism: Allows treating derived objects as base objects while invoking the specific derived implementation of
virtualmembers at runtime. virtual&override: The core mechanism for polymorphism.virtualin the base class permits overriding;overridein the derived class provides the new implementation.abstractMembers/Classes: Define a contract.abstractmethods have no body and must be overridden by non-abstract derived classes.abstractclasses cannot be instantiated directly.new(Method Hiding): Hides an inherited member. Does not enable polymorphism. The method called depends on the compile-time type of the variable, not the runtime type of the object. Preferoverridefor polymorphic behavior.- Virtualizable Members: Only instance methods, properties, indexers, and events can be
virtual,abstract, oroverride. Static members, fields, and constructors cannot. - V-Tables: The CLR uses Virtual Method Tables (arrays of method pointers) to implement dynamic dispatch. Each object’s MethodTable points to its type’s V-Table, which holds the addresses of the most-derived implementations of all virtual methods.
- Dynamic Dispatch Process: Involves looking up the object’s runtime type’s MethodTable, then its V-Table, and finally the correct method pointer in the V-Table.
- Virtual Call Performance: Incurs a small overhead due to indirection but is often optimized away by the JIT compiler through devirtualization and inlining.
sealedKeyword (Classes): Prevents a class from being inherited. Useful for design finality, security, and optimization hints.sealedKeyword (Methods): Applied to anoverridemethod to prevent further overriding in subsequent derived classes, “stopping the virtual chain.”- Performance Impact of
sealed: Allows the JIT compiler to perform devirtualization, replacing virtual calls with direct calls for minor performance gains, especially in hot paths. Trade-off is reduced extensibility.
7.9. Type Conversions: Implicit, Explicit, Casting, and Safe Type Checks
Type conversion is a fundamental operation in C# (and indeed, any programming language) that allows a value of one type to be transformed into a value of another type. Understanding how C# handles these conversions—both built-in and user-defined—is crucial for writing robust and predictable code.
Implicit Conversions
An implicit conversion is a conversion that the compiler can perform automatically without any special syntax. These conversions are allowed because they are considered “safe”—meaning they never lose data or throw an exception. This typically occurs when converting from a “smaller” or “less specific” type to a “larger” or “more general” type.
- Widening Numeric Conversions:
- Smaller integer types to larger integer types (e.g.,
shorttointtolong,ushorttouinttoulong). - unsigned integer types to larger signed integer types (e.g.,
uinttolong). - Any integer type to a floating-point type (e.g.,
inttofloatordouble). floattodouble.
- Smaller integer types to larger integer types (e.g.,
- Reference Conversions (Upcasting):
- From a derived class type to any of its base class types. This is always safe because a derived class object is a base class object (polymorphism).
- From any class type to
object(sinceobjectis the ultimate base class for all types).
- Boxing Conversions:
- From a value type to
objector to any interface type implemented by the value type. This involves wrapping the value type in a new object on the heap. (Discussed in Chapter 8.1)
- From a value type to
- Nullable Conversions:
- From
TtoT?(whereTis a non-nullable value type).
- From
- C# Language Reference: Implicit numeric conversions
- C# Language Reference: Implicit reference conversions
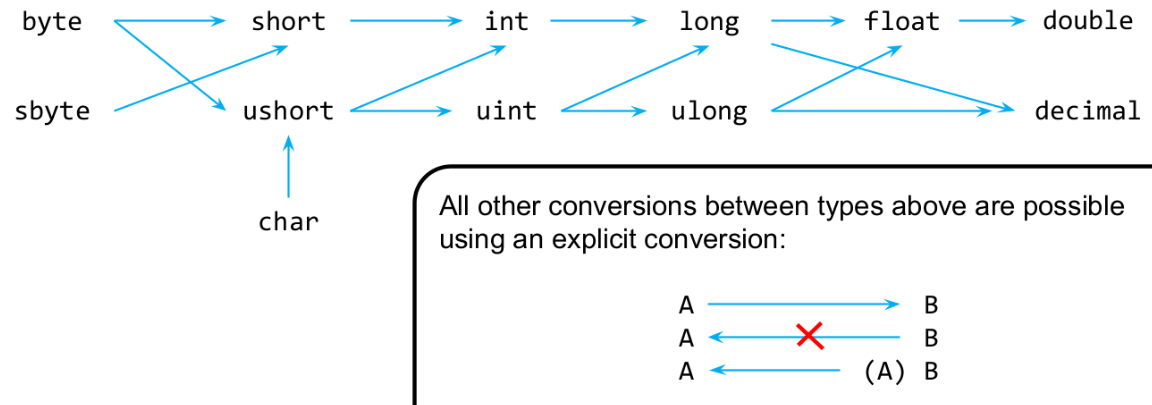
Example of Implicit Conversions:
long bigNumber = 123; // int (literal) to long
double preciseValue = bigNumber; // long to double
class BaseType { }
class DerivedType : BaseType { }
DerivedType derivedInstance = new DerivedType();
BaseType baseRef = derivedInstance; // DerivedType to BaseType (Upcasting)
object obj = 42; // int (value type) to object (reference type) - Boxing
Numeric Type Suffixes
| Literal Example | Type |
|---|---|
42, 0x2A, 0b101010 |
int = Int32 (default integral) |
42L or 42l |
long = Int64 |
42U or 42u |
uint = UInt32 |
42UL, 42ul, 42LU, 42lu |
ulong = UInt64 |
3.14 |
double = Double (default floating-point) |
3.14F or 3.14f |
float = Single |
3.14M or 3.14m |
decimal = Decimal |
Implicit Numeric Conversions and Operations
When you write an expression like:
var result = 100 + 2L;
the compiler applies binary numeric promotions:
- If either operand is of type
decimal:
- if the other is an integral type, it is converted to
decimal. - if the other is
floatordouble, a compile-time error occurs.
- If either operand is of type
double, the other is converted todouble. - Else if either is
float, the other is converted tofloat. - Else if either is
ulong, the other is converted toulong(if possible). - Else if either is
long, the other is converted tolong. - Else both are promoted to
int.
This ensures the result type can accommodate both operands.
Example:
int a = 100;
long b = 2L;
var result = a + b; // result is long
Console.WriteLine(result.GetType()); // System.Int64
byte c = 10;
short d = 20;
var sum = c + d; // result is int (due to promotion), even though both are smaller types
// short sum = c + d; // Compile-time error: cannot implicitly convert int to short
Console.WriteLine(sum.GetType()); // System.Int32
Bitwise Operators and Promotions
Bitwise operations (<<, >>, |, &, ^) also follow promotion rules:
var result = 100 + 2L << 5; // result is long
Console.WriteLine(result.GetType().Name); // System.Int64
Common Numeric Conversion Pitfalls
Division Surprise
int x = 5; int y = 2;
Console.WriteLine(x / y); // Outputs: 2
Console.WriteLine((float)x / y); // Outputs: 2.5
Always cast at least one of the operands to double or float if you expect a fractional result.
Implicit Float Precision Loss
long l = long.MaxValue;
float f = l;
Console.WriteLine(f); // Loses precision
Even though long → float is implicit, it’s dangerous: float cannot accurately represent all long values.
Small Type Promotions
byte a = 1;
sbyte b = -1;
var result = a + b; // becomes int
Be cautious with small types like byte, sbyte, short, and ushort. They are promoted to int in mixed-type arithmetic operations, which can lead to unexpected results if you expect a smaller type.
Mixed Unsigned and Signed Types
uint u = 1;
int i = -1;
var result = u + i; // becomes long
Because uint cannot hold negative values and int cannot hold values larger than uint.MaxValue, mixing signed and unsigned types leads to result widening.
Explicit Conversions (Casting)
An explicit conversion, or cast, requires the developer to explicitly state the target type using parentheses (TargetType). These conversions are necessary when data loss might occur or when the conversion isn’t guaranteed to succeed at runtime. If an explicit conversion fails, it typically throws an InvalidCastException.
- Narrowing Numeric Conversions:
- Larger numeric types to smaller numeric types (e.g.,
longtoint,doubletofloat). Data can be truncated.
- Larger numeric types to smaller numeric types (e.g.,
- Reference Conversions (Downcasting):
- From a base class type to a derived class type. This is only valid if the object referenced by the base type is actually an instance of the derived type (or a type further derived from it). If not, an
InvalidCastExceptionoccurs.
- From a base class type to a derived class type. This is only valid if the object referenced by the base type is actually an instance of the derived type (or a type further derived from it). If not, an
- Unboxing Conversions:
- From
objectto a value type, or from an interface type to a value type that implements it. This requires the boxed object to be of the exact value type specified, otherwise, anInvalidCastExceptionoccurs.
- From
- C# Language Reference: Explicit numeric conversions
- C# Language Reference: Explicit reference conversions
Example of Explicit Conversions:
long largeValue = 1000 + 1L << 31;
int smallValue = (int)largeValue; // Explicit cast required, potential data loss (overflow)
Console.WriteLine($"Large: {largeValue}, Small: {smallValue}");
// Output: Large: 2149631131648, Small: -2147483648
class Base { }
class Derived : Base { }
class Unrelated { }
Base baseObject = new Derived();
Derived derivedObject = (Derived)baseObject; // Valid downcast, baseObject is actually a Derived
Base anotherBaseObject = new Base();
try
{
Derived problematicDerived = (Derived)anotherBaseObject; // InvalidCastException! anotherBaseObject is not a Derived.
}
catch (InvalidCastException ex)
{
Console.WriteLine($"Caught expected exception: {ex.Message}");
}
object objInt = 100;
int unboxedInt = (int)objInt; // Valid unboxing
try
{
long unboxedLong = (long)objInt; // InvalidCastException! objInt holds an int, not a long.
}
catch (InvalidCastException ex)
{
Console.WriteLine($"Caught expected exception: {ex.Message}");
}
Safe Type Checks: is and as Keywords
Because explicit casting of reference types (especially downcasting or unboxing) can lead to runtime InvalidCastExceptions, C# provides safer alternatives: the is and as operators.
The is Keyword (Type Compatibility Check)
The is operator checks if an expression’s runtime type is compatible with a given type. It returns true if the conversion would succeed, and false otherwise, without throwing an exception.
Since C# 7.0, is has been significantly enhanced with pattern matching, allowing you to combine the type check with a variable declaration for the converted type. C# 8.0 and 9.0 further enhanced is with advanced patterns, which we will cover in Chapter 15.
Example of is:
object someObject = "Hello, C#";
// Traditional 'is'
if (someObject is null) { ... } // null check
if (someObject is string) {
string s = (string)someObject; // Still requires a cast here
... // work with s
}
// 'is' with declaration pattern (C# 7.0+)
if (someObject is string s2) { // s2 is only in scope if the condition is true
Console.WriteLine($"'is' with pattern: It's a string: {s2.Length}");
}
if (someObject is int i) { // Fails, someObject is not an int
Console.WriteLine($"'is' with pattern: It's an int: {i}");
}
else {
Console.WriteLine("someObject is not an int.");
}
Base baseRef = new Derived();
if (baseRef is Derived d) { ... }
public class Base { public string GetBaseInfo() => "Base Info"; }
public class Derived : Base { public string GetDerivedInfo() => "Derived Info"; }
// property pattern matching (C# 8.0+)
if (x is Person { Name: "Alice", Age: > 30 }) {
Console.WriteLine("Found a person named Alice older than 30.");
}
// not, and, or patterns (C# 9.0+)
if (x is not null) { ... }
if (x is not int) { ... }
if (x is >= 0 and <= 100) {
Console.WriteLine("In range 0–100");
}
if (x is "yes" or "y" or "ok") {
Console.WriteLine("Confirmed!");
}
The is operator is ideal when you need to conditionally execute code based on an object’s runtime type without risking an exception, especially when using pattern matching to cast and assign in a single, fluent expression.
Limitations of is: Consider the following example:
int x = 42;
if (x is string s) { // Compile-time error: Cannot convert from 'int' to 'string'
Console.WriteLine($"x is a string: {s}");
}
The full algorithm used is explained in the C# Language Specification.
Note that the is operator does not consider user defined conversions.
The as Keyword (Safe Casting to null on Failure)
The as operator attempts to perform a reference conversion or nullable conversion. If the conversion is successful, it returns the converted object; otherwise, it returns null. This is a crucial distinction from a direct explicit cast, which throws an InvalidCastException. The expression x = E as T is functionally equivalent to x = E is T t ? t : null, but more efficient.
Example of as:
object objA = "Hello";
string s = objA as string; // s will be "Hello"
Console.WriteLine($"s is: {s ?? "null"}");
object objB = 123;
string s2 = objB as string; // s2 will be null, no exception thrown
Console.WriteLine($"s2 is: {s2 ?? "null"}");
Base baseObj = new Base();
Derived d = baseObj as Derived; // d will be null, no exception
Console.WriteLine($"d is (null): {d ?? null}");
Derived d2 = new Derived();
Base bRef = d2;
Derived d3 = bRef as Derived; // d3 will be d2
Console.WriteLine($"d3 is: {d3.GetDerivedInfo()}");
// int? can be used with 'as' since C# 8
int normalInt = 10;
object objC = normalInt;
int? resultInt = objC as int?; // resultInt will be 10
Console.WriteLine($"Result int?: {resultInt.Value}");
objC = null;
resultInt = objC as int?; // resultInt will be null
Console.WriteLine($"Result int? (null): {resultInt}");
// int? nullableInt = 5;
// string s3 = nullableInt as string; // Compile-time error, similar to the `is` operator
The as operator is useful when you anticipate that a conversion might fail frequently and you want to handle the null result gracefully rather than catching exceptions. It’s often followed by a null check.
Choosing the Right Conversion Method
| Method | When to Use | Pros | Cons |
|---|---|---|---|
| Implicit Cast | For safe, non-data-loss conversions (compiler handles automatically). | Cleanest syntax, no explicit code needed. | Limited to safe conversions. |
| Explicit Cast | When you are certain the conversion will succeed and want a direct value. | Direct conversion, no intermediate null check. |
Throws InvalidCastException on failure, leading to runtime errors. |
is operator |
To check type compatibility before casting, especially with patterns. | Safe, no exceptions. Pattern matching provides clean, concise code. | Requires a separate cast (if not using patterns) or conditional logic. |
as operator |
To attempt a conversion that might fail, when you prefer null over an exception. |
Safe, returns null on failure. More efficient than try-catch for casting. |
Only for reference types and nullable value types. Requires null check. |
In modern C#, the is pattern matching operator is often preferred for checking and casting reference types in a single expression, providing both safety and conciseness. Direct explicit casts should be used with caution, primarily when the type relationship is guaranteed (e.g., immediately after an is check, or when you are creating the object).
7.10. Operator Overloading and User-Defined Conversion Operators
Beyond standard method overloading, C# allows you to define custom behavior for operators and type conversions for your user-defined types. This feature provides a more natural and intuitive syntax when working with custom data structures that mimic mathematical or logical concepts.
Operator Overloading (operator op)
Operator overloading allows you to redefine or extend the meaning of a C# operator (like +, -, *, ==, > etc.) when applied to instances of your custom classes or structs. This is done by declaring special public static methods using the operator keyword followed by the operator symbol.
Key Principles:
public static: All operator overloads must be declared aspublic static. They operate on instances of your type (or related types) passed as arguments, not on a specific instance of the class they are declared within.- Operand Requirement: At least one operand of a binary operator or the single operand of a unary operator must be of the type in which the operator is declared.
- Paired Operators: Some operators must be overloaded in pairs:
==must be overloaded with!=.<must be overloaded with>.<=must be overloaded with>=.
- Equality and Hashing: If you overload
==and!=, you should almost alwaysoverrideobject.Equals()andobject.GetHashCode()to ensure consistency and proper behavior in collections (likeHashSetorDictionary). - Restricted Operators: You cannot overload
&&,||,?.,[](indexer is separate),new,typeof,as,is,?:,=,checked,unchecked.
Example: Overloading the + and == operators for a Vector struct
public struct Vector
{
public double X { get; }
public double Y { get; }
public Vector(double x, double y) => (X, Y) = (x, y);
// Overload the binary '+' operator
public static Vector operator +(Vector v1, Vector v2)
{
return new Vector(v1.X + v2.X, v1.Y + v2.Y);
}
// Overload the unary '-' operator
public static Vector operator -(Vector v)
{
return new Vector(-v.X, -v.Y);
}
// Overload the binary '==' operator
public static bool operator ==(Vector v1, Vector v2)
{
return v1.X == v2.X && v1.Y == v2.Y;
}
// Must overload '!=' if '==' is overloaded
public static bool operator !=(Vector v1, Vector v2)
{
return !(v1 == v2);
}
// It is good practice to override Equals and GetHashCode when overloading == and !=
public override bool Equals(object? obj)
{
return obj is Vector other && this == other; // Uses overloaded ==
}
public override int GetHashCode()
{
return HashCode.Combine(X, Y); // Combines hash codes of X and Y
}
public override string ToString() => $"({X}, {Y})";
}
// Usage
Vector v1 = new(1, 2);
Vector v2 = new(3, 4);
Vector v3 = v1 + v2; // Calls Vector.operator+(v1, v2)
Console.WriteLine($"v1 + v2 = {v3}"); // Output: (4, 6)
Vector v4 = -v1; // Calls Vector.operator-(v1)
Console.WriteLine($"-v1 = {v4}"); // Output: (-1, -2)
Console.WriteLine($"v1 == new Vector(1, 2): {v1 == new Vector(1, 2)}"); // Output: True
Console.WriteLine($"v1 == v2: {v1 == v2}"); // Output: False
IL Representation (op_ Methods)
Behind the scenes, the C# compiler translates operator overloads into special static methods in the generated Intermediate Language (IL). These methods are prefixed with op_. For example:
operator +becomesop_Additionoperator -(unary) becomesop_UnaryNegationoperator ==becomesop_Equalityoperator >becomesop_GreaterThan
When you write v1 + v2 in C#, the compiler finds the appropriate op_Addition method and emits IL that calls it, making it seem like the operator is built-in. This is a form of syntactic sugar.
User-Defined Conversion Operators
Just as you can overload operators, you can also define custom type conversions between your type and other types using the implicit and explicit keywords in conjunction with operator.
implicit Conversion Operators
An implicit conversion operator defines a conversion that the compiler can perform automatically. Like built-in implicit conversions, these should only be used when the conversion is guaranteed to be safe and without data loss or unexpected behavior.
Syntax: public static implicit operator TargetType(SourceType instance)
Example: Implicit conversion from Miles to Kilometers (assuming 1 mile = 1.60934 km)
public struct Miles
{
public double Value { get; }
public Miles(double value) => Value = value;
// Implicitly convert Miles to Kilometers
public static implicit operator Kilometers(Miles miles)
{
return new Kilometers(miles.Value * 1.60934);
}
}
public struct Kilometers
{
public double Value { get; }
public Kilometers(double value) => Value = value;
public override string ToString() => $"{Value:F2} km";
}
// Usage
Miles distanceInMiles = new(100);
Kilometers distanceInKm = distanceInMiles; // Implicit conversion
Console.WriteLine($"100 miles is {distanceInKm}"); // Output: 100 miles is 160.93 km
The compiler automatically injects the call to op_Implicit (the IL name for implicit conversion operators).
explicit Conversion Operators
An explicit conversion operator defines a conversion that requires a cast. These should be used when data loss or a potential exception might occur, or when the conversion is not intuitively obvious.
Syntax: public static explicit operator TargetType(SourceType instance)
Example: Explicit conversion from Kilograms to Pounds (assuming 1 kg = 2.20462 lbs), with potential for less precision.
public struct Kilograms
{
public double Value { get; }
public Kilograms(double value) => Value = value;
public override string ToString() => $"{Value:F2} kg";
}
public struct Pounds
{
public double Value { get; }
public Pounds(double value) => Value = value;
// Explicitly convert Kilograms to Pounds
public static explicit operator Pounds(Kilograms kg)
{
return new Pounds(kg.Value * 2.20462);
}
// Explicitly convert Pounds to int (potential data loss)
public static explicit operator int(Pounds pounds)
{
return (int)Math.Round(pounds.Value); // Rounds to nearest integer
}
}
// Usage
Kilograms weightKg = new(50);
Pounds weightLbs = (Pounds)weightKg; // Explicit cast required
Console.WriteLine($"50 kg is {weightLbs.Value:F2} lbs"); // Output: 50 kg is 110.23 lbs
int roundedWeight = (int)weightLbs; // Explicit cast required, potential data loss (decimal -> int)
Console.WriteLine($"Rounded weight in lbs (int): {roundedWeight}"); // Output: Rounded weight in lbs (int): 110
Explicit conversion operators are translated into op_Explicit methods in IL.
Design Considerations for Overloading Operators and Conversions
- Intuitiveness: Only overload operators when their meaning is clear and intuitive for your type. Overusing or misusing operator overloading can lead to code that is difficult to read, understand, and debug. For example, using
+to subtract would be highly confusing. - Consistency: Maintain consistency with built-in operators. If
==means “equality,” ensure!=means “inequality.” If+is commutative for built-in types, it probably should be for yours. - Immutability: Operator overloads often work best with immutable types (like our
Vectorstruct). If the operation creates a new instance instead of modifying the existing ones, it aligns well with functional programming principles and avoids side effects. - Clarity over Cleverness: Sometimes, a well-named method (e.g.,
vector1.Add(vector2)) is clearer than an overloaded operator, especially for complex operations. - Equality Best Practices: For
==and!=overloads, always overrideEquals(object)andGetHashCode(). ForIEquatable<T>, implement it. This ensures your type behaves correctly in all .NET contexts (e.g., hash-based collections, LINQDistinct()).
7.11. Parameter Modifiers: ref, out, in, and ref Variables
In C#, arguments are typically passed to methods by value. This means that when you pass a variable to a method, a copy of that variable’s value is made and given to the method’s parameter. For value types (like int, struct), this is a direct copy of the data. For reference types (like string, List<T>, custom classes), it’s a copy of the reference (the memory address) to the object on the heap. While both the original variable and the parameter’s variable point to the same object, they are distinct references themselves.
However, C# provides several parameter modifiers (ref, out, in) and concepts (ref locals, ref returns) that allow you to change this default behavior, enabling arguments to be passed by reference or to declare variables that are aliases to existing storage locations. This opens up powerful patterns for efficiency, multi-value returns, and more.
ref Parameters: Modifying the Original Variable
The ref keyword allows you to pass arguments to a method by reference. When an argument is passed by ref, the parameter in the method does not create a new storage location; instead, it becomes an alias for the original argument variable in the calling code. Any changes made to the parameter inside the method will directly affect the original variable.
Semantics:
- The argument passed to a
refparameter must be initialized before being passed to the method. The method can then read its current value. - The
refkeyword must be used both in the method’s declaration and at the call site.
Use Cases and Examples:
1. Modifying Value Types
For value types, ref allows a method to directly change the value of the original variable, something not possible with pass-by-value.
void Increment(ref int value)
{
value++; // Modifies the original 'myNumber'
}
// Usage:
int myNumber = 5;
Console.WriteLine($"Before Increment: {myNumber}"); // Output: 5
Increment(ref myNumber);
Console.WriteLine($"After Increment: {myNumber}"); // Output: 6
This is extremely powerful for performance-sensitive code, as it avoids copying large structs. Refer to chapters 8.4 and 8.5 for more details.
2. Modifying Reference Types (the Reference Itself)
This is a crucial distinction. When a class instance is passed by ref, it means the method can actually change which object the caller’s variable points to. This is distinct from regular pass-by-value for reference types, where the method can modify the contents of the object but cannot make the caller’s variable point to a different object.
static void ReplaceWithoutRef(List<int> lst) {
lst = new List<int> { 4, 5, 6 };
}
static void ReplaceWithRef(ref List<int> lst) {
lst = new List<int> { 7, 8, 9 };
}
List<int> list = new List<int> { 1, 2, 3 };
List<int> originalCopy = list; // make a copy of the reference
ReplaceWithoutRef(list);
Console.WriteLine(ReferenceEquals(list, originalCopy)); // True
// modifying 'list' now would also modify 'originalCopy'
ReplaceWithRef(ref list);
Console.WriteLine(ReferenceEquals(list, originalCopy)); // False
// modifying 'list' now would no longer modify 'originalCopy'
// because 'list' now points to a completely new List<int> instance
This is a powerful, though less common, use case for ref with reference types, as it means the method can “re-parent” the caller’s variable to a new instance.
out Parameters: Returning Multiple Values
The out keyword is similar to ref in that it passes arguments by reference, but its primary purpose is to allow a method to return multiple values. It signifies that the parameter will be assigned a value by the method before the method returns.
Semantics:
- The argument passed to an
outparameter does not need to be initialized before being passed. Its previous value is ignored. - The method must assign a value to every
outparameter before it returns. - The
outkeyword must be used both in the method’s declaration and at the call site. - Since C# 7.0, you can declare
outvariables inline at the call site (int.TryParse("123", out int result)).
Use Cases and Examples:
1. Returning Multiple Calculated Values
A method can assign values to multiple out parameters, effectively returning more than one piece of data.
void Divide(int numerator, int denominator, out int quotient, out int remainder)
{
quotient = numerator / denominator;
remainder = numerator % denominator;
}
// Usage:
int num = 10;
int den = 3;
Divide(num, den, out int q, out int r); // Inline declaration of 'out' variables (C# 7.0+)
Console.WriteLine($"{num} divided by {den} is {q} with remainder {r}");
// Output: 10 divided by 3 is 3 with remainder 1
2. The TryParse Pattern
A very common and idiomatic use of out is the TryParse pattern, where a method attempts an operation and indicates success/failure with a bool return, providing the result through an out parameter if successful. This avoids exceptions for common failure cases.
You will encounter this pattern frequently in .NET, such as with int.TryParse, DateTime.TryParse, etc.
// Example of a custom TryParse-like method
bool TryParseCoordinates(string input, out int x, out int y)
{
x = 0; // Must assign before return
y = 0; // Must assign before return
string[] parts = input.Split(',');
if (parts.Length != 2) return false;
// use int.TryParse to parse each part
if (!int.TryParse(parts[0].Trim(), out x)) return false;
if (!int.TryParse(parts[1].Trim(), out y)) return false;
return true;
}
// Usage:
string input1 = "10, 20";
if (TryParseCoordinates(input1, out int coordX1, out int coordY1)) {
Console.WriteLine($"Parsed coordinates from '{input1}': ({coordX1}, {coordY1})"); // Output: (10, 20)
}
else {
Console.WriteLine($"Failed to parse '{input1}'");
}
string input2 = "abc, def";
if (TryParseCoordinates(input2, out int coordX2, out int coordY2)) {
Console.WriteLine($"Parsed coordinates from '{input2}': ({coordX2}, {coordY2})");
}
else {
Console.WriteLine($"Failed to parse '{input2}'"); // Output: Failed to parse 'abc, def'
}
// Output:
// Parsed coordinates from '10, 20': (10, 20)
// Failed to parse 'abc, def'
in Parameters: Read-Only References for Performance
The in keyword (introduced in C# 7.2) is used to pass arguments by reference, but strictly for read-only access. It’s primarily designed for performance optimization when passing large structs, allowing you to avoid expensive copying without risking accidental modification.
Semantics:
- The argument passed to an
inparameter must be initialized before being passed. - The method cannot modify the
inparameter directly. Attempting to assign to it or call a non-readonlymethod on astructinparameter will result in a compile-time error. - The
inkeyword must be used in the method’s declaration. At the call site,inis optional but recommended for clarity.
Use Case: Avoiding Copies for Large Structs
When a method takes a large struct as a parameter by value, a full copy of that struct is made on the stack. For very large structs, this copying can introduce measurable performance overhead. in parameters avoid this copy by passing a reference, while guaranteeing read-only access.
// Define a large struct (conceptual size for demonstration)
struct Point3D(double x, double y, double z)
{
// Imagine this struct has many fields, making it "large"
public double X = x, Y = y, Z = z;
}
// Method that processes a Point3D without copying it
double CalculateDistance(in Point3D p1, in Point3D p2)
{
// p1.X = 10.0; // COMPILE-TIME ERROR: Cannot modify 'in' parameter
double dx = p1.X - p2.X;
double dy = p1.Y - p2.Y;
double dz = p1.Z - p2.Z;
return Math.Sqrt(dx * dx + dy * dy + dz * dz);
}
// Usage:
Point3D origin = new Point3D(0, 0, 0);
Point3D target = new Point3D(3, 4, 0);
// 'in' at call site is optional, but adds clarity
double distance = CalculateDistance(in origin, in target);
Console.WriteLine($"Distance: {distance}"); // Output: 5
// If Point3D was passed by value, two copies would be made.
// With 'in', only references are passed, saving copy operations.
For class types, in parameters are less impactful because class instances are already passed by reference (a copy of the reference, but not the object itself). However, in on a class reference would still prevent you from reassigning the parameter to a different object within the method, though it would allow modifying the object’s members. Achieving basically the same behavior as if the in modifier wad omitted. Long story short: don’t use in with class parameters unless you want to prevent reassignment of the parameter itself.
ref Locals and ref Return Types: Alias to Storage
Beyond method parameters, the ref keyword can also be used to declare local variables that are aliases to existing storage locations, and for method return types, allowing a method to return a direct reference to data. These features, introduced in C# 7.0, enable highly efficient manipulation of data without copying, particularly relevant for low-level performance scenarios often involving Span<T> (covered in Chapter 8).
1. ref Locals
A ref local variable is an alias to another variable. It doesn’t create new storage for its own value; instead, it directly refers to the memory location of the aliased variable.
int[] numbers = { 10, 20, 30, 40, 50 };
// 'firstElement' is a ref local that aliases 'numbers[0]'
ref int firstElement = ref numbers[0];
Console.WriteLine($"Original numbers[0]: {numbers[0]}"); // Output: 10
firstElement = 100; // Modifies numbers[0] directly via the alias
Console.WriteLine($"Modified numbers[0]: {numbers[0]}"); // Output: 100
This is extremely useful for modifying elements within collections or arrays without incurring indexing overhead repeatedly or making copies.
2. ref Return Types
A method declared with a ref return type returns a reference to a variable, rather than a copy of its value. This allows the caller to directly modify the variable that the method “returned” a reference to.
// Example: A method to get a reference to an element in an array
static ref string GetStringRef(string[] array, int index)
{
if (index < 0 || index >= array.Length)
{
throw new IndexOutOfRangeException("Index is out of bounds.");
}
return ref array[index]; // Returns a reference to the array element
}
// Usage:
string[] names = { "Alice", "Bob", "Charlie" };
// 'targetName' is a ref local that aliases the result of GetStringRef
ref string targetName = ref GetStringRef(names, 1);
Console.WriteLine($"Original names[1]: {names[1]}"); // Output: Bob
targetName = "Bobby"; // Modifies names[1] directly
Console.WriteLine($"targetName after modification: {targetName}"); // Output: Bobby
Important Safety Constraint: Lifetimes
A critical rule for ref locals and ref return types is that the ref cannot outlive the storage it refers to. The C# compiler performs sophisticated static analysis to ensure this “ref safety.” For example:
- You cannot return a
refto a local variable declared within the method (which would be destroyed upon method exit). - You cannot assign a
reflocal that points to stack-allocated memory to a field of aclass(which lives on the heap and could outlive the stack memory).
While this rule is vital, the detailed nuances of lifetime analysis and the scoped keyword (used to explicitly restrict lifetimes for ref variables) are complex topics primarily used with ref structs and are thus covered in depth in Chapter 8.5.
Comparison and When to Use Which
| Modifier / Concept | Direction | Value Type Behavior | Reference Type Behavior | Primary Use Case |
|---|---|---|---|---|
| Default | Input | Copy of value | Copy of reference (same object, different reference variable) | Standard parameter passing |
ref Parameter |
Input/Output | Pass by reference (modifies original) | Pass by reference (can change which object caller’s variable points to) | Modifying original variable (value or reference) |
out Parameter |
Output | Pass by reference (method assigns) | Pass by reference (method assigns which object caller’s variable points to) | Returning multiple values, TryParse pattern |
in Parameter |
Input (Read-only) | Pass by read-only reference (avoids copy) | Pass by read-only reference (cannot change which object caller’s variable points to) | Performance for large structs, enforcing immutability |
ref Local |
Alias | Alias to existing variable | Alias to existing variable | Direct, efficient access to storage locations |
ref Return |
Alias (Output) | Alias to existing variable | Alias to existing variable | Exposing references for direct modification |
When to Use:
ref: Use when you need a method to modify the actual variable passed in, whether it’s changing a primitive’s value or making a class variable point to a different object. Exercise caution, as this can make code harder to reason about due to side effects.out: The standard pattern for returning multiple values from a method, especially inTryParsescenarios where an operation might fail. It clearly communicates intent: this parameter is for output.in: Primarily for performance optimization when dealing with very largestructs to avoid copying. It provides strong immutability guarantees. Forclasses, its impact is less about performance and more about preventing reassignment of the reference inside the method.refLocals andrefReturns: For highly optimized scenarios where avoiding copies is paramount, or when you need to directly manipulate an element within a collection/array without creating a temporary copy (e.g., in low-level data processing pipelines). Always be mindful of lifetime rules.
7.12. Method Resolution Deep Dive: Overloading and Overload Resolution
Method resolution is the process by which the C# compiler determines which specific method to invoke when multiple methods share the same name. This process becomes complex when dealing with method overloading and involves a sophisticated algorithm called overload resolution. This is a compile-time activity, though its effects are observed at runtime.
Method Overloading
Method overloading allows a class (or a hierarchy of classes) to have multiple methods with the same name, provided they have different signatures. A method’s signature consists of its name and the number, order, and types of its parameters. The return type and params modifier are not part of the signature for distinguishing overloads, but ref, out, and in modifiers are.
Example of Overloading:
public class Calculator
{
public int Add(int a, int b) => a + b;
public double Add(double a, double b) => a + b;
public int Add(int a, int b, int c) => a + b + c;
public string Add(string s1, string s2) => s1 + s2;
public void Add(int a, out int result) { result = a + 10; } // 'out' is part of signature
}
Calculator calc = new();
Console.WriteLine(calc.Add(5, 3)); // Calls Add(int, int) -> 8
Console.WriteLine(calc.Add(5.5, 3.2)); // Calls Add(double, double) -> 8.7
Console.WriteLine(calc.Add(1, 2, 3)); // Calls Add(int, int, int) -> 6
Console.WriteLine(calc.Add("Hello", "World")); // Calls Add(string, string) -> HelloWorld
int r;
calc.Add(20, out r);
Console.WriteLine($"Result from Add(int, out int): {r}"); // 30
Overloading enhances readability and usability by allowing conceptually similar operations to share a common name, abstracting away the underlying type differences for the caller.
Overload Resolution Process
When a method is called, the C# compiler (specifically, the part responsible for semantic analysis) goes through a multi-step process to determine which of the overloaded methods is the “best” match for the given arguments. This is a highly complex algorithm detailed in the C# Language Specification. Here’s a simplified breakdown:
-
Identify Candidate Methods:
- Find all accessible methods (both
virtualand non-virtual) with the same name as the invoked method in the context of the compile time type. If no suitable methods are found, move in the inheritance hierarchy to base classes. - Methods with different numbers of parameters are generally excluded unless
paramsarrays are involved.
- Find all accessible methods (both
-
Determine Applicable Methods:
- From the candidates, filter out methods where the provided arguments cannot be implicitly converted to the method’s parameters.
- This step considers all implicit conversions, including built-in numeric conversions, reference conversions, and user-defined implicit conversions (discussed in 7.10). Only one user defined implicit conversion is allowed per method parameter.
- If no applicable methods are found and we have reached the end of the inheritance hierarchy, a compile-time error occurs.
-
Select the Best Method” (The Core of Resolution):
- If multiple applicable methods exist in the current context, the compiler must determine the “most specific” or “best” one. This involves a complex set of rules comparing pairs of applicable methods. A method $M_1$ is considered “better” than $M_2$ if:
- $M_1$ is more specific regarding parameter types (e.g., requires fewer or “smaller” implicit conversions).
- $M_1$ is a non-generic method and $M_2$ is generic (non-generic is preferred if arguments match equally well).
- $M_1$ is a more specific generic method when comparing two generic methods (e.g.,
Foo<int>(T)is better thanFoo<object>(T)ifintis passed). - $M_1$ uses
in,out, orrefparameters more specifically matching the call site arguments. - Special rules apply to
paramsarrays: a non-paramsoverload is preferred if arguments match exactly without needing theparamsexpansion.
- If a unique “best” method cannot be determined (i.e., no single method is strictly “better” than all others), a compile-time ambiguity error occurs.
- If multiple applicable methods exist in the current context, the compiler must determine the “most specific” or “best” one. This involves a complex set of rules comparing pairs of applicable methods. A method $M_1$ is considered “better” than $M_2$ if:
-
Call the Selected Method:
- if the selected method is non-
virtual, the call is resolved statically at compile time. The specific method which was found will be called. - if the selected method is
virtual, the runtime will determine the actual method to invoke based on the object’s runtime type (dynamic dispatch). The most recent override in the inheritance hierarchy will be called.
- if the selected method is non-
Simple Example of Overload Resolution Logic
public class Processor
{
public void Process(int value) => Console.WriteLine($"Processing int: {value}");
public void Process(double value) => Console.WriteLine($"Processing double: {value}");
public void Process(object value) => Console.WriteLine($"Processing object: {value}");
public void Process(string value) => Console.WriteLine($"Processing string: {value}");
public void Handle(int x, int y) => Console.WriteLine($"Handling two ints: {x}, {y}");
public void Handle(long x, long y) => Console.WriteLine($"Handling two longs: {x}, {y}");
public void Handle(int x, params int[] values) => Console.WriteLine($"Handling int with params: {x}, {string.Join(",", values)}");
}
Processor p = new();
p.Process(10); // Calls Process(int) - exact match.
p.Process(10.0f); // Calls Process(double) - float implicitly converts to double, but not int.
p.Process(10L); // Calls Process(double) - long implicitly converts to double. Process(int) would require explicit cast.
// Debate: Why not Process(object)? Because long -> double is a better (more specific) conversion than long -> object.
p.Process("test"); // Calls Process(string) - exact match.
p.Process(DateTime.Now); // Calls Process(object) - DateTime can only implicitly convert to object.
p.Handle(1, 2); // Calls Handle(int x, int y) - exact match for two ints.
p.Handle(1L, 2L); // Calls Handle(long x, long y) - exact match for two longs.
p.Handle(5); // Calls Handle(int x, params int[] values) - best match when only one int is provided.
Example: Runtime Type vs Compile-Time Type
class A {
public void f(int x) => Console.WriteLine("A.f(int)");
public void f(long x, long y) => Console.WriteLine("A.f(long, long)");
public void f(int x, long y) => Console.WriteLine("A.f(int, long)");
}
class B : A {
public new void f(int x) => Console.WriteLine("B.f(int)");
}
class C : B {
public void f(int x, int y) => Console.WriteLine("C.f(int, int)");
}
B b = new C();
b.f(10, 20); // Output: "A.f(int, long)"
We have called b.f(int, int). The compile time type of b is B, so the compiler will:
- consider methods in
B:B.f(int)━ wrong number of parameters
- consider methods in
A:A.f(int)━ wrong number of parametersA.f(long, long)━intcan be implicitly converted tolong–> candidateA.f(int, long)━intcan be implicitly converted tolong–> candidate
- select the best method from the candidates
A.f(int, long)━ less implicit conversions thanA.f(long, long)
Note that even though the runtime type of b is C and C has a direct method f(int, int), it is not considered because the compile-time type of b is B. The compiler only considers methods that are accessible in the context of the compile-time type.
Example: Better Candidate in Base Class Ignored
class A {
public virtual void f(int x) => Console.WriteLine("A.f(int)");
public void f(double x) => Console.WriteLine("A.f(double)");
}
class B : A {
public void f(long x) => Console.WriteLine("B.f(long)");
}
class C : B {
public override void f(int x) => Console.WriteLine("C.f(int)");
}
B b = new B();
b.f(1); // Output: "B.f(long)"
We have called B.f(int). The compile time type of b is B, so the compiler will:
- consider methods in
B:B.f(long)━intcan be implicitly converted tolong–> candidate
- there is only 1 candidate, so it is selected
Note that even though the base type A has a better method A.f(int) and the runtime type of b (C) overrides this method C.f(int), it is not chosen because a valid candidate was found in the compile-time type B.
Example: Generic vs Non-Generic Methods
class Processor
{
public void Process<T>(T value) => Console.WriteLine($"Processing generic: {value}");
public void Process(int value) => Console.WriteLine($"Processing int: {value}");
}
Processor p = new Processor();
p.Process(10); // Calls Process(int) - exact match.
p.Process(10.5); // Calls Process<T>(T) - generic method, no exact match for double.
p.Process("Hello"); // Calls Process<T>(T) - generic method, no exact match for string.
Example: Ambiguous Method Calls
abstract class Money {
public decimal Amount { get; set; }
}
class EUR : Money { }
class USD : Money { }
class CZK : Money {
// implicit conversion CzechCrown -> Euro
public static implicit operator EUR(CZK czk) => new EUR() { Amount = czk.Amount / 24 };
// implicit conversion CzechCrown -> Dollar
public static implicit operator USD(CZK czk) => new USD() { Amount = czk.Amount / 20 };
}
class CurrencyProcessor {
public static void Process(EUR eur) => Console.WriteLine($"Processing {eur.Amount} Euro");
public static void Process(USD usd) => Console.WriteLine($"Processing {usd.Amount} Dollars");
}
CZK money = new CZK() { Amount = 240 };
CurrencyProcessor.Process(money); // Compile-time error: Ambiguous call to Process(EUR) and Process(USD)
Both methods Process(EUR) and Process(USD) are equally good due to implicit conversions from CZK. The compiler cannot determine which method to call, resulting in a compile-time ambiguity error.
Common Pitfalls and Considerations:
- Boxing: Overloads taking
objectparameters are less specific than overloads taking concrete value types. Anintargument will preferProcess(int)overProcess(object)becauseinttointis an exact match, whileinttoobjectrequires boxing. dynamicKeyword: Ifdynamicis used, overload resolution is deferred to runtime by the DLR (Dynamic Language Runtime). This can lead to runtime errors if no suitable overload is found, rather than compile-time errors.- Default Values and Named Arguments: These features (C# 4.0+) modify how arguments are matched to parameters before overload resolution, but the core resolution logic remains the same once the effective argument list is determined.
Mastering overload resolution involves understanding the hierarchy of implicit conversions and the compiler’s preference rules. When in doubt, explicitly cast arguments to guide the compiler, or rename methods to avoid ambiguity.
7.13. Nested Types and Local Functions
C# allows for fine-grained control over code organization and encapsulation through nested types and local functions. These features offer powerful ways to group related functionality and manage scope effectively.
Nested Types
A nested type is a class, struct, interface, or enum declared within another class, struct, or interface. The type that contains the nested type is called the enclosing type or outer type.
Key Characteristics and Use Cases:
-
Encapsulation: Nested types are often used to encapsulate helper classes or data structures that are logically related to, and used exclusively by, the enclosing type. This reduces pollution of the containing namespace.
public class ReportGenerator { // A private nested class used only by ReportGenerator private class ReportData { public string Title { get; set; } public List<string> Sections { get; } = new(); public void AddSection(string section) => Sections.Add(section); } public string GenerateDailyReport() { var data = new ReportData { Title = "Daily Activity Report" }; data.AddSection("Task A completed."); data.AddSection("Task B pending."); return $"--- {data.Title} ---\n" + string.Join("\n", data.Sections); } } // ReportGenerator.ReportData is not directly accessible here // var invalidData = new ReportGenerator.ReportData(); // Compile-time error -
Access to Enclosing Type Members: Nested types have a unique privilege: they can access all members (including
privateandprotected) of their enclosing type, provided they are accessing them through an instance of the outer type. This is a crucial distinction. A non-static nested class can also access the outer instance members directly if an instance of the outer class is implied (e.g., when a nested class’s instance is created by the outer class).public class OuterClass { private int _privateOuterField = 10; public string PublicOuterProp { get; set; } = "Hello"; public class NestedClass { public void DisplayOuterInfo(OuterClass outer) { // Can access private members of the outer class instance Console.WriteLine($"Nested: Private outer field: {outer._privateOuterField}"); Console.WriteLine($"Nested: Public outer prop: {outer.PublicOuterProp}"); } } public void CreateAndUseNested() { var nested = new NestedClass(); nested.DisplayOuterInfo(this); // Pass 'this' instance } } // Usage OuterClass outer = new(); outer.CreateAndUseNested(); // Output: // Nested: Private outer field: 10 // Nested: Public outer prop: Hello -
Accessibility: The accessibility of a nested type is determined by its declared access modifier (e.g.,
public,private,internal) relative to its enclosing type. If the enclosing type isinternal, apublicnested type within it is effectivelyinternaloutside the assembly. -
Logical Grouping: Sometimes, a type is so closely tied to another that defining it as a nested type improves code organization and semantic clarity. This is often seen with custom enumerators for collection types (e.g.,
List<T>.Enumerator).
Trade-offs: While useful for encapsulation, overusing nested types can make code harder to read due to increased indentation and potential confusion about which type you are currently operating within. They can also increase coupling between the outer and inner types.
Local Functions
Local functions (introduced in C# 7.0) are methods declared inside another method, property accessor, constructor, or other function-like member. They provide a concise way to define helper methods that are only relevant to the immediate context of their enclosing member.
Key Characteristics and Use Cases:
- Scope: A local function’s scope is strictly limited to the block in which it is defined. It cannot be called from outside that block.
- Encapsulation: They improve readability by keeping helper logic close to where it’s used, avoiding private methods that are only ever called from one place.
-
Variable Capture (Closures): This is the most powerful and internally complex aspect. Local functions can “capture” variables from their enclosing scope. This means they can access and modify variables defined in the method they are declared within, even after the outer method has returned (if the local function is assigned to a delegate and invoked later).
IL Representation of Closures (Compiler-Generated Display Classes): When a local function captures an outer variable, the C# compiler performs a significant transformation. It cannot simply access a stack variable that might no longer exist. Instead, the compiler:
- Creates a hidden, compiler-generated “display class” (or closure class).
- For each captured variable, it adds a field to this display class.
- The captured local variable in the original method is replaced with an instance of this display class, and accesses to the variable are redirected to the field on this instance.
- The local function itself becomes a method on this display class.
- If the local function is converted to a delegate, that delegate captures a reference to the display class instance. This instance is allocated on the heap to ensure the captured variables’ lifetime extends beyond the enclosing method’s stack frame, if necessary.
This heap allocation and indirection mean that closures can incur a small performance overhead compared to direct method calls, especially in hot paths or if many are created. However, the .NET JIT compiler is highly optimized and can often avoid heap allocations for closures that are not converted to delegates (i.e., only called locally).
static Func<int, int> CreateMultiplier(int factor) { // 'factor' is captured by the local function 'Multiply' int offset = 5; // 'offset' is also captured int Multiply(int number) // Local function { return (number * factor) + offset; } // Returns the local function wrapped in a delegate return Multiply; } // Usage var myMultiplier = CreateMultiplier(10); Console.WriteLine(myMultiplier(3)); // Output: (3 * 10) + 5 = 35 Console.WriteLine(myMultiplier(7)); // Output: (7 * 10) + 5 = 75In the example above,
factorandoffsetare captured into a compiler-generated class instance.myMultiplieris a delegate pointing to a method within that instance. -
staticLocal Functions (C# 8.0+): To avoid unintentional variable capture and its associated overhead, C# 8.0 introducedstaticlocal functions. Astaticlocal function cannot capture variables from its enclosing scope. It can only access its own parameters and variables declared within its own body. This guarantees no heap allocation for closures.static int SumOfSquares(int[] numbers) { int sum = 0; // int multiplier = 2; // Cannot be captured by a static local function // This local function does NOT capture 'sum' because 'sum' is modified in the outer scope // It's still safer to pass 'sum' explicitly if it were captured void AddToSum(int value) { sum += value; // 'sum' is implicitly passed by ref/value depending on compiler optimization. // It is NOT a captured variable for a static local func. } static int Square(int value) // Static local function - cannot capture outer variables { return value * value; // sum += value; // This would be an error - cannot access 'sum' from static local function } foreach (var number in numbers) { int squared = Square(number); // Calls static local function AddToSum(squared); // Calls non-static local function } return sum; } Console.WriteLine(SumOfSquares(new int[] { 1, 2, 3, 4 })); // Output: 30The
staticmodifier on local functions is a clear signal to both the compiler and other developers that the local function is self-contained and does not rely on any ambient state, making it more predictable and potentially more performant.
Trade-offs for Local Functions:
- Benefits: Improved readability, reduced scope, reduced class complexity (no need for private helper methods).
- Considerations: If closures are created in tight loops and captured variables lead to heap allocations, it can have a performance impact (though modern JIT often mitigates this). Understanding when this happens (e.g., when converting to a delegate) is important. Use
staticlocal functions to explicitly prevent captures when not needed.
Key Takeaways (Part 3)
- Implicit Conversions: Are safe, automatic conversions (e.g.,
inttolong, derived to base). - Explicit Conversions (Casting): Require
(Type)syntax, may lose data or throwInvalidCastExceptionat runtime if conversion is invalid. isOperator: Safely checks type compatibility.ispatterns (C# 7.0+) allow combining type check and assignment, e.g.,if (obj is string s).asOperator: Safely attempts reference/nullable conversions, returningnullon failure instead of throwing an exception. Only for reference types and nullable value types.- Method Overloading: Allows multiple methods with the same name but different parameter signatures within the same scope.
- Overload Resolution: A compile-time process where the C# compiler selects the “best” applicable method based on parameter types, conversions, and specificity rules. Can lead to ambiguity errors if no unique best match is found.
- Operator Overloading: Enables custom behavior for operators (
+,==, etc.) on user-defined types usingpublic static operatorsyntax. Must follow specific rules (e.g., paired operators,Equals/GetHashCodefor==). - User-Defined Conversion Operators: Allow defining
implicit(safe, automatic) orexplicit(requires cast, potential data loss) conversions between custom types and other types. op_Methods: Operator and user-defined conversion overloads are compiled into specialop_static methods in IL, indicating they are syntactic sugar for method calls.- Nested Types: Types declared within other types for encapsulation, logical grouping, and privileged access to outer type’s members (including private, via an instance).
- Local Functions (C# 7.0+): Methods defined within other methods, scoped to their enclosing block. Improve code readability and encapsulation.
- Closures (Local Functions): Local functions can “capture” variables from their enclosing scope. The compiler implements this by generating hidden “display classes” on the heap, potentially incurring minor performance overhead if closures are numerous or escape their method’s scope.
staticLocal Functions (C# 8.0+): Prevent variable capture from the enclosing scope, avoiding closure-related overhead and making intent clear.
8: Structs: Value Types and Performance Deep Dive
In C#, types are broadly categorized into two fundamental groups: reference types and value types. While Chapter 7 extensively explored classes (which are reference types), this chapter will delve into structs, the primary user-defined value type in C#. Understanding structs is crucial for writing efficient, high-performance C# code, as their memory layout and behavioral semantics differ significantly from classes.
8.1. The Anatomy, Memory Layout, and Boxing of a Struct
To truly grasp the implications of using structs, we must first understand their fundamental nature as value types and how they are managed in memory.
Value Types vs. Reference Types: The Core Difference
The distinction between value types and reference types lies in how their data is stored and how variables of these types behave.
- Reference Types (Classes):
- Variables store a reference (memory address) to an object allocated on the managed heap.
- Assignment (
=) copies the reference, meaning both variables point to the same object. - Inheritance from a base class (other than
object) is supported. - Can be
null.
- Value Types (Structs, Enums, Primitives like
int,bool):- Variables directly store the data value itself.
- Assignment (
=) copies the entire value, creating a completely independent duplicate. - Inheritance is not supported (all structs implicitly inherit from
System.ValueType, which itself inherits fromSystem.Object, but you cannot define your own inheritance hierarchy for structs). - Cannot be
nullby default (unless it’s a nullable value type,T?).
- C# Language Reference: Value types
- C# Language Reference: Reference types
Memory Layout: Stack vs. Heap
The primary difference in memory allocation for structs versus classes is where their data resides.
-
Structs on the Stack (Typically):
- When a struct is declared as a local variable within a method, its data is allocated directly on the stack. This means its memory is automatically managed: it’s allocated when the method is entered and deallocated when the method exits.
- Stack allocation is extremely fast as it simply involves moving the stack pointer.
- If a struct is a field of a class, its data is allocated inline as part of the class’s object on the heap.
- If a struct is a field of another struct, its data is allocated inline as part of that struct, recursively.
-
Classes on the Heap (Always):
- When a class is instantiated using
new, memory for its object is allocated on the managed heap. - Heap allocation is slower than stack allocation and involves the Garbage Collector (GC) to reclaim memory when objects are no longer referenced.
- Variables holding class instances on the stack merely contain a reference (a memory address) to the object on the heap.
- When a class is instantiated using
Conceptual Memory Layout:
// Example:
class MyClass
{
public int ClassField;
public MyStruct StructField; // MyStruct data is INLINED within MyClass object on the Heap
}
struct MyStruct
{
public int StructInt;
public double StructDouble;
}
// In a method:
void MyMethod()
{
MyStruct myLocalStruct; // Allocated on Stack
MyClass myLocalClass = new(); // 'myLocalClass' (reference) on Stack, object on Heap
myLocalClass.StructField = new MyStruct(); // MyStruct is part of the MyClass object on Heap
}
This memory layout has significant implications for performance. Stack allocation avoids the overhead of heap allocation and garbage collection.
Value Semantics and Copying
Because structs store their data directly, operations like assignment and passing to methods involve copying the entire value.
struct Point
{
public int X;
public int Y;
public override string ToString() => $"({X}, {Y})";
}
Point p1 = new() { X = 10, Y = 20 };
Point p2 = p1; // p2 is a completely independent copy of p1
p2.X = 30; // Modifying p2 does not affect p1
Console.WriteLine($"p1: {p1}"); // Output: p1: (10, 20)
Console.WriteLine($"p2: {p2}"); // Output: p2: (30, 20)
For small structs, this copying is efficient. However, for large structs, frequent copying can lead to performance overhead as more data needs to be transferred. This is a crucial consideration when designing structs, and it leads to the discussion of passing structs by reference later in this chapter.
Boxing and Unboxing of Structs: Performance Implications
Boxing is the process of converting a value type instance (like a struct or an int) into an object reference type. This occurs implicitly when a value type is assigned to a variable of type object or to an interface type that the value type implements.
The Boxing Process:
- Heap Allocation: A new object is allocated on the managed heap.
- Copying: The value of the struct is copied from its stack location (or inline location) into the newly allocated heap object.
- Reference Return: A reference to this new heap object is returned.
Example of Boxing:
Point p = new() { X = 100, Y = 200 }; // Point is on the stack
object obj = p; // BOXING: p's value is copied to a new object on the heap, obj holds a reference to it.
IComparable comparable = p; // BOXING: Same here, if Point implements IComparable.
p.X = 50; // Modifying the original struct on the stack
Console.WriteLine($"Original Point: {p}"); // Output: Original Point: (50, 200)
Console.WriteLine($"Boxed Object X: {((Point)obj).X}"); // Output: Boxed Object X: 100 (obj is a copy of original p)
Performance Implications of Boxing:
- Heap Allocation Overhead: Each boxing operation involves allocating memory on the heap, which is slower than stack allocation.
- Garbage Collection Overhead: Boxed objects must be collected by the GC, contributing to GC pressure and potentially pauses.
- Copying Overhead: The data itself must be copied, which is costly for larger structs.
- Indirection: Accessing members of a boxed struct requires dereferencing the heap pointer, which is an extra step compared to direct stack access.
Unboxing is the reverse process: converting a boxed value type back to its original value type.
The Unboxing Process:
- Type Check: The runtime verifies that the boxed object’s actual type matches the target value type. If not, an
InvalidCastExceptionis thrown. - Copying: The value is copied from the heap object back to a new location on the stack (or a field).
// Continuing from the boxing example
Point unboxedP = (Point)obj; // UNBOXING: Value copied from heap back to stack/local variable
Console.WriteLine($"Unboxed Point: {unboxedP}"); // Output: Unboxed Point: (100, 200)
try
{
int invalidUnbox = (int)obj; // InvalidCastException! obj contains a Point, not an int.
}
catch (InvalidCastException ex)
{
Console.WriteLine($"Error unboxing: {ex.Message}");
}
Strategies to Avoid Boxing:
- Generics: Use generic collections (
List<T>,Dictionary<TKey, TValue>) instead of non-generic ones (ArrayList,Hashtable) because generics work directly with the value type without boxing. IEquatable<T>: Implement generic interfaces (IEquatable<T>,IComparable<T>) for structs instead of non-generic ones to avoid boxing during equality comparisons or sorting.inParameters: When passing large structs to methods, use theinmodifier (C# 7.2+) to pass by read-only reference, avoiding a copy and boxing if the parameter type would otherwise cause it.ref struct: For highly performance-sensitive scenarios,ref structs (C# 7.2+) cannot be boxed at all, enforcing stack-only allocation.
Understanding boxing is paramount. While structs can offer performance benefits by being stack-allocated, improper use (leading to frequent boxing) can quickly negate these benefits and introduce significant overhead.
8.2. Struct Constructors and Initialization
Structs have specific rules and behaviors concerning constructors and field initialization that differ from classes. These rules have evolved with modern C# versions.
Default Constructor and Field Initialization
Prior to C# 10, structs implicitly had a public, parameterless default constructor that initialized all fields to their default values (e.g., 0 for numeric types, null for reference types, default(T) for other value types). You could not declare your own parameterless public constructor for a struct.
C# 10 and Later:
- Explicit Parameterless Constructors: C# 10 finally allowed you to declare an explicit public parameterless constructor for structs. If you do so, the implicit default constructor is suppressed. This constructor must assign a value to every field of the struct (in C# 10)
- Field Initializers: C# 10 also enabled field initializers for structs, allowing you to assign initial values directly at the field declaration site, similar to classes.
-
Auto-Default Fields: C# 11 allows you to define constructors which do not require you to assign all fields. The ones not assigned in the constructor will be initialized to their default values (e.g.,
0,null, etc.). This is similar to how classes work. - C# Language Reference: Struct types (Constructors)
Example (C# 10+):
struct MyPointC10
{
public int X { get; set; } = 1; // Field initializer allowed
public int Y { get; set; }
public MyPointC10() // Explicit parameterless constructor allowed (C# 10+)
{
Y = 2; // Must assign all fields not covered by initializers
// X is already initialized to 1
}
public MyPointC10(int x, int y)
{
X = x;
Y = y;
}
public override string ToString() => $"({X}, {Y})";
}
MyPointC10 p1 = new(); // Calls explicit parameterless ctor (X=1, Y=2)
Console.WriteLine($"p1: {p1}"); // Output: p1: (1, 2)
MyPointC10 p2 = default; // Still uses the implicit default for default keyword (X=0, Y=0)
Console.WriteLine($"p2 (default): {p2}"); // Output: p2 (default): (0, 0)
MyPointC10 p3 = new(10, 20); // Calls custom constructor
Console.WriteLine($"p3: {p3}"); // Output: p3: (10, 20)
The default keyword still triggers the zero-initialization behavior, bypassing any custom parameterless constructor.
Custom Constructors
You can define custom constructors for structs with parameters, just like with classes. If you define any custom constructor, all fields must be definitely assigned within that constructor or through field initializers (before C# 11). C# 11 and its auto-default fields feature allow you to skip assigning some fields, which will then default to their type’s default value.
struct Size
{
public int Width;
public int Height;
public Size(int width, int height)
{
Width = width;
Height = height;
}
// You can also chain constructors using 'this()'
public Size(int side) : this(side, side) { }
public override string ToString() => $"W:{Width}, H:{Height}";
}
Size s1 = new Size(10, 20);
Console.WriteLine($"s1: {s1}"); // Output: s1: W:10, H:20
Size s2 = new Size(5); // Chained constructor
Console.WriteLine($"s2: {s2}"); // Output: s2: W:5, H:5
Primary Constructors (C# 12)
C# 12 introduced primary constructors for both classes and structs, offering a concise syntax for declaring constructor parameters that are directly available within the type’s body. For structs, primary constructor parameters are often used to initialize fields or properties.
Example (C# 12):
struct Position(int x, int y) // Primary constructor
{
public int X { get; set; } = x; // Initialize property from primary ctor param
public int Y { get; set; } = y;
// You can also add other members, including other constructors
public Position(int value) : this(value, value) { } // Chain to primary ctor
public override string ToString() => $"Pos: ({X}, {Y})";
}
Position pos1 = new(10, 20); // Uses primary constructor
Console.WriteLine($"pos1: {pos1}"); // Output: pos1: Pos: (10, 20)
Position pos2 = new(5); // Uses chained constructor
Console.WriteLine($"pos2: {pos2}"); // Output: pos2: Pos: (5, 5)
readonly Structs and Methods
When you declare a method as readonly, it guarantees that the method will not modify the state of the struct. When you try to modify any field or property of the struct within a readonly method, the compiler will raise an error.
struct A {
private int x;
public readonly void f() {
// x++; // Compile-time error: this is a readonly method, cannot modify state.
Console.WriteLine($"Readonly method, x: {x}");
}
}
The readonly modifier can be applied to a struct declaration (C# 7.2+). A readonly struct guarantees that all its instance fields are readonly and that all auto-implemented properties implicitly become readonly. Furthermore, all instance members (methods, properties, indexers) of a readonly struct are treated as readonly, meaning they cannot modify the struct’s state.
Benefits of readonly structs:
- Immutability: Enforces immutability at compile time, making the struct’s behavior predictable and thread-safe. This is a common and highly recommended pattern for structs.
- Performance Optimization (Defensive Copies): The compiler can make optimizations because it knows the struct’s state won’t change. Specifically, it can avoid “defensive copies” when passing
readonlystructs byinreference, which can be a significant performance win (discussed in 8.3).
Example of readonly struct:
readonly struct ImmutablePoint // C# 7.2+
{
public int X { get; } // Implicitly readonly
public int Y { get; }
private readonly int _z; // all fields has to be marked as readonly
public ImmutablePoint(int x, int y)
{
X = x; // Must assign in constructor
Y = y;
}
// All instance methods are implicitly readonly
public double DistanceFromOrigin()
{
return Math.Sqrt(X * X + Y * Y);
}
// public void Move(int dx, int dy) { X += dx; } // Compile-time error: Cannot modify members of 'this' in a 'readonly' struct.
public override string ToString() => $"Immutable ({X}, {Y})";
}
ImmutablePoint ip = new(10, 20);
Console.WriteLine(ip.DistanceFromOrigin());
// ip.X = 5; // Compile-time error: Cannot assign to 'X' because it is a readonly property.
For modern struct design, especially for small, data-holding types, declaring them as readonly struct is often the best practice to leverage their immutable value semantics fully.
8.3. Struct Identity: Implementing Equals() and GetHashCode()
For value types like structs, defining what constitutes “equality” is crucial. Unlike reference types, where default equality means “same object in memory,” for structs, equality usually means “same value.” Correctly implementing Equals() and GetHashCode() is vital for structs to behave as expected, especially when used in collections or for comparisons.
Default Equals() and GetHashCode()
By default, System.ValueType (the base class for all structs) provides default implementations for Equals() and GetHashCode().
- Default
Equals(): Uses reflection to perform a field-by-field comparison of the struct’s values (including private fields). This can be slow, especially for large structs or those containing reference types. - Default
GetHashCode(): Also uses reflection, often combining the hash codes of its fields. This can also be slow and produce poor hash distributions.
While convenient, the default implementations are often inefficient and may not always provide the semantically correct equality for your specific struct.
Implementing Equals(object? obj) and GetHashCode()
When you implement value equality for your struct, you should override these methods.
struct Location
{
public int X { get; }
public int Y { get; }
public Location(int x, int y) => (X, Y) = (x, y);
// Override object.Equals(object? obj)
public override bool Equals(object? obj)
{
if (obj is Location other)
{
return X == other.X && Y == other.Y;
}
return false; // Return false if obj is not a Location or is null
}
// Override object.GetHashCode()
public override int GetHashCode()
{
// Combine hash codes of all fields that contribute to equality
return HashCode.Combine(X, Y); // C# 8.0+ HashCode.Combine is efficient
}
public override string ToString() => $"Loc: ({X}, {Y})";
}
Location loc1 = new(10, 20);
Location loc2 = new(10, 20);
Location loc3 = new(30, 40);
Console.WriteLine($"loc1.Equals(loc2): {loc1.Equals(loc2)}"); // True
Console.WriteLine($"loc1.Equals(loc3): {loc1.Equals(loc3)}"); // False
Console.WriteLine($"loc1.GetHashCode(): {loc1.GetHashCode()}");
Console.WriteLine($"loc2.GetHashCode(): {loc2.GetHashCode()}");
// the hash codes of loc1 and loc2 will be the same
Implementing IEquatable<T>: Avoiding Boxing
To provide a type-safe and efficient Equals method that avoids boxing when comparing two structs of the same type, implement the generic IEquatable<T> interface.
struct BetterLocation : IEquatable<BetterLocation>
{
public int X { get; }
public int Y { get; }
public BetterLocation(int x, int y) => (X, Y) = (x, y);
// Implementation of IEquatable<BetterLocation>
public bool Equals(BetterLocation other)
{
return X == other.X && Y == other.Y;
}
// Still override object.Equals for compatibility with non-generic code
public override bool Equals(object? obj)
{
return obj is BetterLocation other && Equals(other); // Use the strongly-typed Equals method
}
public override int GetHashCode()
{
return HashCode.Combine(X, Y);
}
public override string ToString() => $"BetterLoc: ({X}, {Y})";
}
BetterLocation bl1 = new(10, 20);
BetterLocation bl2 = new(10, 20);
Console.WriteLine($"bl1.Equals(bl2) (IEquatable): {bl1.Equals(bl2)}"); // True, no boxing
Implementing IEquatable<T> is a best practice for structs to ensure efficient and type-safe equality comparisons.
Overloading Equality Operators (== and !=)
When you define custom equality for a struct, you should also overload the == and != operators to ensure consistent behavior throughout your code.
struct CompleteLocation : IEquatable<CompleteLocation>
{
public int X { get; }
public int Y { get; }
public CompleteLocation(int x, int y) => (X, Y) = (x, y);
public bool Equals(CompleteLocation other) => X == other.X && Y == other.Y;
public override bool Equals(object? obj) => obj is CompleteLocation other && Equals(other);
public override int GetHashCode() => HashCode.Combine(X, Y);
// Overload '==' operator
public static bool operator ==(CompleteLocation left, CompleteLocation right)
{
return left.Equals(right); // Use the IEquatable<T> Equals method
}
// Must overload '!=' if '==' is overloaded
public static bool operator !=(CompleteLocation left, CompleteLocation right)
{
return !(left == right); // Call the overloaded '=='
}
public override string ToString() => $"CompleteLoc: ({X}, {Y})";
}
CompleteLocation cl1 = new(10, 20);
CompleteLocation cl2 = new(10, 20);
CompleteLocation cl3 = new(30, 40);
Console.WriteLine($"cl1 == cl2: {cl1 == cl2}"); // True
Console.WriteLine($"cl1 != cl3: {cl1 != cl3}"); // True
For consistency, always overload == and != if you implement custom equality.
record struct (C# 10+): Automatic Value Equality
C# 10 introduced record struct (and record class). Like record class, record struct types automatically generate implementations for:
- Value equality (overriding
Equals(),GetHashCode(),IEquatable<T>). ==and!=operators.ToString().- A
Deconstructmethod.
This significantly reduces boilerplate for data-centric structs where value equality is desired.
record struct ValuePoint(int X, int Y); // C# 10+
ValuePoint vp1 = new(10, 20);
ValuePoint vp2 = new(10, 20);
ValuePoint vp3 = new(30, 40);
Console.WriteLine($"vp1 == vp2: {vp1 == vp2}"); // True (automatic operator overload)
Console.WriteLine($"vp1.Equals(vp2): {vp1.Equals(vp2)}"); // True (automatic Equals)
Console.WriteLine($"vp1.ToString(): {vp1.ToString()}"); // Output: ValuePoint { X = 10, Y = 20 } (automatic ToString)
For structs that are primarily data containers and where value equality is the natural comparison, record struct is the recommended modern approach. You can also combine readonly with record struct (e.g., readonly record struct).
8.4. Passing Structs: in, ref, out Parameters
How structs are passed to methods can significantly impact performance, especially for larger structs. By default, structs are passed by value, meaning a complete copy is made. C# provides parameter modifiers (ref, out, in) to control this behavior.
Passing by Value (Default)
When a struct is passed to a method without any modifiers, it’s passed by value. This means a new copy of the struct is created on the method’s stack frame, and the method operates on this copy. Any modifications to the struct within the method do not affect the original struct in the calling code.
struct Counter
{
public int Count;
public override string ToString() => $"Count: {Count}";
}
void IncrementByValue(Counter c)
{
c.Count++; // Modifies the local copy
Console.WriteLine($"Inside method (by value): {c}");
}
Counter myCounter = new() { Count = 10 };
Console.WriteLine($"Before call (by value): {myCounter}");
IncrementByValue(myCounter);
Console.WriteLine($"After call (by value): {myCounter}");
// Output:
// Before call (by value): Count: 10
// Inside method (by value): Count: 11
// After call (by value): Count: 10 (original unchanged)
Performance Implication: For large structs, the copying operation can be a performance bottleneck due to CPU cycles spent on copying memory and potential cache misses.
Passing by Reference: ref and out
The ref and out modifiers cause structs to be passed by reference, meaning no copy is made. Instead, the method receives a direct reference (memory address) to the original struct.
ref: The struct must be initialized before being passed. The method can read and modify the original struct.-
out: The struct does not need to be initialized before being passed. The method must assign a value to the struct before returning. The method can read and modify the original struct. - C# Language Reference:
ref(keyword) - C# Language Reference:
out(keyword)
void IncrementByRef(ref Counter c)
{
c.Count++; // Modifies the original struct
Console.WriteLine($"Inside method (by ref): {c}");
}
void InitializeAndSet(out Counter c, int initialCount)
{
c = new Counter { Count = initialCount }; // Must assign
Console.WriteLine($"Inside method (out): {c}");
}
// ref example
Counter myCounterRef = new() { Count = 10 };
Console.WriteLine($"Before call (by ref): {myCounterRef}");
IncrementByRef(ref myCounterRef);
Console.WriteLine($"After call (by ref): {myCounterRef}");
// Output:
// Before call (by ref): Count: 10
// Inside method (by ref): Count: 11
// After call (by ref): Count: 11 (original modified)
// out example
InitializeAndSet(out Counter myNewCounter, 5);
Console.WriteLine($"After call (out): {myNewCounter}");
// Output:
// Inside method (out): Count: 5
// After call (out): Count: 5
Performance Implication: ref and out avoid the copying overhead entirely. This is beneficial for large structs where modification is intended or necessary.
Passing by Read-Only Reference: in (C# 7.2+)
The in modifier (introduced in C# 7.2) allows you to pass structs by read-only reference. This is the best of both worlds for many scenarios: it avoids copying (like ref) but also prevents accidental modification inside the method. The compiler enforces that the method cannot write to the in parameter.
void PrintCounter(in Counter c)
{
Console.WriteLine($"Inside method (in): {c}");
// c.Count++; // Compile-time error: Cannot modify an 'in' parameter.
}
Performance Implications of in:
- Avoids Copying: The primary benefit is avoiding the cost of copying large structs.
- Defensive Copies (and
readonlystruct optimization):- If you pass a mutable (non-
readonly) struct usingin, and you call a non-readonlyinstance method on that struct inside theinparameter method, the compiler might create a “defensive copy” of the struct. This is done to ensure the immutability guarantee of theinparameter is maintained, as the non-readonlymethod could potentially modify the struct’s internal state. - However, if the struct itself is declared as
readonly struct(as discussed in 8.2), the compiler knows that none of its instance methods can modify its state. In this case, no defensive copy is ever made, even if you call a method on theinparameter. This is whyreadonly structused withinparameters is the optimal pattern for passing large, immutable structs for performance.
- If you pass a mutable (non-
Conceptual IL and Performance:
- By Value: creates a copy on the stack.
- By
ref/out/in: The IL passes a memory address (a managed pointer orbyref) to the struct’s location. Operations on the parameter then directly access that memory.
This direct memory access avoids copying. The in modifier adds a read-only constraint at the compiler level.
ref and ref readonly Variables and Returns
Just as ref parameters allow passing structs by reference, C# also supports ref returns, which allow methods to return a reference to a struct without copying it. This however doesn’t prevent from modifying the struct’s state. The caller must then receive this reference into a ref local variable or ref parameter.
Similarly, ref readonly returns allow a method to return a reference to a readonly struct without copying it. The caller must then receive this reference into a ref readonly local variable or in parameter.
readonly struct BigData(int[] data)
{
public int Length => data.Length;
// Assume data is managed internally and not exposed mutable.
// For simplicity, let's just expose a sum
public int Sum() => data.Sum();
}
class DataManager
{
static BigData _cachedBigData = new BigData(new int[1000]); // A large, immutable struct
// Returns a reference to a struct (mutable)
public static ref BigData GetDataRef()
{
return ref _cachedBigData; // This allows modification of the cached data
}
// Returns a read-only reference to a struct
public static ref readonly BigData GetDataReadonlyRef()
{
return ref _cachedBigData;
}
}
ref BigData dataRef = ref DataManager.GetDataRef(); // Receive by ref
Console.WriteLine($"Cached data length: {dataRef.Length}");
dataRef = new BigData(new int[10]); // we can modify the cached data inside of DataManager!
ref readonly BigData dataReadonlyRef = ref DataManager.GetDataReadonlyRef(); // Receive by ref readonly
// dataReadonlyRef = new BigData(new int[10]);
// Compile-time error: Cannot assign to 'dataReadonlyRef' because it is a 'ref readonly' variable
ref and ref readonly returns are highly specialized for performance-critical scenarios, allowing access to large struct data without any copying, further reducing memory pressure and improving throughput.
8.5. High-Performance Types: ref struct, readonly ref struct, and ref fields (C# 11)
While all structs are value types, a specialized category exists for truly high-performance, low-allocation scenarios: ref structs. These types, designed for working directly with memory, come with stricter rules that guarantee their stack-only allocation and prevent potential memory safety issues that could arise from managing raw memory pointers. They are the backbone of modern C# performance primitives like Span<T>.
The Problem ref structs Solve: Memory Safety and Zero Allocation
Traditional class objects are allocated on the managed heap, which introduces garbage collection overhead. Standard structs, while often stack-allocated, can still be boxed (converted to an object on the heap) or become fields of heap-allocated objects, losing their stack-only guarantee.
When working with large buffers, parsing data streams, or interoperating with unmanaged code, avoiding heap allocations and memory copying is paramount for maximum throughput. However, manipulating raw pointers (IntPtr or unsafe pointers) comes with significant risks, primarily the danger of dangling pointers (a pointer that refers to a memory location that has already been deallocated or is no longer valid).
ref structs were introduced (C# 7.2 with .NET Core 2.1) to bridge this gap. They allow for pointer-like performance and memory efficiency while retaining C#’s strong type safety and memory safety guarantees, primarily by enforcing that they can never leave the stack.
ref struct: Always on the Stack
A ref struct is a struct declared with the ref modifier (e.g., ref struct MyRefStruct). The compiler strictly enforces rules to ensure that instances of a ref struct never reside on the managed heap.
Core Constraints and Their Reasoning:
- Cannot be Boxed: A
ref structcannot be converted toobjector to any interface type it might implement (C# 13+). This directly prevents it from being allocated on the heap during boxing operations.- Implication: This means you cannot store
ref structs directly in non-generic collections likeArrayListor as elements inobject[]arrays. - Implication: If a
ref structimplements a non-generic interface, lets sayIDisposable, it cannot be passed to methods that expectIDisposable, because that would require boxing.
- Implication: This means you cannot store
- Cannot be a Field of a Class or a Regular Struct:
ref structs can only be fields of otherref structs. This ensures that if aref structis part of a larger type, that larger type is also constrained to be stack-allocated. - Cannot be Captured by Lambdas or Local Functions (unless
static): Because lambdas and local functions (when they capture variables) can potentially be assigned to delegates and escape their current scope (and delegates are heap-allocated objects), aref structcannot be captured. Astaticlocal function or lambda, which by definition captures no outer variables, is an exception. - Cannot Implement Interfaces Directly (in older C# versions): This constraint previously existed because implementing interfaces often implies boxing (e.g., when an interface method needs
thisas anobjectparameter, or when a generic method parameter isn’t strictly constrained).- C# 11 Relaxation: With C# 11, this rule is relaxed somewhat when generics are involved with
scoped reftype parameters, allowingref structs to fulfill interfaces in very specific, safe contexts where boxing is proven not to occur. However, for general interface usage, it’s still not possible. - C# 13 Full Support: C# 13 introduced full interface support for
ref struct.
- C# 11 Relaxation: With C# 11, this rule is relaxed somewhat when generics are involved with
- Cannot Be a Generic Type Argument (in older C# versions): Prior to C# 13,
ref structs could not be used as type arguments for generic types (e.g.,List<Span<byte>>was disallowed).- C# 11 Relaxation with
scoped ref: C# 11 introducedscoped refas a generic type parameter constraint, allowingref structs to be used as type arguments if the generic type or method explicitly limits the lifetime of theref structinstance to the current scope. This is a highly specialized scenario. - C# 13 Full Support: C# 13 allows
ref structs to be used as generic type arguments using theallows ref structanti-constraint.
- C# 11 Relaxation with
These stringent rules are collectively known as ref-safety rules. The compiler performs extensive “escape analysis” to ensure that a ref struct instance (or any reference it contains) cannot “escape” the stack frame in which it was created. This prevents the memory corruption associated with dangling pointers.
Span<T> and ReadOnlySpan<T>: The Quintessential ref structs
The most prominent and widely used examples of ref struct are System.Span<T> and System.ReadOnlySpan<T>. These types provide a modern, safe, and highly efficient way to work with contiguous blocks of memory of any type, without any heap allocations or copying overhead.
How They Work:
Span<T> is essentially a “view” over a contiguous block of memory. It doesn’t own the memory; it merely provides a safe, typed way to access it. It achieves this by internally holding a ref T (a managed pointer to the start of the memory region) and an int for the length. Because Span<T> is a ref struct, it is always stack-allocated, and therefore, its internal ref T cannot outlive the memory it points to within the current stack frame.
Versatility of Memory Sources:
Span<T> and ReadOnlySpan<T> can represent memory from various sources:
- Arrays:
new byte[100].AsSpan() - Sub-sections of Arrays:
myArray.AsSpan(startIndex, length) - Stack-allocated Memory:
stackallockeyword (Span<byte> stackBuffer = stackalloc byte[256];) - Native Memory (Pointers): Via
unsafecode,Span<T>can wrapIntPtrorvoid*for highly efficient interop. - Strings:
string.AsSpan()provides aReadOnlySpan<char>for efficient, zero-copy string manipulation (e.g., parsing, searching without allocating substrings). Memory<T>:Memory<T>is a heap-allocated counterpart that can escape the stack.Span<T>can be created fromMemory<T>.Span.
Zero-Copy Benefits and Performance:
Because Span<T> doesn’t copy the underlying data, operations like slicing (span.Slice(startIndex, length)), indexing (span[i]), and searching are incredibly fast. This is particularly beneficial for:
- High-performance parsing: Reading data from network streams or files without allocating intermediate strings or arrays.
- Serialization/Deserialization: Efficiently writing to or reading from buffers.
- Numerical computations: Working with large arrays of numbers.
- Interop: Safely interacting with unmanaged memory without pinning or unsafe blocks.
Example Illustrating Span<T>’s Power:
// 1. Working with Array Segment (zero-copy)
static void ProcessArraySegment(Span<int> data)
{
Console.WriteLine($" Processing Span (Length={data.Length})");
for (int i = 0; i < data.Length; i++) {
data[i] *= 10;
}
}
// Usage:
int[] numbers = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
ProcessArraySegment(numbers.AsSpan(2, 5)); // Operates on {3,4,5,6,7} directly
Console.WriteLine($"Modified array: {string.Join(", ", numbers)}");
// Output: Modified array: 1, 2, 30, 40, 50, 60, 70, 8, 9, 10
// 2. Working with Stack-Allocated Memory
static void ProcessStackData()
{
Span<int> buffer = stackalloc int[128]; // Allocated on stack
buffer.Fill(42); // Initialize all values to 42
Console.WriteLine($"Original buffer[0]: {buffer[0]}");
// Process a slice of the stack buffer
ProcessArraySegment(buffer.Slice(0, 10)); // process first 10 elements
Console.WriteLine($"Processed buffer[0]: {buffer[0]}"); // Original buffer is modified
}
// Usage:
ProcessStackData();
// Output:
// Original buffer[0]: 42
// Processing Span (Length=10)
// Processed buffer[0]: 420
// 3. Working with ReadOnlySpan for String Parsing (zero-allocation substrings)
static ReadOnlySpan<char> GetPart(ReadOnlySpan<char> source, char delimiter, int partIndex)
{
var current = source;
for (int i = 0; i < partIndex; i++) {
int delimiterIndex = current.IndexOf(delimiter);
if (delimiterIndex == -1)
return ReadOnlySpan<char>.Empty;
current = current.Slice(delimiterIndex + 1);
}
int nextDelimiterIndex = current.IndexOf(delimiter);
return nextDelimiterIndex == -1 ? current : current.Slice(0, nextDelimiterIndex);
}
// Usage:
string csvLine = "apple,banana,cherry,date";
ReadOnlySpan<char> firstFruit = GetPart(csvLine.AsSpan(), ',', 1);
Console.WriteLine($"First fruit: '{firstFruit.ToString()}'");
// Output: First fruit: 'banana'
Span<T> provides a unified, safe, and highly efficient API for memory access that was previously only possible with unsafe pointers or less performant memory copying.
Custom ref struct Types
The notation for creating a custom ref struct is straightforward:
public ref struct CustomRef
{
public bool IsValid;
public Span<int> Inputs;
public Span<int> Outputs;
}
Here we are storing two Span<int> fields, which are themselves ref structs. Note that this wouldn’t be possible with a class or regular struct, as ref structs can only be fields of other ref structs or used as local variables.
To pass a ref struct to a method, don’t to use the ref keyword, because ref structs are always passed by reference by default. Intuitively, the ref is already included in the ref struct definition.
public void ProcessCustomRef(CustomRef data)
{
if (data.IsValid)
{
// Process the inputs and outputs
for (int i = 0; i < data.Inputs.Length; i++)
{
data.Outputs[i] = data.Inputs[i] * 2; // Example processing
}
}
}
readonly ref struct
A readonly ref struct combines the benefits of readonly struct (immutability, no defensive copies) with ref struct (stack-only, no boxing). This is the safest and most performant variant for read-only, stack-allocated memory views.
ReadOnlySpan<T> itself is a readonly ref struct, enforcing that you cannot modify the data it points to through the Span itself.
using System.Buffers.Binary; // required System.Buffers.Binary.BinaryPrimitives for ReadUInt16LittleEndian
// Custom readonly ref struct for highly efficient immutable views
readonly ref struct FixedSizeBufferView
{
private readonly ReadOnlySpan<byte> _data;
public FixedSizeBufferView(ReadOnlySpan<byte> data)
{
if (data.Length != 16)
{
throw new ArgumentException("Buffer must be 16 bytes.", nameof(data));
}
_data = data;
}
public byte GetByte(int index) => _data[index];
public ushort GetUInt16(int index) => BinaryPrimitives.ReadUInt16LittleEndian(_data.Slice(index));
// No instance methods can modify _data (compile-time enforced)
// public void SetByte(int index, byte value) { _data[index] = value; } // Compile-time error
public override string ToString() => $"Buffer[{_data.Length}]: {BitConverter.ToString(_data.ToArray())}";
}
// Usage:
Span<byte> myBytes = stackalloc byte[16];
new Random().NextBytes(myBytes); // Fill with random data
var view = new FixedSizeBufferView(myBytes);
Console.WriteLine($"View: {view.ToString()}");
Console.WriteLine($"Byte at index 5: {view.GetByte(5)}");
Console.WriteLine($"UInt16 at index 0: {view.GetUInt16(0)}");
myBytes[0] = 0; // Can still modify original source if it's a writable Span
Console.WriteLine($"UInt16 at index 0 after source modification: {view.GetUInt16(0)}"); // Reflects change
// Output:
// View: Buffer[16]: E0-D6-5A-C9-CA-85-C7-29-51-71-4F-54-8E-62-8D-E7
// Byte at index 5: 133 (Ox85 = 133)
// UInt16 at index 0: 55008 (OxD6E0 = 55008)
// UInt16 at index 0 after source modification: 54784 (OxD600 = 54784)
ref fields (C# 11) and the scoped Keyword
Prior to C# 11, ref structs could not contain ref fields (i.e., fields that directly hold a ref T to another variable, like ref int x). This limitation was removed with C# 11, allowing ref structs to include ref fields, significantly increasing their flexibility in building low-level, high-performance types that “borrow” memory directly. Note that ref fields are only allowed in ref structs, not in regular structs or classes.
- C# Language Reference:
reffields - I highly recommend reading this article on
ref fieldsandscoped
ref Fields and Properties
A ref field allows a struct to effectively store a reference to a variable, rather than a copy of its value. This is powerful for creating wrappers or specialized data structures that operate directly on existing memory locations.
// Example: A trivial struct that holds a reference to an int.
// In a real scenario, this would be more complex and useful.
ref struct IntRefWrapper
{
private ref int _value; // This is a ref field (C# 11)
// Constructor takes a ref parameter and assigns it to the ref field
public IntRefWrapper(ref int value)
{
_value = ref value; // Assign by reference
}
// Property to access the referenced value
public ref int Value => ref _value;
public void Increment()
{
_value++; // Modifies the original variable that _value refers to
}
}
// Usage:
int number = 10;
var wrapper = new IntRefWrapper(ref number);
wrapper.Increment(); // Increment the value through the wrapper
Console.WriteLine(number); // Outputs: 11
Ref-Safety and Lifetimes: The introduction of ref fields demands even stricter compiler-enforced ref-safety rules to prevent dangling references. The core problem is ensuring that a ref field (or any ref local variable or in/ref/out parameter) does not outlive the variable it points to. If it did, it would become a dangling pointer, leading to memory access violations or corrupt data.
ref struct StackReference<T>(ref T target)
{
private ref T _reference = ref target;
public ref T Value => ref _reference;
}
static StackReference<int> EscapeLocalScope()
{
int data = 100;
StackReference<int> wrapper = new(ref data);
return wrapper; // Error: this may expose referenced variables outside of their declaration scope
}
The C# compiler performs sophisticated escape analysis to determine the “lifetime” of ref variables and ensure they don’t “escape” a context where the data they refer to might no longer be valid.
The scoped Keyword
The scoped keyword provides a way for developers to explicitly tell the compiler to limit the “safe to escape” lifetime of ref variables or in/ref/out parameters.
- C# Language Reference:
scopedkeyword - I highly recommend reading this article on
ref fieldsandscoped
Purpose of scoped:
scoped ensures that a reference (or ref struct containing references) does not escape the current method or local scope. This allows the compiler to approve certain ref operations that might otherwise be deemed unsafe because it knows the reference’s lifetime is strictly bounded.
Imagine you have a method that takes a Span<int> as a parameter:
static void ProcessData(Span<int> span) { ... }
there’s no guarantee that someone inside of the method won’t write:
_someSpanField = span;
Now imagine calling
static void RunSpan()
{
Span<int> valuesToCopy = stackalloc int[] { 1, 2, 3, 4, 5 };
ProcessData(valuesToCopy); // error: valuesToCopy could escape its declaration scope
}
The valuesToCopy variable lives only in the scope of the RunSpan method’s stack frame. If ProcessData were to store the span in a field, it would create a dangling reference, as valuesToCopy would be deallocated once RunSpan returns. Someone could then try to access _someSpanField, leading to undefined behavior.
We can thankfully fix this by using the scoped keyword:
static void ProcessData(scoped Span<int> span)
{
// ... process the data
_someSpanField = span; // this would now be a compile-time error
// because span is scoped and cannot escape this method
}
This ensures that span cannot be stored in a field or returned from the method, thus preventing the Span (which points to stack memory) from escaping its valid lifetime. Meaning that RunSpan() can now safely call ProcessData without risking dangling references.
Where scoped can be used:
scoped reflocals:scoped ref int myRef = ref someInt;- ensuresmyRefcannot be returned or stored in a field that might outlivesomeInt.scoped in/ref/outparameters:void Foo(scoped Span<int> s)- ensures theSpanpassed in cannot be stored in a field or returned from the method, thus preventing theSpanfrom escaping its valid lifetime. This is crucial for generic constraints withref structs.
ref fields and the scoped keyword are powerful, but they push C# closer to low-level memory management, requiring a deep understanding of lifetimes and compiler safety rules. They are primarily for library authors building highly optimized primitives, rather than for typical application-level code.
The allows ref struct Anti-Constraint (C# 13)
The Problem Before C# 13:
Prior to C# 13, ref struct types could not be used as type arguments for generic types or methods. This was a major limitation. For instance, you could not declare List<Span<int>> or Dictionary<int, ReadOnlySpan<char>>. While Span<T> and ReadOnlySpan<T> themselves are generic, you couldn’t pass them as the T in other generic types or methods without resorting to less type-safe or less performant alternatives. This severely limited the ability to write generic algorithms that could operate directly on Span-like types.
public struct Processor<T> {
public void Process(T data) { }
}
var p = new Processor<Span<byte>>();
// compile error: 'Span<byte>' cannot be used as type argument here
The Solution:
C# 13 introduces a new generic type parameter anti-constraint: allows ref struct. When applied to a type parameter (where T : allows ref struct), it declares that T can be a ref struct type. This is an “anti-constraint” because, unlike class or struct constraints, it specifies what the type can be, rather than what it must be derived from or implement.
The compiler, when encountering T : allows ref struct, ensures that all instances of T within that generic context adhere to ref safety rules. This allows ref structs to participate in generic operations, unlocking significant potential for high-performance libraries.
using System.Runtime.CompilerServices; // needed for unsafe casting
// C# 13: Generic type parameter with 'allows ref struct' anti-constraint
// This generic struct can now work with 'ref struct' types like Span<T>
public ref struct Processor<T> where T : allows ref struct
{
// 'scoped' is crucial here to limit the lifetime of the 'data' parameter
// within the method, preventing any reference within 'data' from escaping.
public void Process(scoped T data)
{
Console.WriteLine($"Processing a {typeof(T).Name}");
if (typeof(T) == typeof(Span<byte>)) {
Span<byte> span = Unsafe.As<T, Span<byte>>(ref data);
Console.WriteLine($"Span<byte> length: {span.Length}");
span.Fill(0xAA);
}
else if (typeof(T) == typeof(ReadOnlySpan<char>)) {
ReadOnlySpan<char> span = Unsafe.As<T, ReadOnlySpan<char>>(ref data);
Console.WriteLine($"ReadOnlySpan<char> contents: '{span.ToString()}'");
}
else {
Console.WriteLine("Unknown ref struct type.");
}
}
}
// Usage:
Span<byte> bytes = stackalloc byte[8];
var processor1 = new Processor<Span<byte>>();
Console.WriteLine($"Initial Span<byte> contents: {string.Join(", ", bytes.ToArray())}");
processor1.Process(bytes);
Console.WriteLine($"Modified Span<byte> contents: {string.Join(", ", bytes.ToArray())}");
var text = "Hello, C# 13!";
var chars = text.AsSpan();
var processor2 = new Processor<ReadOnlySpan<char>>();
processor2.Process(chars);
// Output:
// Initial Span<byte> contents: 0, 0, 0, 0, 0, 0, 0, 0
// Processing a Span`1
// Span<byte> length: 8
// Modified Span<byte> contents: 42, 42, 42, 42, 42, 42, 42, 42
//
// Processing a ReadOnlySpan`1
// ReadOnlySpan<char> contents: 'Hello, C# 13!'
Note that data needs to be declared as scoped in Process, because Processor is a ref struct and so it can have ref fields. Because T : allows ref struct, data could be a ref struct. If data were not declared as scoped, it could potentially escape the method, violating the ref safety rules. Meaning that processor1.Process(bytes) would be a compile-time error.
What does Unsafe.As<TFrom, TTo> do?
Because ref structs cannot be boxed, you cannot use object and traditional casts. For example, you cannot write:
ReadOnlySpan<char> data = (ReadOnlySpan<char>)(object)someObject;
which would work for regular generic types.
Instead, Unsafe.As<TFrom, TTo> from System.Runtime.CompilerServices.Unsafe is a low-level way to reinterpret the ref T data as a specific type.
Span<byte> span = Unsafe.As<T, Span<byte>>(ref data);
Here, you are telling the compiler: “Trust me, this T really is a Span<byte>.”
ref struct Can Implement Interfaces (C# 13)
Previously, ref struct types were explicitly disallowed from implementing interfaces. This was a critical ref safety rule: converting a ref struct to an interface type would inherently be a boxing conversion (as interfaces are reference types). Allowing this would place a stack-allocated ref struct onto the heap, violating its fundamental “stack-only” guarantee and potentially leading to dangling references if the boxed instance outlived the original stack data.
Beginning with C# 13, ref struct types can declare that they implement interfaces. This is a powerful feature for abstracting common behavior across different ref struct types, enabling more flexible and reusable high-performance code.
However, the compiler’s strict ref safety rules are still maintained during this process:
- No Direct Conversion to Interface Type: A
ref structinstance cannot be directly converted to an interface type. This means you still cannot writeIBufferAccessor accessor = new MyRefBuffer(...);ifMyRefBufferis aref struct. Such a conversion would be a boxing operation and is still forbidden. - Access Through
allows ref structGeneric Parameter: Explicit interface method declarations in aref structcan only be accessed through a generic type parameter that is also constrained byallows ref struct. This ensures that theref structinstance remains on the stack andrefsafe throughout the interface method call.// instead of void Process(IDisposable disposable) { ... } // you would write void Process<T>(scoped T disposable) where T : IDisposable, allows ref struct { ... } - All Methods Must Be Implemented: Unlike classes,
ref structtypes must implement all methods declared in an interface, including those with a default implementation. They cannot rely on default implementations directly; they must provide their own concrete override.
// C# 13: Interface that a ref struct can implement
public interface IBufferReader
{
byte GetByte(int index);
int Length { get; }
// C# 8.0+ allows default implementation in interfaces
void PrintDetails() { Console.WriteLine($"Buffer Length: {Length}"); }
}
// C# 13: A ref struct implementing the IBufferReader interface
public ref struct MyRefByteBuffer : IBufferReader
{
private readonly ReadOnlySpan<byte> _buffer;
public MyRefByteBuffer(ReadOnlySpan<byte> buffer) => _buffer = buffer;
public byte GetByte(int index) => _buffer[index];
public int Length => _buffer.Length;
// IMPORTANT: Ref structs must explicitly implement all interface members,
// even those with default implementations.
public void PrintDetails()
{
Console.WriteLine($"MyRefByteBuffer (Ref Struct) Length: {Length}, First byte: {(Length > 0 ? _buffer[0] : (byte)0)}");
}
}
// C# 13: Generic method to interact with a ref struct via its interface,
// using the 'allows ref struct' constraint.
public static class RefStructInterfaceUtility
{
public static void ProcessRefStructReader<T>(scoped T reader)
where T : IBufferReader, allows ref struct // T must implement IBufferReader AND can be a ref struct
{
reader.PrintDetails(); // Calls the 'ref struct's specific implementation
if (reader.Length > 2)
{
Console.WriteLine($"Byte at index 2: {reader.GetByte(2)}");
}
}
}
// Usage Example (C# 13)
Span<byte> myData = stackalloc byte[] { 0x0A, 0x0B, 0x0C, 0x0D, 0x0E };
var refStructInstance = new MyRefByteBuffer(myData);
RefStructInterfaceUtility.ProcessRefStructReader(refStructInstance);
// Output: MyRefByteBuffer (Ref Struct) Length: 5, First byte: 10
// Output: Byte at index 2: 12
// This would still be a compile-time error, preventing boxing:
// IBufferReader cannotBeBoxed = refStructInstance; // Error: Cannot convert ref struct to interface type.
Use Cases and Trade-offs for High-Performance Structs
Ideal Use Cases:
- Parsing and Serialization: Reading/writing complex binary formats or text protocols directly from/to buffers without intermediate allocations.
- High-Throughput APIs: When every byte and every CPU cycle counts (e.g., networking, game development, scientific computing).
- Interop: Safely interacting with native memory without resorting to full
unsafeblocks. - Custom Memory Views: Creating specialized types that provide safe, type-safe access to slices of memory, analogous to
Span<T>.
Trade-offs and Considerations:
- Steep Learning Curve: Understanding ref-safety rules, lifetimes, and
scopedrequires significant effort. - Strict Compiler Constraints: The
ref structconstraints are severe. They limit how these types can be used, potentially making them incompatible with many standard .NET patterns (e.g., LINQ, asynchronous methods that involve state machines, general-purpose collections). - Limited Generics: While C# 11 improved generic support with
scoped ref, usingref structs with generics remains more complex than with regular types. - Debugging Complexity: Debugging issues related to
reffields and lifetimes can be challenging.
In summary, ref structs, Span<T>, and ref fields are advanced tools for experienced developers building high-performance, low-allocation components. They offer unparalleled efficiency for memory-intensive tasks but demand a thorough understanding of their constraints and the underlying memory model to be used safely and effectively.
8.6. Structs vs. Classes: Choosing the Right Type
The choice between using a struct or a class is one of the most fundamental design decisions in C#. It impacts memory usage, performance, behavior (value vs. reference semantics), and extensibility. There isn’t a universally “better” choice; the optimal selection depends heavily on the specific requirements of your type.
Comprehensive Comparison: Structs vs. Classes
Let’s summarize the key differences:
| Feature | Structs (Value Types) | Classes (Reference Types) |
|---|---|---|
| Fundamental Nature | Value Type | Reference Type |
| Memory Allocation | Stack (locals), inline (fields of structs/classes), ref structs are always stack-only. |
Heap (always) |
Assignment (=) |
Copies the entire value. | Copies the reference (address). |
| Passing to Methods | By default, by value (copy). Can be ref, out, in. |
By default, by reference (reference copy). Can be out, ref. |
null State |
Cannot be null (unless Nullable<T> / T?). |
Can be null. |
| Inheritance | Cannot inherit from other structs/classes (implicitly inherits System.ValueType). |
Supports single inheritance from other classes. |
| Polymorphism | Limited to interface implementation (often involves boxing). | Supports runtime polymorphism (virtual methods, overriding). |
| Boxing/Unboxing | Occurs when converted to object or an interface. Significant perf cost. |
Not applicable (already reference types). |
| Default Constructor | Implicit parameterless ctor (zero-initializes). Can be user-defined (C# 10+). | Implicit parameterless ctor only if no custom ctors. Can be user-defined. |
| Immutability | Encouraged (readonly struct). |
Not inherently immutable, requires design effort. |
| Garbage Collection (GC) | Not directly GC’d (part of stack frame or container). Can be boxed -> GC’d. | Directly managed by GC. |
| Thread Safety | Easier if immutable (no shared mutable state). | Requires careful design (locking, immutable patterns) for shared state. |
sealed Modifier |
Implicitly sealed (cannot be inherited from). |
Can be explicitly sealed to prevent inheritance. |
When to Choose a Struct (The “Struct Guidelines”)
The general guidelines for choosing a struct (recommended by Microsoft and industry experts) are:
- Small Size: The struct should represent a small amount of data, typically 16 bytes or less. This size is a rule of thumb, not a strict limit. Smaller sizes minimize the cost of copying.
- Value Semantics: The type should logically represent a single, atomic value. Its identity should be based on its contents, not its memory location. Examples:
Point,Size,Color,DateTime,Guid. - Immutability (Highly Recommended): For most scenarios, structs should be immutable. This makes their behavior predictable, avoids subtle bugs due to unexpected copies, and facilitates thread safety. Use
readonly struct(C# 7.2+) to enforce this. - No Inheritance/Polymorphism: The type is not expected to have derived types or participate in runtime polymorphism via inheritance (though it can implement interfaces).
- Frequent Creation/Short Lifetime: When instances of the type are created frequently and are short-lived, allocating them on the stack can reduce heap allocation pressure and GC overhead.
Example Use Cases for Structs:
- Coordinates (e.g.,
Point,Vector2) - Measurements (e.g.,
Length,Temperature,Money) - Identifiers (
Guid, customIdtypes) - Colors (
Color) - Optimized low-level APIs (
Span<T>, custom parsers)
When to Choose a Class
Choose a class by default unless your type clearly fits the struct guidelines. Classes are the general-purpose building blocks of OOP in C#.
- Larger Size: If the type holds a significant amount of data, or if its size is likely to grow, a class is usually more appropriate to avoid expensive copies.
- Reference Semantics / Identity: If the type represents an entity with a unique identity, or if multiple variables should refer to the same instance. Examples:
Customer,Order,FileStream. - Mutability: If the type’s state needs to be modified frequently after creation.
- Inheritance/Polymorphism: If the type is part of an inheritance hierarchy or needs to support runtime polymorphism (e.g., base classes, abstract classes).
- Default Nullability: If it’s natural for the type to have a
nullstate. - Lifetime Management: If instances have a long or indeterminate lifetime, or if they participate in complex object graphs.
The Performance Trade-off Debate
- Small Structs often perform better: For very small structs (e.g., 8-16 bytes), avoiding heap allocation and GC cycles is a clear win. They are often passed directly in CPU registers or stack slots, leading to extremely fast operations.
- Large Structs can perform worse: If a struct is large (e.g., 64 bytes), copying it frequently (by default value passing) can be slower than passing a single 8-byte reference to a heap-allocated class. However,
inparameters can mitigate this for large immutable structs. - Boxing is the enemy of Struct Performance: Any operation that forces a struct to be boxed negates many of its performance benefits and adds heap allocation/GC overhead. This is why judicious use of generics,
IEquatable<T>, andref structs is critical.
Conclusion on Choice:
Start with a class by default. Only consider a struct if:
- You understand its value semantics thoroughly.
- It is small and immutable (preferably
readonly record struct). - You have a clear performance justification (e.g., profiling indicates memory allocation/GC is a bottleneck, or you are building high-performance low-level primitives like
Span<T>).
Modern C# features like readonly struct, in parameters, record struct, and ref struct provide powerful tools to leverage the strengths of value types safely and efficiently. However, they also introduce complexity, and the decision to use a struct should be an informed one, weighing performance gains against potential behavioral complexities and the loss of traditional OOP features like inheritance.
Key Takeaways
- Value vs. Reference Types: Structs are value types (data copied, typically stack-allocated), classes are reference types (reference copied, always heap-allocated).
- Memory Layout: Structs are stored directly on the stack as local variables or inlined within other types; classes are always on the managed heap.
- Boxing: Converting a struct to
objector an interface. Incurs heap allocation, copying, and GC overhead, negating struct performance benefits. Avoid where possible using generics,IEquatable<T>, andinparameters. - Struct Constructors: C# 10+ allows explicit parameterless constructors and field initializers. C# 12+ supports Primary Constructors for concise initialization.
readonlyStructs (C# 7.2+): Enforce immutability. All instance fields arereadonly, and instance members are implicitlyreadonly. Crucial for performance withinparameters by avoiding defensive copies.- Parameter Passing:
- By Value (Default): Copies the entire struct. Costly for large structs.
ref/out: Pass by reference, no copy, allows modification.in(C# 7.2+): Pass by read-only reference, no copy, prevents modification. Optimal for passing large, immutable structs.
ref readonlyReturns (C# 7.2+): Returns a read-only reference to a struct, avoiding copying for highly performant scenarios.- Struct Identity (
Equals/GetHashCode): For value types, equality means “same content.” Manual implementation should overrideobject.Equals(),object.GetHashCode(), and implementIEquatable<T>. Always overload==and!=for consistency. record struct(C# 10+): Automatically generates value equality implementations,ToString(), andDeconstruct, reducing boilerplate for data-centric structs.ref struct(C# 7.2+): Stack-only types that cannot be boxed, stored on the heap, or implement interfaces (with exceptions in C# 11 for generics). Used for high-performance, zero-allocation scenarios likeSpan<T>.readonly ref struct: Combines immutability and stack-only guarantees.ref fields(C# 11): Allowsref structs to contain references to other values, enabling advanced low-level optimizations with strict ref-safety rules.- Struct vs. Class Choice: Use
structfor small (<=16 bytes), immutable, value-semantic types where performance is critical. Useclassas the default for larger, mutable, identity-based types that benefit from inheritance and polymorphism. Avoid frequent boxing when using structs.
9. Interfaces: Design, Implementation, and Key Contracts
In the vast landscape of object-oriented programming, interfaces stand as a cornerstone of abstraction, defining contracts that dictate behavior without prescribing implementation. They are fundamental to achieving loose coupling, facilitating polymorphism, and enabling extensible designs. While seemingly straightforward, interfaces in C# possess a depth that extends from their runtime dispatch mechanisms to powerful modern features that redefine their capabilities. This chapter will take you on a comprehensive journey, exploring the anatomy, implementation, type system interactions, and advanced uses of interfaces in C#.
9.1. The Anatomy of an Interface: Contracts Without State
At its core, an interface in C# is a contract. It is a blueprint that defines a set of public members (methods, properties, events, indexers) that an implementing type must provide. Crucially, an interface declares what a type can do, but not how it does it.
- No Instance State (Traditionally): Historically, interfaces in C# (up to C# 7.x) could not contain instance fields, instance constructors, or destructors. They were purely abstract declarations of behavior. This restriction ensured that interfaces remained lightweight contracts, decoupled from any specific implementation state. (With C# 8+, interfaces can have
staticfields for default method support, but still no instance fields). - No Implementation (Traditionally): Similarly, interfaces could not provide any method bodies or property accessors. Every member declared in an interface was implicitly
publicandabstract. (C# 8+ Default Interface Methods relaxed this). - Multiple Inheritance of Contracts: Unlike classes, which support only single inheritance (a class can inherit from only one base class), a C# class or struct can implement multiple interfaces. This allows a type to inherit behaviors from several distinct contracts, fostering a flexible and composable design.
- Purpose:
- Abstraction: Define a common set of behaviors across disparate types.
- Polymorphism: Refer to different types through a common interface reference, allowing code to operate on diverse objects uniformly.
- Loose Coupling: Reduce dependencies between components by programming to interfaces rather than concrete implementations. This enables easier substitution of components.
- Testability: Mock or stub dependencies during unit testing by implementing interfaces.
Consider a simple interface for printable objects:
interface IPrintable
{
// Method signature
void Print();
// Property signature (read-only)
string Content { get; }
// Event signature
event EventHandler Printed;
// Indexer signature
string this[int index] { get; }
}
// A class implementing the interface
class Document : IPrintable
{
private string _content;
private string[] _lines;
public Document(string content)
{
_content = content;
_lines = content.Split('\n');
}
public void Print()
{
Console.WriteLine($"Printing: {_content}");
Printed?.Invoke(this, EventArgs.Empty);
}
public string Content => _content;
public event EventHandler? Printed;
public string this[int index]
{
get
{
if (index < 0 || index >= _lines.Length)
throw new IndexOutOfRangeException();
return _lines[index];
}
}
}
Representation in IL (Intermediate Language)
When a C# interface is compiled, it’s represented in the .NET Intermediate Language (IL) as a type with specific flags. While it doesn’t contain executable code bodies for its members (prior to C# 8), its metadata clearly defines its contract.
An interface is marked with the interface flag and typically the abstract flag in its IL definition. Its members (prior to C# 8) are also marked as abstract and virtual (implicitly public) in IL. The runtime then looks for concrete implementations of these members in types that declare implementation of the interface.
This is fundamentally different from a class, which can have fields (state), constructors, and provide concrete method implementations directly within its type definition. An abstract class is a closer comparison, as it can also have abstract members. However, abstract classes can contain instance fields, constructors, and concrete method implementations (partial implementation), and a class can inherit from only one abstract class. Interfaces, conversely, are purely contractual (traditionally) and allow multiple implementations.
9.2. Interface Dispatch: How Interface Method Calls Work
Understanding how a method call on an interface reference is resolved at runtime is crucial for a deep understanding of polymorphism in C#. This process, known as interface dispatch, is distinct from the more common virtual method dispatch used for class inheritance.
Virtual Method Dispatch (for Classes)
When you call a virtual method on a class instance, the runtime uses a Virtual Method Table (VMT or v-table). Each class that declares or overrides virtual methods has a v-table, which is essentially an array of pointers to the actual method implementations. An object instance carries a pointer to its class’s v-table. When a virtual method is called, the runtime:
- Dereferences the object pointer to get its v-table pointer.
- Looks up the method’s specific index within that v-table (which is fixed at compile time relative to the method’s declaration).
- Calls the method at that address.
This is a very fast, constant-time lookup.
Interface Method Dispatch (IMTs)
Interface dispatch is more complex than v-table dispatch because an interface does not define a fixed layout for method slots in the same way a class hierarchy does. A single class can implement multiple interfaces, and the same interface method might be implemented by different concrete methods in different classes.
The .NET runtime employs Interface Method Tables (IMTs) to resolve interface method calls. Conceptually, for each concrete type that implements one or more interfaces, the runtime constructs a mapping that is discoverable through the object’s runtime type information.
- Object’s MethodTable: Every object on the managed heap carries a pointer to its runtime MethodTable. This
MethodTable(also sometimes referred to as a “type object” or “type handle”) is a comprehensive data structure containing all metadata about the object’s exact type, including its class hierarchy, field layouts, and the Virtual Method Table (VMT). - Interface Map within MethodTable: Within the
MethodTable, there’s a specialized data structure, often called an “interface map” or “interface dispatch map.” This map provides efficient lookup for interfaces implemented by that type. - IMT Lookup: When an interface method is called on an object:
- The runtime identifies the interface being invoked (from the call site’s compile-time context).
- It then uses the object’s
MethodTableto navigate its interface map and locate the specific IMT for that interface for the object’s concrete runtime type. This IMT itself is an array or table. - IMT Slot Resolution: This specific IMT contains a precise mapping: for each method slot defined in that interface, it stores the memory address of the corresponding method implementation within the concrete class.
- Method Call: The method at that resolved address is then called.
This process, involving navigation through the object’s MethodTable to its interface map and then to the specific IMT, means interface dispatch involves more indirection than a simple v-table lookup. While highly optimized by the JIT compiler (often through techniques like “devirtualization” where the concrete type is known, or specialized code for common interface types), it generally involves slightly more overhead than direct v-table calls.
Example:
interface IShape { void Draw(); }
interface IResizable { void Resize(); }
class Circle : IShape, IResizable
{
public void Draw() { Console.WriteLine("Drawing Circle"); }
public void Resize() { Console.WriteLine("Resizing Circle"); }
}
class Square : IShape
{
public void Draw() { Console.WriteLine("Drawing Square"); }
}
void DemonstrateBasicDispatch()
{
IShape shape1 = new Circle(); // Compiler sees IShape, runtime knows it's Circle
IShape shape2 = new Square(); // Compiler sees IShape, runtime knows it's Square
// When shape1.Draw() is called:
// 1. Runtime uses shape1's MethodTable (for type Circle).
// 2. Finds the interface map in Circle's MethodTable.
// 3. Locates the IMT for IShape within Circle's interface map.
// 4. Looks up the 'Draw' method slot in IShape's IMT.
// 5. Calls Circle's Draw() implementation at the resolved address.
shape1.Draw(); // Output: Drawing Circle
// Similar process for shape2.Draw()
shape2.Draw(); // Output: Drawing Square
}
Interface Methods as Virtual Class Methods
An interesting and common scenario arises when a class implements an interface method, and that implementation is itself declared as virtual in the class hierarchy. This allows derived classes to override the interface’s implementation through standard class inheritance mechanisms, while still being callable polymorphically via the interface.
Consider the following:
- An interface
IActiondefines a methodPerform(). - A
BaseClassimplementsIAction.Perform()and declares this implementation aspublic virtual void Perform(). - A
DerivedClassinherits fromBaseClassandoverridesPerform().
When Perform() is called via an IAction interface reference, how is the correct method (e.g., DerivedClass.Perform()) resolved?
The resolution still begins with Interface Method Dispatch (IMT). The IMT for the concrete type will map the interface method slot directly to the most derived actual implementation method in the class’s virtual method table (VMT).
Detailed steps for IAction.Perform() call on an instance of DerivedClass:
- IMT Lookup: The runtime identifies the interface being called (
IAction) and the concrete runtime type of the object (DerivedClass). - IMT Mapping: The runtime uses
DerivedClass’sMethodTableto find the specific IMT for theIActioninterface. This IMT contains an entry forIAction.Perform(). - VMT Entry: This IMT entry for
DerivedClasspoints directly to the memory address ofDerivedClass.Perform()withinDerivedClass’s virtual method table. Even thoughDerivedClass.Perform()is an override of a virtual method originally defined inBaseClass(which happens to implementIAction), the IMT forDerivedClasswill point to the final, overridden method. - Direct Call: The method at that address (
DerivedClass.Perform()) is then invoked.
Crucially, the IMT does not point to BaseClass.Perform() which then performs another virtual dispatch. Instead, for a given concrete type, the IMT entry for an interface method directly reflects the result of class virtual dispatch for that method within that type’s hierarchy. The runtime ensures that the IMT for any derived type correctly points to the ultimate override.
Example:
interface ILogger {
void Log(string message);
}
class BaseLogger : ILogger {
// Implicitly implements ILogger.Log, and makes it virtual
public virtual void Log(string message) {
Console.WriteLine($"[Base] {message}");
}
}
class AdvancedLogger : BaseLogger {
// Overrides the virtual Log method from BaseLogger
public override void Log(string message) {
Console.WriteLine($"[Advanced] {message.ToUpper()}");
}
}
class DebugLogger : BaseLogger, IDisposable {
// Another override example
public override void Log(string message) {
Console.WriteLine($"[DEBUG] {message}");
}
public void Dispose() {
Console.WriteLine("DebugLogger disposed.");
}
}
void DemonstrateVirtualInterfaceDispatch()
{
BaseLogger baseLog = new BaseLogger();
AdvancedLogger advancedLog = new AdvancedLogger();
DebugLogger debugLog = new DebugLogger();
// Call via concrete types (standard virtual dispatch)
baseLog.Log("Hello from Base"); // Output: [Base] Hello from Base
advancedLog.Log("Hello from Advanced"); // Output: [Advanced] HELLO FROM ADVANCED
debugLog.Log("Hello from Debug"); // Output: [DEBUG] Hello from Debug
Console.WriteLine("--- Via Interface Reference ---");
// Call via interface references (interface dispatch)
ILogger iBaseLog = baseLog;
ILogger iAdvancedLog = advancedLog;
ILogger iDebugLog = debugLog;
iBaseLog.Log("Interface call for Base"); // Output: [Base] Interface call for Base
iAdvancedLog.Log("Interface call for Advanced"); // Output: [Advanced] INTERFACE CALL FOR ADVANCED
iDebugLog.Log("Interface call for Debug"); // Output: [DEBUG] Interface call for Debug
// Even though the calls are made through the ILogger interface,
// the runtime correctly dispatches to the most derived *virtual* implementation
// of the Log method, because the IMT for each specific concrete type (AdvancedLogger, DebugLogger)
// points to the final overridden method in their respective class hierarchies.
}
This behavior ensures that polymorphism works seamlessly, whether you’re calling a method through a base class reference or an interface reference. The IMT for a given type effectively “knows” the result of its own class’s virtual method dispatch, leading to the correct and most specialized method being invoked.
9.3. Interface Type Variables and Casting
Interfaces are types themselves, which means you can declare variables of an interface type. These variables can then hold references to instances of any class or struct that implements that interface. This capability is fundamental to polymorphism in C#.
Declaring and Assigning Interface Variables
You declare an interface variable just like any other variable:
// Declaring a variable of interface type
IPrintable myPrintableObject;
// Assigning an instance of a class that implements the interface
Document doc = new Document("Hello Interface");
myPrintableObject = doc; // Implicit upcasting (safe)
// myPrintableObject now refers to the same Document object.
myPrintableObject.Print(); // Calls Document's Print method
Console.WriteLine(myPrintableObject.Content); // Calls Document's Content getter
This is an implicit upcast, which is always safe because Document is guaranteed to have all members defined by IPrintable.
Casting Interface Variables
Casting allows you to convert a variable from one type to another. When working with interfaces, casting becomes crucial for changing the compile-time view of an object, either up the inheritance hierarchy (to a less specific type) or down (to a more specific type).
-
Upcasting (Implicit): As seen above, assigning a concrete type instance to an interface variable (or a base interface variable) is an implicit upcast. It’s safe because the target type (interface) is a subset of the source type’s capabilities.
Document myDocument = new Document("Chapter 9"); IPrintable printableDoc = myDocument; // Implicit upcast to IPrintable object objDoc = myDocument; // Implicit upcast to object -
Downcasting (Explicit): Converting an interface type variable to a more specific type (either a concrete class/struct or a more derived interface) requires an explicit cast. This is because the compiler cannot guarantee at compile time that the object referred to by the interface variable is actually of the target type.
-
asoperator: Attempts the cast. If successful, it returns a reference to the target type; otherwise, it returnsnull. This is generally preferred when you can handlenullgracefully, as it avoids exceptions.IPrintable maybeDoc = new Document("Some text"); Document? actualDoc = maybeDoc as Document; // Attempt to downcast if (actualDoc != null) { Console.WriteLine($"Successfully cast to Document: {actualDoc.Content}"); } else { Console.WriteLine("Could not cast to Document."); } - Explicit Cast
(): Performs the cast. If the object is not compatible with the target type at runtime, anInvalidCastExceptionis thrown. Use this when you are certain the cast will succeed, or when an exception is the desired failure mechanism.IPrintable mustBeDocument = new Document("Crucial data"); try { Document sureDoc = (Document)mustBeDocument; // Explicit cast Console.WriteLine($"Explicitly cast: {sureDoc.Content}"); } catch (InvalidCastException) { Console.WriteLine("Invalid cast attempted!"); } -
isoperator: Checks if an object is compatible with a given type (interface or class) without performing the cast. It’s often used in conjunction with a pattern match (C# 7.0+) to combine the check and the cast concisely.IPrintable item = new Document("Draft"); if (item is Document docInstance) // 'is' with pattern matching { Console.WriteLine($"Item is a Document: {docInstance.Content}"); } else if (item is IDisposable disposableItem) { Console.WriteLine("Item is IDisposable."); disposableItem.Dispose(); }
-
-
Casting Between Interfaces: You can cast an interface variable to another interface type if the underlying concrete object implements both interfaces.
interface IReloadable { void Reload(); } class ReloadableDocument : Document, IReloadable { public void Reload() { Console.WriteLine("Reloading document."); } } IPrintable currentItem = new ReloadableDocument("Configuration"); if (currentItem is IReloadable reloadableItem) { reloadableItem.Reload(); // Output: Reloading document. }
Boxing of Value Types with Interfaces
This is a critical consideration for performance and correctness when structs implement interfaces.
When a value type (struct) is assigned to a variable of an interface type (or object type), it undergoes a process called boxing.
-
Boxing: The entire value of the
structis copied from its stack-allocated location into a newly allocated object on the managed heap. A reference to this new heap object is then stored in the interface variable.- Performance Impact: Boxing incurs two significant costs:
- Heap Allocation: Allocating memory on the garbage-collected heap. This adds pressure on the Garbage Collector (GC).
- Copying: Copying the entire
struct’s data from the stack to the heap. For large structs, this can be substantial.
- GC Overhead: The newly boxed object on the heap will eventually need to be garbage collected, adding to GC work.
- Performance Impact: Boxing incurs two significant costs:
-
Unboxing: The reverse process. When a boxed value type is cast back to its original value type, the data is copied from the heap-allocated object back to a new stack-allocated
structinstance.- Performance Impact: Also involves copying and a runtime type check.
Example of Boxing:
interface ICounter
{
int Count { get; set; }
void Increment();
}
struct SimpleCounter : ICounter
{
public int Count { get; set; }
public void Increment()
{
Count++;
}
}
void DemonstrateBoxing()
{
SimpleCounter myStructCounter = new SimpleCounter { Count = 5 }; // Struct on the stack
Console.WriteLine($"Original struct: {myStructCounter.Count}"); // Output: 5
ICounter boxedCounter = myStructCounter; // BOXING OCCURS HERE! myStructCounter is copied to heap.
boxedCounter.Increment(); // This increments the Count of the *boxed copy* on the heap.
Console.WriteLine($"Boxed counter (via interface): {boxedCounter.Count}"); // Output: 6
// The original struct on the stack remains unchanged!
Console.WriteLine($"Original struct after boxed increment: {myStructCounter.Count}"); // Output: 5
// To get the updated value back, you'd need to unbox and assign:
myStructCounter = (SimpleCounter)boxedCounter; // UNBOXING OCCURS HERE! Data copied from heap.
Console.WriteLine($"Original struct after unboxing and assignment: {myStructCounter.Count}"); // Output: 6
}
This behavior (modifying the boxed copy, not the original) is a common source of subtle bugs when working with mutable structs and interfaces. It’s a strong reason why structs should generally be immutable if they are likely to be used with interfaces or object references. Furthermore, it highlights why features like ref structs (covered in Chapter 8) and in parameters were introduced, to allow efficient ref-based access to value types without boxing.
9.4. Explicit vs. Implicit Implementation
When a class or struct implements an interface, it must provide concrete implementations for all the interface’s members. C# offers two ways to do this: implicit implementation and explicit implementation.
Implicit Implementation
This is the default and most common way to implement an interface. The implementing type declares a public member with the same signature as the interface member. This member is then accessible both via the class/struct instance directly and via an interface reference.
Characteristics:
- Member is
public. - Accessible through the concrete type directly (
myClass.Print()). - Accessible through the interface reference (
myInterface.Print()). - Suitable when there are no naming conflicts with other members or interfaces, and the member is part of the type’s public API.
interface ILogger
{
void Log(string message);
}
class ConsoleLogger : ILogger
{
// Implicit implementation
public void Log(string message)
{
Console.WriteLine($"ConsoleLog: {message}");
}
}
// Usage
void UseImplicitLogger()
{
ConsoleLogger logger = new ConsoleLogger();
logger.Log("Hello from ConsoleLogger (direct)"); // Access via class instance
ILogger iLogger = logger;
iLogger.Log("Hello from ConsoleLogger (interface)"); // Access via interface reference
}
Explicit Implementation
Explicit implementation involves specifying the interface name when implementing a member (e.g., IMyInterface.MyMethod()). This makes the member accessible only when the type is accessed through a reference of that specific interface type. It is not directly accessible via the concrete class instance.
Characteristics:
- Member is not
public(it has no access modifier in the declaration, and it’s implicitly part of the interface’s contract). - Accessible only through an interface reference (
myInterface.Log("...")). - Not directly accessible through the concrete type’s instance (
myClass.Log("...")will not work for explicitly implemented members). - Useful for:
- Resolving Naming Conflicts: When a class implements two interfaces that declare members with identical signatures.
- Hiding Interface Members: When an interface member is not part of the class’s primary public API and should only be exposed when interacting with the type polymorphically via the interface. A classic example is
IDisposable.Dispose(), which is often explicitly implemented whenusingstatements are the primary means of disposal, and a publicDispose()method is not desired for direct calling.
interface IReader {
public void Close();
}
interface IWriter {
public void Close();
}
class ConsoleReaderWriter : IReader, IWriter {
void IReader.Close() { ... }
void IWriter.Close() { ... }
public void Close() {
((IReader) this).Close();
((IWriter) this).Close();
}
}
// Usage
var readerWriter = new ConsoleReaderWriter();
readerWriter.Close(); // Calls ConsoleReaderWriter.Close()
// Explicitly calling IReader.Close()
((IReader)readerWriter).Close();
In scenarios with name conflicts, explicit implementation clearly disambiguates which interface’s member is being implemented. For hiding, it prevents users of the concrete class from accidentally calling a member that is conceptually tied to an interface contract.
9.5. Interfaces and Inheritance
The power of interfaces is significantly amplified when combined with class inheritance and when interfaces themselves participate in an inheritance hierarchy. Understanding these interactions is key to designing robust and flexible type systems.
9.5.1. Interface Inheritance
Interfaces can inherit from other interfaces. An interface inherits all members of its base interfaces, and any type implementing the derived interface must provide implementations for all members in the entire inheritance chain.
interface IFile
{
string FileName { get; }
void Open();
void Close();
}
interface IEditableFile : IFile // IEditableFile inherits FileName, Open, Close
{
void Save();
void EditContent(string newContent);
}
class TextFile : IEditableFile
{
public string FileName { get; private set; }
private string _content = "";
public TextFile(string fileName) { FileName = fileName; }
// IFile members
public void Open() { Console.WriteLine($"Opening {FileName}"); }
public void Close() { Console.WriteLine($"Closing {FileName}"); }
// IEditableFile members
public void Save() { Console.WriteLine($"Saving {FileName}"); }
public void EditContent(string newContent)
{
_content = newContent;
Console.WriteLine($"Editing {FileName}: '{_content}'");
}
}
// Usage
void UseFileInterfaces()
{
TextFile file = new TextFile("myDoc.txt");
file.Open();
file.EditContent("New text");
file.Save();
file.Close();
IFile iFile = file;
iFile.Open(); // Calls TextFile.Open()
IEditableFile iEditableFile = file;
iEditableFile.EditContent("More text"); // Calls TextFile.EditContent()
}
Here, TextFile must implement all members from both IFile and IEditableFile.
9.5.2. Mixing Class Inheritance and Interface Implementation
A common scenario involves classes that both inherit from a base class and implement one or more interfaces. The method resolution order becomes important here.
interface ILoggable
{
void LogMessage(string message);
}
class BaseEntity : ILoggable
{
public string Id { get; set; } = Guid.NewGuid().ToString();
// Implicitly implements ILoggable.LogMessage
public void LogMessage(string message)
{
Console.WriteLine($"BaseEntity Log [{Id}]: {message}");
}
}
class User : BaseEntity
{
public string UserName { get; set; } = string.Empty;
}
class Product : BaseEntity, IDisposable // Product implements IDisposable
{
public string Name { get; set; } = string.Empty;
public void Dispose()
{
Console.WriteLine($"Product '{Name}' ({Id}) is being disposed.");
}
}
// Usage
void DemonstrateMixedInheritance()
{
User user = new User { UserName = "Alice" };
user.LogMessage($"User {user.UserName} created."); // Calls BaseEntity's LogMessage
ILoggable loggableUser = user;
loggableUser.LogMessage($"User {user.UserName} accessed via ILoggable."); // Calls BaseEntity's LogMessage
Product product = new Product { Name = "Laptop" };
product.LogMessage($"Product {product.Name} added."); // Calls BaseEntity's LogMessage
product.Dispose(); // Calls Product's Dispose
IDisposable disposableProduct = product;
disposableProduct.Dispose(); // Calls Product's Dispose
// Product inherits the ILoggable implementation from BaseEntity
ILoggable loggableProduct = product;
loggableProduct.LogMessage($"Product {product.Name} accessed via ILoggable."); // Calls BaseEntity's LogMessage
}
In this example, User and Product both inherit the ILoggable implementation from BaseEntity. Product then additionally implements IDisposable.
9.5.3. Re-implementing Inherited Interfaces
Imagine the following scenario:
interface IClosable {
void Close();
}
class Reader : IClosable {
public void Read(string data) {
Console.WriteLine($"Reading data: {data}");
}
public void Close() {
Console.WriteLine("Disposing Reader resources.");
}
}
class SavableReader : Reader {
public void Save(string filePath) {
Console.WriteLine($"Saving data to {filePath}");
}
}
static void CloseReader(IClosable closable) {
closable.Close();
}
When we have a variable of type IClosable which contains an instance of SavableReader, we can call Close() on it, which will invoke the Close() method from Reader:
var savableReader = new SavableReader();
savableReader.Read("Sample data");
savableReader.Save("output.txt");
CloseReader(savableReader); // Calls Reader's Close method
// Output:
// Reading data: Sample data
// Saving data to output.txt
// Disposing Reader resources.
This is expected behavior. Now imagine that someone else comes along and decides to create an improved version of this class, which can also write data and therefore has a more sophisticated close operation:
class AdvancedReader : Reader {
public void Write(string data) {
Console.WriteLine($"Writing data: {data}");
}
public new void Close() {
Console.WriteLine("AdvancedReader closing with additional cleanup.");
}
}
Because the original author of Reader did not mark the Close() method as virtual, the new Close() method in AdvancedReader does not override the original. Instead, it hides it. This means that if we call Close() on an instance of AdvancedReader through an IClosable reference, it will still call the original Close() method from Reader.
var advancedReader = new AdvancedReader();
CloseReader(advancedReader); // Calls Reader's Close method, not AdvancedReader's
// Output:
// Disposing Reader resources.
Thankfully, C# provides a way to ensure that the new Close() method in AdvancedReader can be called when we have an IClosable reference. We can explicitly re-implement the interface in AdvancedReader:
class AdvancedReader : Reader, IClosable {
public void Write(string data) {
Console.WriteLine($"Writing data: {data}");
}
public new void Close() {
Console.WriteLine("AdvancedReader closing with additional cleanup.");
}
}
Now when we call Close() on an IClosable reference that contains an instance of AdvancedReader, it will invoke the new Close() method:
var advancedReader = new AdvancedReader();
CloseReader(advancedReader); // Calls AdvancedReader's Close method
// Output:
// AdvancedReader closing with additional cleanup.
9.6. Modern Interface Features
C# has significantly evolved interfaces in recent versions, transforming them from purely abstract contracts into more versatile constructs. These enhancements, primarily Default Interface Methods (DIMs) in C# 8 and Static Abstract/Virtual Members in C# 11, address long-standing challenges and enable entirely new programming paradigms.
9.6.1. Default Interface Methods (DIM) (C# 8)
Before C# 8, adding a new member to an interface was a breaking change: all existing implementers would immediately fail to compile unless they provided an implementation for the new member. Default Interface Methods (DIMs) resolve this problem by allowing interfaces to provide a default implementation for a member.
Motivation:
- Interface Evolution: Add new functionality to an interface without breaking compatibility with existing consumers who might not yet be updated to implement the new members.
- Mixins/Traits (Partial): Provide common, reusable implementations for certain behaviors that can be “mixed in” to types that implement the interface.
How it Works:
- You can now define method bodies, property accessors, or event accessors directly within an interface.
- Implementing types can choose to:
- Not implement the member: In this case, the default implementation from the interface is used.
- Explicitly implement the member: Provides a custom implementation.
- Implicitly implement the member: Provides a custom implementation. If the default implementation is
virtualin the interface, an implicit public implementation in a class overrides the default.
Calling DIMs:
- Crucially, default implemented methods can only be called via an interface reference. You cannot call a default implemented method directly on the concrete type unless that type explicitly implements or overrides it.
Other Members in Interfaces (C# 8): To support DIMs, interfaces can now also contain:
privatemembers: For helper methods used by default implementations.staticmembers: For utility methods or properties related to the interface. These are also only accessible via the interface type itself (IConvertible.IsConvertible).abstractandvirtualmodifiers for interface members.
“Diamond Problem” Mitigation: When a class inherits a default implementation from multiple interfaces that define the same method (the “diamond problem”), C# resolves this by requiring the implementing class to provide its own explicit implementation of the conflicting method. This forces a clear choice, avoiding ambiguity.
DIMs and Inheritance: If a base class implements an interface with DIMs, derived classes inherit the base class’s implementation (if it exists) or rely on the DIM if the base class does not implement it. If a derived class itself explicitly re-implements the interface, it can provide its own implementation for DIMs.
interface ILogger
{
void Log(string message); // Abstract method (no default)
// Default interface method (DIM)
void LogWarning(string message)
{
Console.ForegroundColor = ConsoleColor.Yellow;
Log($"WARNING: {message}"); // Calls the abstract Log()
Console.ResetColor();
}
// Private helper for a DIM
private string FormatMessage(string message) => $"[Log] {message}";
// Another DIM that uses the private helper
void LogInfo(string message)
{
Console.WriteLine(FormatMessage(message));
}
}
class SimpleLogger : ILogger
{
// Implicit implementation for the abstract Log method
public void Log(string message)
{
Console.WriteLine($"SimpleLog: {message}");
}
// SimpleLogger does not implement LogWarning or LogInfo.
// It will use the default implementations provided by ILogger.
}
class AdvancedLogger : ILogger
{
public void Log(string message)
{
Console.WriteLine($"AdvancedLog: {message}");
}
// Explicitly override the default LogWarning implementation
void ILogger.LogWarning(string message)
{
Console.ForegroundColor = ConsoleColor.Red;
Log($"CRITICAL WARNING: {message}"); // Calls this class's Log()
Console.ResetColor();
}
}
// Usage
void UseDIMs()
{
ILogger logger1 = new SimpleLogger();
logger1.Log("Hello"); // Output: SimpleLog: Hello
logger1.LogWarning("Disk full"); // Output: WARNING: SimpleLog: Disk full (uses DIM)
logger1.LogInfo("Info message"); // Output: [Log] Info message
ILogger logger2 = new AdvancedLogger();
logger2.Log("Test"); // Output: AdvancedLog: Test
logger2.LogWarning("Memory low"); // Output: CRITICAL WARNING: AdvancedLog: Memory low (uses explicit override)
// ((AdvancedLogger)logger2).LogWarning("Memory low"); // COMPILE ERROR: Direct call not allowed for DIM unless explicitly implemented
}
DIMs represent a powerful evolution, allowing interfaces to grow over time without forcing breaking changes on existing consumers.
9.6.2. Static Abstract & Virtual Members in Interfaces (C# 11)
Perhaps the most significant transformation of interfaces since their inception, C# 11 introduced the ability to declare static abstract and static virtual members in interfaces. This seemingly small change has profound implications, primarily enabling the concept of Generic Math in .NET.
Motivation:
Prior to C# 11, it was impossible to write generic code that performed mathematical operations on arbitrary numeric types (e.g., T Add<T>(T a, T b)). This was because operators like + are static methods, and there was no way to define a generic constraint that guaranteed a type would implement a static operator. Static abstract interface members solve this problem.
How it Works:
static abstractmembers: An interface can declare astatic abstractmethod, property, or operator. This mandates that any type implementing this interface must provide a static implementation for that member.static virtualmembers: An interface can provide a default static implementation for a member. Implementing types can then choose to use the default or provide their own static override. Note that the actualoverridekeyword is omitted.static sealedmembers: Astaticmember with an implementation in an interface that cannot be overridden by implementing types.
interface ICalculator {
void Calculate(/*implicit ICalculator this*/, int value);
static abstract void Reset(); // no implicit ICalculator this !!!
}
class SimpleCalculator : ICalculator {
public void Calculate(/*implicit SimpleCalculator this*/, int value) { ... }
public static void Reset() { ... } // no implicit SimpleCalculator this !!!
}
SimpleCalculator calc = new SimpleCalculator();
calc.Reset(); // error
SimpleCalculator.Reset(); // ok
Calling these Members:
staticmembers in interfaces are invoked directly on the interface type itself.- They are primarily used within generic contexts where the type parameter is constrained to implement the interface. The generic type parameter must also satisfy the
TSelforTSelf derived from IMyInterface<TSelf>constraint, introduced with this feature.
The TSelf Constraint:
A crucial part of Generic Math and static abstract interfaces is the TSelf constraint (or more generally, TSelf : IMyInterface<TSelf>). This constraint ensures that the generic type TSelf is actually the type implementing the interface. This allows the compiler to resolve static method calls correctly, as static methods are invoked on the type itself, not an instance.
interface IOperator<TSelf> where TSelf : IOperator<TSelf> {
static abstract int Value { get; }
static virtual int Operation(int n) {
return TSelf.Value * n; // multiply by default
}
}
class DefaultMultiplier : IOperator<DefaultMultiplier> {
public static int Value { get; } = 5;
// Operation uses the default implementation from the interface --> multiply by 5
}
class CustomAdder : IOperator<CustomAdder> {
public static int Value { get; } = 3;
public static int Operation(int n) { // no need to override
return CustomAdder.Value + n; // different implementation
}
}
Example: Simplified Generic Math
Imagine you want to sum a list of numbers, regardless of whether they are int, double, decimal, etc. Before C# 11, you’d need separate methods or reflection. With C# 11, the System.Numerics namespace provides interfaces like IAdditionOperators<TSelf, TOther, TResult> that define static operators.
// A generic method that can sum any type implementing IAdditionOperators
static T SumAll<T>(IEnumerable<T> values)
where T : System.Numerics.IAdditionOperators<T, T, T>,
System.Numerics.INumber<T> // INumber<T> provides T.Zero
{
T sum = T.Zero; // Initialize sum using the static 'Zero' property from INumber<T>
foreach (T value in values) {
sum += value; // This 'sum += value' is resolved via the static abstract operator+
// defined in IAdditionOperators<T, T, T>
}
return sum;
}
// Usage with built-in types (which implicitly implement System.Numerics interfaces)
void DemonstrateGenericMath()
{
List<int> intList = new List<int> { 1, 2, 3 };
int intSum = SumAll(intList);
Console.WriteLine($"Sum of ints: {intSum}"); // Output: 6
List<double> doubleList = new List<double> { 1.5, 2.5, 3.0 };
double doubleSum = SumAll(doubleList);
Console.WriteLine($"Sum of doubles: {doubleSum}"); // Output: 7.0
List<decimal> decimalList = new List<decimal> { 0.1m, 0.2m, 0.3m };
decimal decimalSum = SumAll(decimalList);
Console.WriteLine($"Sum of decimals: {decimalSum}"); // Output: 0,6
}
This powerful feature allows for writing truly generic algorithms that operate on common operations across diverse types, without relying on boxing/unboxing, reflection, or type-specific implementations. It is a cornerstone of performance-critical libraries that need to be type-agnostic yet numerically aware.
Trade-offs and Considerations for Modern Features:
- Increased Complexity: While powerful, these features add conceptual complexity to interfaces. Understanding when to use a DIM versus a regular method, or a
static abstractversus astaticmethod, requires deeper insight. - Dispatch Overhead: While optimized, the runtime overhead of interface dispatch (especially for DIMs or static abstract calls) can still be slightly higher than direct method calls on concrete types in extreme performance-sensitive scenarios, though this is rarely a bottleneck for typical applications.
- “Diamond Problem” (DIMs): While mitigated by explicit implementation requirements, designing interfaces with complex default hierarchies can still lead to confusion if not carefully planned.
Modern interface features represent a strategic evolution of the C# language, empowering developers to write more abstract, reusable, and performant code, particularly in scenarios that were previously cumbersome or impossible.
Key Takeaways
- Interfaces as Contracts: Define public members without instance state, enabling abstraction, polymorphism, and loose coupling.
- Interface Variables and Casting: Interface variables can hold references to implementing types. Upcasting is implicit, downcasting requires explicit cast (
asor()) orisoperator for runtime safety checks. - Boxing of Value Types: Assigning a
structto an interface variable (orobject) boxes it, copying its data to the heap. This incurs performance overhead (allocation, GC pressure, copying) and can lead to subtle bugs with mutable structs, as changes apply to the boxed copy, not the original. - Interface Dispatch (IMTs): Interface method calls are resolved at runtime via Interface Method Tables (IMTs), a mapping mechanism distinct from class v-tables, allowing for polymorphic calls across multiple interface implementations.
- Implicit vs. Explicit Implementation:
- Implicit:
publicmember in the class; accessible via class instance and interface reference. - Explicit:
InterfaceName.MemberName; accessible only via an interface reference. Used for naming conflicts or hiding implementation details.
- Implicit:
- Interface Inheritance: Interfaces can inherit from other interfaces, requiring implementers to provide all members in the chain.
- Mixing Class Inheritance and Interfaces: Classes can inherit from a base class and implement interfaces. Method resolution prioritizes inherited members and then interface implementations.
- Re-implementing Inherited Interfaces:
- If a base class implicitly implements an interface, derived classes inherit that implementation and cannot explicitly re-implement; they must
override(if virtual) ornew(hiding, but breaking polymorphism for interface reference). - If a base class explicitly implements an interface, derived classes can choose to explicitly or implicitly re-implement it, effectively taking ownership of the interface contract for their instances.
- If a base class implicitly implements an interface, derived classes inherit that implementation and cannot explicitly re-implement; they must
- Default Interface Methods (DIMs) (C# 8): Allow interfaces to provide default implementations for members, enabling interface evolution without breaking existing code. Callable only via interface reference. Interfaces can also contain
privateandstaticmembers to support DIMs. - Static Abstract & Virtual Members in Interfaces (C# 11): A major feature enabling generic polymorphism on static methods (e.g., operators) via the
TSelfconstraint. This is the foundation for Generic Math, allowing algorithms to operate universally on numeric types.
10. Essential C# Interfaces: Design and Usage Patterns
The .NET Base Class Library (BCL) is the bedrock of C# development, offering a vast array of fundamental types and interfaces that underpin almost every application. Beyond merely providing utility, these BCL components embody mature design patterns, optimize common operations, and facilitate interoperability. A deep understanding of their contracts, internal workings, and typical usage scenarios is crucial for writing robust, performant, and maintainable C# code. This chapter delves into some of the most critical BCL interfaces, exploring their design principles, implementation considerations, and best practices.
10.1. Core Interfaces: Comparing, Formatting, and Parsing
Many fundamental value types in the BCL (like int, double, DateTime, Guid, structs you define) implement a set of core interfaces that enable standard behaviors for comparison, formatting, and parsing. These interfaces establish contracts that the C# compiler and runtime leverage for various operations.
10.1.1. IComparable<T>, IComparer<T>, and IEquatable<T>: Defining Order and Equality
These three interfaces are paramount for types that need to be compared or checked for equality, especially when used in collections, sorting, or hash-based lookups.
-
IComparable<T>:- Purpose: Defines a generalized comparison method that a value type or class implements to create a type-specific ordering. It allows instances of the type to be sorted according to their natural or intrinsic order.
- Contract: Requires implementation of a single method:
int CompareTo(T? other);This method returns:
- A negative integer if the current instance precedes
other. - Zero if the current instance has the same order as
other. - A positive integer if the current instance follows
other.
- A negative integer if the current instance precedes
- Importance: Essential for types used in sorted collections like
SortedList<TKey, TValue>,SortedDictionary<TKey, TValue>, or when callingList<T>.Sort()(without arguments),Array.Sort()(without arguments), andEnumerable.OrderBy(). Without it, these operations would fall back to less efficient or less meaningful comparisons (e.g., hash codes, reflection, or requiring a customIComparer<T>). IComparable(Non-Generic): The older, non-generic versionIComparableexists and requiresint CompareTo(object? obj). For value types, implementing this version incurs boxing overhead when theobjparameter is passed, as the value type must be boxed toobject. Always preferIComparable<T>for type safety and performance. If you must support both, implementIComparable<T>explicitly and haveIComparable.CompareTocall the generic version after a type check.- Implementation Design: For value types, ensuring a consistent and meaningful ordering is critical. For reference types, decide if the comparison is by value (content) or by reference (identity).
record struct Point3D(int X, int Y, int Z) : IComparable<Point3D> { public int CompareTo(Point3D other) { // Primary sort by X, then Y, then Z int result = X.CompareTo(other.X); if (result != 0) return result; result = Y.CompareTo(other.Y); if (result != 0) return result; return Z.CompareTo(other.Z); } } void DemonstrateComparable() { List<Point3D> points = new() { new(1, 2, 3), new(1, 1, 5), new(2, 0, 0), new(1, 2, 1) }; points.Sort(); // Uses Point3D.CompareTo for its natural order foreach (var p in points) { Console.WriteLine($"Point: ({p.X}, {p.Y}, {p.Z})"); } // Output: // Point: (1, 1, 5) // Point: (1, 2, 1) // Point: (1, 2, 3) // Point: (2, 0, 0) } -
IComparer<T>: Providing External or Alternative Orderings- Purpose: Defines a method that a comparer class implements to provide a generalized comparison method for two objects of a specific type. Unlike
IComparable<T>, which defines an intrinsic order within the type itself,IComparer<T>provides an extrinsic or alternative way to compare objects. - Contract: Requires implementation of a single method:
int Compare(T? x, T? y);This method returns:
- A negative integer if
xprecedesy. - Zero if
xhas the same order asy. - A positive integer if
xfollowsy.
- A negative integer if
- Importance:
- When a type does not implement
IComparable<T>(e.g., a third-party class you cannot modify). - When you need to sort a type in multiple different ways (e.g., sort
PersonbyLastNamethenFirstName, or byAge). - When you need to provide a custom comparison for a type that does implement
IComparable<T>, but you want a different ordering for a specific scenario.
- When a type does not implement
- Usage with
IComparable<T>: AnIComparer<T>implementation can leverage theIComparable<T>implementation of the type it compares. For example, a comparer could sort by one property using itsCompareTomethod, and then by another property, using its ownCompareTomethod, providing a multi-level sort. - Methods that accept
IComparer<T>: Many BCL methods and constructors allow you to pass anIComparer<T>instance:List<T>.Sort(IComparer<T>),Array.Sort(IComparer<T>),SortedList<TKey, TValue>(IComparer<TKey>),SortedDictionary<TKey, TValue>(IComparer<TKey>),HashSet<T>(IComparer<T>)(though less common forHashSet), and LINQ methods likeOrderBy(..., IComparer<T>)andThenBy(..., IComparer<T>).
record class Person(string FirstName, string LastName, int Age); // Comparer to sort people by Last Name, then First Name class LastNameComparer : IComparer<Person> { public int Compare(Person? x, Person? y) { if (x is null && y is null) return 0; if (x is null) return -1; // null is less than non-null if (y is null) return 1; // non-null is greater than null int result = x.LastName.CompareTo(y.LastName); if (result != 0) return result; return x.FirstName.CompareTo(y.FirstName); } } // Comparer to sort people by Age (ascending) class AgeComparer : IComparer<Person> { public int Compare(Person? x, Person? y) { if (x is null && y is null) return 0; if (x is null) return -1; if (y is null) return 1; return x.Age.CompareTo(y.Age); // Leverages int's IComparable<int> } } void DemonstrateComparer() { List<Person> people = new() { new("Alice", "Smith", 30), new("Bob", "Johnson", 25), new("Charlie", "Smith", 35), new("David", "Brown", 25) }; Console.WriteLine("--- Sorted by Last Name, then First Name ---"); people.Sort(new LastNameComparer()); foreach (var p in people) { Console.WriteLine($"{p.LastName}, {p.FirstName} ({p.Age})"); } // Output: // Brown, David (25) // Johnson, Bob (25) // Smith, Alice (30) // Smith, Charlie (35) Console.WriteLine("\n--- Sorted by Age ---"); people.Sort(new AgeComparer()); foreach (var p in people) { Console.WriteLine($"{p.LastName}, {p.FirstName} ({p.Age})"); } // Output: // Johnson, Bob (25) // Brown, David (25) // Smith, Alice (30) // Smith, Charlie (35) } - Purpose: Defines a method that a comparer class implements to provide a generalized comparison method for two objects of a specific type. Unlike
-
IEquatable<T>:- Purpose: Defines a generalized method that a value type or class implements to determine if two instances are equal structurally. This is critical for types used in hash-based collections.
- Contract: Requires implementation of a single method:
bool Equals(T? other); - Importance: Essential for types used as keys in
Dictionary<TKey, TValue>, or inHashSet<T>, as well as for methods likeList<T>.Contains()andEnumerable.Contains(). Hash-based collections rely onEqualsandGetHashCodefor efficient lookups. IEquatable(Non-Generic): Similar toIComparable, the non-genericIEquatable(viaobject.Equals(object)) can cause boxing for value types. Always preferIEquatable<T>.- Overriding
object.Equalsandobject.GetHashCode:- Rule of Thumb: If you implement
IEquatable<T>, you must also overrideobject.Equals(object? obj)andobject.GetHashCode(). Failure to do so will lead to inconsistent behavior, especially when your type is used polymorphically asobject. Equals(object? obj)should simply castobjtoTand callEquals(T? other).GetHashCode()must produce the same hash code for objects that are considered equal byEquals. A common pattern is to combine hash codes of immutable fields.
- Rule of Thumb: If you implement
- Operator Overloading (
==,!=): For types that implementIEquatable<T>, it’s good practice to also overload the==and!=operators to provide intuitive syntax for equality comparison. These operators should also call theEquals(T? other)method.
record struct Point(int X, int Y) : IEquatable<Point> { // Implicitly provided by 'record struct' for Positional Records, // but shown here for demonstration of manual implementation: public bool Equals(Point other) { return X == other.X && Y == other.Y; } public override bool Equals(object? obj) { return obj is Point other && Equals(other); } public override int GetHashCode() { // Combine hash codes of immutable fields return HashCode.Combine(X, Y); } public static bool operator ==(Point left, Point right) => left.Equals(right); public static bool operator !=(Point left, Point right) => !left.Equals(right); } void DemonstrateEquatable() { Point p1 = new(10, 20); Point p2 = new(10, 20); Point p3 = new(30, 40); Console.WriteLine($"p1 equals p2: {p1.Equals(p2)}"); // Output: True Console.WriteLine($"p1 == p2: {p1 == p2}"); // Output: True Console.WriteLine($"p1 equals p3: {p1.Equals(p3)}"); // Output: False HashSet<Point> points = new() { p1 }; Console.WriteLine($"HashSet contains p2: {points.Contains(p2)}"); // Output: True (uses Equals and GetHashCode) }
10.1.2. IFormattable, IParsable<T>, ISpanFormattable, ISpanParsable<T>: Formatting and Parsing
These interfaces provide standardized ways to convert types to string representations and vice-versa, with advanced options for format providers and Span<char>-based operations to minimize allocations.
-
IFormattable:- Purpose: Allows a type to provide custom formatting logic when converted to a string using
string.Format,Console.WriteLine, or composite formatting. - Contract: Requires implementation of:
string ToString(string? format, IFormatProvider? formatProvider);format: A format string (e.g., “C” for currency, “N” for number, or custom patterns).formatProvider: An object (typicallyCultureInfo) that provides culture-specific formatting rules.
- Usage: The
ToString()overload inobjectcalls this method internally if the type implementsIFormattable.
record struct Temperature(double DegreesCelsius) : IFormattable { public string ToString(string? format, IFormatProvider? formatProvider) { if (string.IsNullOrEmpty(format)) { format = "G"; // General format } // Use invariant culture for parsing format specifiers switch (format.ToUpperInvariant()) { case "G": // General case "C": // Celsius return $"{DegreesCelsius.ToString("F2", formatProvider)}°C"; case "F": // Fahrenheit double fahrenheit = (DegreesCelsius * 9 / 5) + 32; return $"{fahrenheit.ToString("F2", formatProvider)}°F"; default: throw new FormatException($"The '{format}' format specifier is not supported."); } } public override string ToString() => ToString("G", null); } void DemonstrateFormattable() { Temperature temp = new(25.5); Console.WriteLine($"Default: {temp}"); // Output: Default: 25.50°C Console.WriteLine($"Celsius: {temp.ToString("C")}"); // Output: Celsius: 25.50°C Console.WriteLine($"Fahrenheit: {temp.ToString("F")}"); // Output: Fahrenheit: 77.90°F Console.WriteLine($"In CA culture: {string.Format(new System.Globalization.CultureInfo("fr-CA"), "{0:C}", temp)}"); // Output might be: In CA culture: 25,50 °C } - Purpose: Allows a type to provide custom formatting logic when converted to a string using
-
IParsable<T>(C# 7+) andISpanParsable<T>(C# 11):- Purpose: Provide a standardized mechanism for converting string representations back into instances of the type.
ISpanParsable<T>offers a more performant, allocation-free alternative for parsing fromReadOnlySpan<char>. -
Contracts:
// IParsable<T> static abstract T Parse(string s, IFormatProvider? provider); static abstract bool TryParse([NotNullWhen(true)] string? s, IFormatProvider? provider, [MaybeNullWhen(false)] out T result); // ISpanParsable<T> (requires C# 11) static abstract T Parse(ReadOnlySpan<char> s, IFormatProvider? provider); static abstract bool TryParse(ReadOnlySpan<char> s, IFormatProvider? provider, [MaybeNullWhen(false)] out T result);Parsethrows an exception on failure;TryParsereturnsfalseand doesn’t throw.- These are
static abstractmembers, a C# 11 feature, enabling compile-time checks for parse capabilities on generic types.
- Importance: Used implicitly by
T.Parse()andT.TryParse()methods (e.g.,int.Parse("123")). Enables generic parsing algorithms.
- Purpose: Provide a standardized mechanism for converting string representations back into instances of the type.
-
ISpanFormattable(C# 8):- Purpose: Allows a type to format its value directly into a
Span<char>without intermediate string allocations. This is crucial for high-performance scenarios where many strings are formatted. - Contract: Requires implementation of:
bool TryFormat(Span<char> destination, out int charsWritten, ReadOnlySpan<char> format, IFormatProvider? provider);destination: TheSpan<char>to write into.charsWritten: The number of characters written.format: The format string.provider: The format provider.- Returns
trueif the formatting was successful (i.e.,destinationwas large enough),falseotherwise.
record struct Dimensions(int Width, int Height) : ISpanFormattable { public bool TryFormat(Span<char> destination, out int charsWritten, ReadOnlySpan<char> format, IFormatProvider? provider) { // Example simple format: "W-H" or "Width:W, Height:H" string s = $"W:{Width},H:{Height}"; if (format.Equals("W-H", StringComparison.OrdinalIgnoreCase)) { s = $"{Width}-{Height}"; } if (s.Length <= destination.Length) { s.AsSpan().CopyTo(destination); charsWritten = s.Length; return true; } charsWritten = 0; return false; } public override string ToString() => $"W:{Width},H:{Height}"; } void DemonstrateSpanFormattable() { Dimensions dim = new(100, 200); Span<char> buffer = stackalloc char[20]; // Stack allocation for performance if (dim.TryFormat(buffer, out int written, "W-H", null)) { Console.WriteLine($"Formatted to Span: {buffer.Slice(0, written).ToString()}"); // Output: 100-200 } Span<char> largerBuffer = stackalloc char[50]; if (dim.TryFormat(largerBuffer, out written, null, null)) { Console.WriteLine($"Formatted to Larger Span: {largerBuffer.Slice(0, written).ToString()}"); // Output: W:100,H:200 } }ISpanFormattableandISpanParsable<T>are cornerstone interfaces for writing allocation-free, high-performance code, especially in scenarios involving frequent string conversions (e.g., logging, network protocols, parsing large data files). - Purpose: Allows a type to format its value directly into a
10.2. IEnumerable: The Magic Behind foreach and Iterator Methods
The IEnumerable<T> interface is arguably the most fundamental collection interface in the .NET BCL. It forms the backbone of data iteration in C# and is the cornerstone of LINQ. To truly understand its power, one must also grasp the role of IEnumerator<T> and the magic behind C#’s yield return keyword (iterators).
Purpose of IEnumerable<T>
The IEnumerable<T> interface represents a source of data that can be enumerated (iterated over). It defines a contract that simply states: “I can provide you with an enumerator to traverse my elements.” It does not contain the elements themselves but rather a mechanism to get an enumerator. This means IEnumerable<T> itself is typically stateless; it produces a fresh enumerator each time GetEnumerator() is called.
The IEnumerator<T>: The Iteration Worker
While IEnumerable<T> defines what can be enumerated, IEnumerator<T> defines how the enumeration happens. An object implementing IEnumerator<T> is the actual worker that tracks the current position during an iteration.
-
Contract:
IEnumerator<T>inherits fromIEnumerator(non-generic) andIDisposable. Its members are:-
T Current { get; }– Gets the element at the current position of the enumerator. -
bool MoveNext()– Advances the enumerator to the next element of the collection. Returnstrueif the enumerator was successfully advanced to the next element;falseif the enumerator has passed the end of the collection. -
void Reset()– (Optional to implement efficiently) Sets the enumerator to its initial position, which is before the first element in the collection. (Note: Most real-world IEnumerators don’t support Reset efficiently; it often throwsNotSupportedException). -
void Dispose()– (FromIDisposable) Performs application-defined tasks associated with freeing, releasing, or resetting unmanaged resources. Crucial for iterators that hold resources.
-
-
Stateful Nature: Unlike
IEnumerable<T>, anIEnumerator<T>instance is stateful. It maintains the current position within the sequence. Each timeMoveNext()is called, it advances that internal state. If you need to iterate over the sameIEnumerable<T>multiple times independently, you must obtain a newIEnumerator<T>each time by callingGetEnumerator().
Example: Infinite Sequence with IEnumerable<T> and IEnumerator<T>
public class FactorialEnumerable : IEnumerable<int> {
public IEnumerator<int> GetEnumerator() {
return new Enumerator();
}
IEnumerator IEnumerable.GetEnumerator() => GetEnumerator();
// this is a private class --> not exposed outside
private class Enumerator : IEnumerator<int> {
private int _counter = 0;
public int Current { get; private set; }
object IEnumerator.Current => Current;
public bool MoveNext() {
if (_counter == 0) {
Current = 1;
} else {
Current *= _counter;
}
_counter++;
return true;
}
public void Reset() {
_counter = 0;
}
public void Dispose() {}
}
}
This FactorialEnumerable class implements IEnumerable<int> and provides an enumerator that generates the factorial sequence indefinitely. The Enumerator class maintains the current factorial value and the counter, allowing it to compute the next factorial on each call to MoveNext().
The Concurrent Modification Problem
When you iterate over a list and at the same time remove elements from it, you trigger an InvalidOperationException.
For example: you have the list [1, 2, 3, 4, 5]. The enumerator is currently pointing at 2. You remove 2, which causes 3 to shift back one position. Then you call MoveNext() and Current, and instead of getting 3 next, you unexpectedly get 4.
In other words, you’ve created a kind of race condition — even though there are no threads involved.
Properly supporting concurrent modification would require additional memory and bookkeeping, so standard collections don’t support it. However, they do detect when you modify a collection during enumeration and throw an InvalidOperationException to prevent undefined behavior.
Here’s the original example code:
var a = new List<int> {1, 2, 3, 4, 5};
var e = a.GetEnumerator();
int index = 0;
while (e.MoveNext()) {
if (e.Current % 2 == 0) {
a.RemoveAt(index);
}
index++;
}
This code demonstrates the issue: you’re iterating and modifying the list at the same time, which invalidates the enumerator and can result in incorrect behavior or an exception.
The foreach Loop: Syntactic Sugar for Iteration
The C# foreach loop is syntactic sugar that makes iterating over a collection easier. When you write:
foreach (ElemT item in collection) statement;
the compiler roughly translates it into something like this:
IEnumerator enumerator = ((IEnumerable)collection).GetEnumerator();
try {
ElemT element;
while (enumerator.MoveNext()) {
element = (ElemT)enumerator.Current;
statement;
}
}
finally {
IDisposable disposable = enumerator as IDisposable;
// if it’s not an IEnumerable<T>, this Dispose() won’t get called
// because the non-generic IEnumerator doesn’t implement IDisposable
if (disposable != null) disposable.Dispose();
}
In reality, the compiler first tries to call collection.GetEnumerator() directly. If that doesn’t work, it looks for IEnumerable<T>.GetEnumerator(), and finally falls back to IEnumerable.GetEnumerator().
This means that collection doesn’t actually have to implement IEnumerable at all — it just needs to have a GetEnumerator() method (which can even be an extension method).
Another interesting detail is that there is an explicit cast when assigning Current to the loop variable. So you can write something like:
foreach (byte b in new List<int> {1, 2, 3})
Here the compiler inserts an explicit conversion from int to byte.
And if neither an implicit nor an explicit C# conversion exists, it will even search for a user-defined conversion operator.
Iterators (yield return): Compiler Magic for Easy Enumeration
Manually implementing IEnumerator<T> (and the backing IEnumerable<T>) can be tedious, requiring you to manage state (current position, whether iteration is complete) within a separate class. C# iterators, powered by the yield return keyword, eliminate this boilerplate.
-
The Problem Before
yield return: Imagine you want to create a custom enumerable that generates Fibonacci numbers. Withoutyield return, you’d need a separate class like this:// Manual implementation (pre-yield return concept) class FibonacciEnumerator : IEnumerator<int> { private int _current; private int _prev1 = 0; private int _prev2 = 1; private int _max; private int _index = -1; // -1 means before start public FibonacciEnumerator(int max) { _max = max; } public int Current => _current; // IEnumerator<int> object IEnumerator.Current => Current; // IEnumerator (non-generic) public bool MoveNext() { _index++; if (_index == 0) { _current = 0; } else if (_index == 1) { _current = 1; } else { _current = _prev1 + _prev2; _prev1 = _prev2; _prev2 = _current; } return _current <= _max; } public void Reset() { _current = 0; _prev1 = 0; _prev2 = 1; _index = -1; } public void Dispose() { /* No resources to dispose in this simple case */ } } class FibonacciSequence : IEnumerable<int> { private int _max; public FibonacciSequence(int max) { _max = max; } public IEnumerator<int> GetEnumerator() => new FibonacciEnumerator(_max); IEnumerator IEnumerable.GetEnumerator() => GetEnumerator(); } void DemonstrateManualEnumerable() { foreach (var num in new FibonacciSequence(50)) { Console.Write($"{num} "); // Output: 0 1 1 2 3 5 8 13 21 34 } Console.WriteLine(); }This is a lot of code for a simple iteration!
-
The Solution with
yield return: The C# compiler handles all this complexity for you by transforming your method into a state machine. When the compiler seesyield returnin a method (orgetaccessor of a property), it implicitly generates the backingIEnumerable<T>andIEnumerator<T>implementations. -
How the State Machine Works (High-Level):
- Compiler Transformation: A method containing
yield returnis transformed by the compiler into a private, nested, compiler-generated class. This class implements bothIEnumerable<T>andIEnumerator<T>. - State Capture: Each
yield returnstatement represents a “pause point” in the execution of your iterator method. Whenyield return valueis encountered,valueis returned asCurrent, and the internal state of the method (including local variables, parameters, and the exact point of execution) is captured. MoveNext()Resumption: The next timeMoveNext()is called on the generated enumerator, the state machine resumes execution exactly from where it left off.- Lazy Evaluation: Elements are produced only when
MoveNext()is called. This means computation is deferred until it’s actually needed. This can save significant memory and CPU time if not all elements of a potentially large sequence are consumed. yield break: This statement terminates the iteration immediately, indicating that there are no more elements to return.
- Compiler Transformation: A method containing
// Using yield return (the modern way)
IEnumerable<int> GetFibonacciSequence(int max)
{
int prev1 = 0;
int prev2 = 1;
if (max >= 0) yield return prev1; // Yield first element
if (max >= 1) yield return prev2; // Yield second element
while (true)
{
int current = prev1 + prev2;
if (current > max)
{
yield break; // Terminate iteration
}
yield return current;
prev1 = prev2;
prev2 = current;
}
}
void DemonstrateIteratorBlock()
{
Console.WriteLine("Fibonacci sequence up to 50:");
foreach (var num in GetFibonacciSequence(50))
{
Console.Write($"{num} "); // Output: 0 1 1 2 3 5 8 13 21 34
}
Console.WriteLine();
Console.WriteLine("Taking first 5 Fibonacci numbers:");
// Only the first 5 numbers are calculated and yielded
// Take(int) is an extension method from System.Linq
foreach (var num in GetFibonacciSequence(50).Take(5))
{
Console.Write($"{num} "); // Output: 0 1 1 2 3
}
Console.WriteLine();
}
In DemonstrateIteratorBlock, when GetFibonacciSequence(50) is called, it doesn’t immediately compute all Fibonacci numbers. It returns an IEnumerable<int> instance (the compiler-generated state machine object). The foreach loop then calls MoveNext() on that instance, and the GetFibonacciSequence code executes incrementally, pausing at each yield return. If Take(5) is used, MoveNext() is only called 5 times, and the method stops execution after yielding the 5th number.
Performance Characteristics of IEnumerable<T>
- Iteration, Not Lookup: Provides forward-only iteration. No direct access by index or key, no efficient count without iterating (unless the underlying type also implements
ICollection<T>orIReadOnlyCollection<T>). - Lazy Evaluation: This is a key advantage. Data is processed on demand, which is efficient for very large or infinite sequences.
-
Repeated Enumeration: If you iterate over an
IEnumerable<T>multiple times (and it’s not a materialized collection likeList<T>), the underlying code that produces the sequence might execute each time. This can be a performance concern if the production is expensive. To avoid this, you can materialize the enumerable into a concrete collection:IEnumerable<int> expensiveEnumerable = GetExpensiveData(); List<int> materializedList = expensiveEnumerable.ToList(); // Execution happens here once // Now iterate over materializedList multiple times without re-execution foreach (var item in materializedList) { /* ... */ } foreach (var item in materializedList) { /* ... */ } - Potential for Side Effects: If the source data for an
IEnumerable<T>changes between enumerations, subsequent enumerations might yield different results, which can be a source of subtle bugs. Be mindful of this when designing iterators over mutable sources.
In summary, IEnumerable<T> defines a contract for iteration, IEnumerator<T> is the object that performs the iteration, and yield return is a powerful C# language feature that simplifies the creation of these enumerable sequences by allowing the compiler to generate the necessary state-machine logic. This combination promotes lazy evaluation and highly readable, efficient data processing patterns.
10.3. Collection Interfaces and Iterators
The .NET BCL provides a rich set of collection interfaces that define the common behaviors of various data structures. Understanding this hierarchy is key to designing flexible APIs and choosing the right collection for a given task.
10.3.1. ICollection<T>: Basic Collection Manipulation
Builds upon IEnumerable<T>, adding basic collection modification and counting capabilities.
- Purpose: Represents a generic collection of elements that supports adding, removing, and checking for existence.
- Contract: Inherits from
IEnumerable<T>and adds:int Count { get; } bool IsReadOnly { get; } void Add(T item); void Clear(); bool Contains(T item); void CopyTo(T[] array, int arrayIndex); bool Remove(T item); - Importance: Provides a common interface for mutable collections where knowing the count and basic manipulation is needed, but indexed access is not.
- Performance:
Countis typically O(1).Contains,Add,Removeperformance varies greatly depending on the underlying implementation (e.g.,List<T>forContainsis O(N), forHashSet<T>it’s O(1) on average).
10.3.2. IList<T>: Ordered, Indexed Collections
Extends ICollection<T> with features for ordered, index-based access.
- Purpose: Represents a generic list of elements that can be accessed by index.
- Contract: Inherits from
ICollection<T>and adds:T this[int index] { get; set; } // Indexer int IndexOf(T item); void Insert(int index, T item); void RemoveAt(int index); - Importance: The interface for array-like collections where element order and positional access are crucial.
- Performance: Indexer access (
this[int]) is typically O(1).InsertandRemoveAtare generally O(N) because they often require shifting elements.IndexOfis O(N). - Common Implementations:
List<T>is the most common.T[](arrays) can be implicitly cast toIList<T>.
10.3.3. IDictionary<TKey, TValue>: Key-Value Pair Collections
Defines a contract for collections that store key-value pairs.
- Purpose: Represents a generic collection of key/value pairs that are organized by a key. Keys must be unique within the dictionary.
- Contract: Inherits from
ICollection<KeyValuePair<TKey, TValue>>and adds:TValue this[TKey key] { get; set; } // Indexer (key-based) ICollection<TKey> Keys { get; } ICollection<TValue> Values { get; } bool ContainsKey(TKey key); void Add(TKey key, TValue value); bool Remove(TKey key); bool TryGetValue(TKey key, [MaybeNullWhen(false)] out TValue value); - Importance: Fundamental for fast lookups by key.
- Performance:
Add,Remove,ContainsKey,TryGetValue, and indexer access (this[TKey]) are typically O(1) on average for hash-based implementations likeDictionary<TKey, TValue>. In worst-case collision scenarios, they can degrade to O(N). - Common Implementations:
Dictionary<TKey, TValue>is the primary general-purpose implementation.
10.3.4. ISet<T>: Unique Collections
Defines a contract for collections that guarantee unique elements and support mathematical set operations.
- Purpose: Represents a generic collection that ensures all its elements are unique. It also provides methods for performing standard set operations such as unions, intersections, and supersets. Unlike
List<T>orDictionary<TKey, TValue>,ISet<T>focuses on the presence of elements and their relationships to other sets, rather than their order or indexed access. -
Contract: Inherits from
ICollection<T>(and thusIEnumerable<T>) and adds methods specifically for set theory:void ExceptWith(IEnumerable<T> other); // Removes all elements in the specified collection from the current set. void IntersectWith(IEnumerable<T> other); // Modifies the current set to contain only elements that are also in a specified collection. bool IsProperSubsetOf(IEnumerable<T> other); // Determines whether a set is a proper (strict) subset of a specified collection. bool IsProperSupersetOf(IEnumerable<T> other); // Determines whether a set is a proper (strict) superset of a specified collection. bool IsSubsetOf(IEnumerable<T> other); // Determines whether a set is a subset of a specified collection. bool IsSupersetOf(IEnumerable<T> other); // Determines whether a set is a superset of a specified collection. bool Overlaps(IEnumerable<T> other); // Determines whether the current set and a specified collection share common elements. bool SetEquals(IEnumerable<T> other); // Determines whether the current set and a specified collection contain the same elements. void SymmetricExceptWith(IEnumerable<T> other); // Modifies the current set to contain only elements that are present either in the current set or in the specified collection, but not both. void UnionWith(IEnumerable<T> other); // Modifies the current set to contain all elements that are present in the current set, in the specified collection, or in both.Note that the
Addmethod fromICollection<T>is implicitly implemented byISet<T>, but its behavior is modified:Add(T item)returnstrueif the item was added (i.e., it was unique), andfalseif the item was already present. -
Importance:
ISet<T>is the ideal choice when:- You need to store a collection of items where each item must be unique (e.g., a list of unique usernames, distinct tags).
- You need to perform mathematical set operations (e.g., finding common elements between two lists, getting all elements from two lists without duplicates).
- The order of elements is not important, and indexed access is not required.
-
Performance:
- For
HashSet<T>(the most common implementation),Add,Remove,Contains, and checking for uniqueness are typically O(1) on average, due to its underlying hash table implementation. In worst-case collision scenarios, these operations can degrade to O(N). - Set operations like
UnionWith,IntersectWith,ExceptWith,IsSubsetOf, etc., generally perform efficiently, often involving iteration through one or both sets. Their complexity typically scales with the size of the sets involved (e.g., O(N+M) or O(N*M) in less optimal cases, or O(N log N) if sorting is involved, as inSortedSet<T>).
- For
-
Common Implementations:
HashSet<T>: The primary general-purpose implementation. It stores elements in a hash table, providing very fast average-case performance for basic operations and set operations. Elements are not stored in any particular order.SortedSet<T>: ImplementsISet<T>and also maintains elements in sorted order. This is achieved using a self-balancing binary search tree. While it provides ordered enumeration and retains uniqueness, itsAdd,Remove, andContainsoperations are typically O(log N) due to the tree traversal, which is slower thanHashSet<T>but still highly efficient. Set operations are also affected by the sorting requirement.
10.3.5. Read-Only Collection Interfaces
The .NET ecosystem provides read-only counterparts to the mutable collection interfaces to enable safe exposure of collection data without allowing external modification.
-
IReadOnlyCollection<T> : IEnumerable<T>addsint Count { get; }.
-
IReadOnlyList<T> : IReadOnlyCollection<T>addsT this[int index] { get; }.
-
IReadOnlyDictionary<TKey, TValue> : IEnumerable<KeyValuePair<TKey, TValue>>addsTValue this[TKey key] { get; },IEnumerable<TKey> Keys,IEnumerable<TValue> Values,bool ContainsKey(TKey key),bool TryGetValue(TKey key, out TValue value).
-
IReadOnlySet<T> : IReadOnlyCollection<T>addsbool Contains(T item),IsProperSubsetOf(IEnumerable<T> other),IsProperSupersetOf(IEnumerable<T> other),IsSubsetOf(IEnumerable<T> other),IsSupersetOf(IEnumerable<T> other),Overlaps(IEnumerable<T> other).SetEquals(IEnumerable<T> other).
Importance:
- Encapsulation and Immutability: Enables methods to return collections that consumers can iterate or query but not modify, promoting safer APIs and reducing side effects.
-
API Design: When a method doesn’t need to modify a collection argument, accept
IReadOnlyList<T>orIReadOnlyDictionary<TKey, TValue>instead ofList<T>orDictionary<TKey, TValue>. This communicates intent and makes the API more flexible (e.g.,IEnumerable<T>can be passed toIReadOnlyList<T>if it’s actually aList<T>).class ProductCatalog { private readonly Dictionary<string, decimal> _products = new(); public ProductCatalog() { _products["Laptop"] = 1200.00m; _products["Mouse"] = 25.00m; _products["Keyboard"] = 75.00m; } // Exposes products as read-only dictionary public IReadOnlyDictionary<string, decimal> GetAvailableProducts() { return _products; // Safely returns a read-only view of the internal dictionary } public decimal GetPrice(string productName) { return _products[productName]; } } void UseProductCatalog() { ProductCatalog catalog = new(); IReadOnlyDictionary<string, decimal> products = catalog.GetAvailableProducts(); Console.WriteLine("Available Products:"); foreach (var item in products) { Console.WriteLine($"- {item.Key}: {item.Value:C}"); } // products.Add("Monitor", 300.00m); // COMPILE-TIME ERROR: Cannot modify IReadOnlyDictionary }
10.4. Resource Management Interfaces: IDisposable
In managed environments like .NET, the Garbage Collector (GC) handles memory deallocation automatically. However, not all resources are memory. File handles, network sockets, database connections, and GDI+ objects are examples of unmanaged resources or managed resources that wrap unmanaged ones. These resources need to be released deterministically, and the IDisposable interface provides the standard pattern for doing so.
10.4.1. IDisposable and the Dispose Method
- Purpose: Provides a mechanism for releasing unmanaged resources (or managed resources that wrap unmanaged ones) and performing other cleanup operations deterministically, rather than relying on the non-deterministic nature of the GC.
- Contract: Requires a single method:
void Dispose(); - Usage: The
Dispose()method should be called explicitly by the consumer of the object when they are finished with it.
10.4.2. The using Statement and using Declaration
C# provides syntactic sugar to ensure Dispose() is called correctly, even if exceptions occur.
-
usingStatement: (C# 1.0+) Ensures thatDispose()is called on anIDisposableobject when theusingblock is exited. It’s equivalent to atry-finallyblock.void WriteToFile(string filePath, string content) { // The StreamWriter implements IDisposable using (StreamWriter writer = new StreamWriter(filePath)) { writer.WriteLine(content); } // writer.Dispose() is called automatically here }This is equivalent to:
void WriteToFileManual(string filePath, string content) { StreamWriter? writer = null; try { writer = new StreamWriter(filePath); writer.WriteLine(content); } finally { // Ensures Dispose is called even if an exception occurs writer?.Dispose(); } } -
usingDeclaration: (C# 8.0+) A more concise form of theusingstatement for local variables. The resource is disposed at the end of the current scope (method, block).void ReadAndProcessFile(string filePath) { // Resource disposed at the end of the method scope using StreamReader reader = new StreamReader(filePath); string line; while ((line = reader.ReadLine()!) != null) { Console.WriteLine($"Read: {line}"); } } // reader.Dispose() is called automatically here
10.4.3. Finalizers (~Class()) vs. IDisposable
- Finalizers: (Destructors in C++) are special methods (
~ClassName()) that the Garbage Collector calls non-deterministically when an object is deemed unreachable. They are primarily used to release unmanaged resources (e.g., native memory, OS handles) ifDispose()was not called.- Drawbacks:
- Non-deterministic: You don’t know when they will run. Resources might be held longer than necessary.
- Performance Overhead: Finalization requires an object to be moved to a special queue, delaying its cleanup and increasing GC work.
- Drawbacks:
IDisposablevs. Finalizers:IDisposableis for deterministic cleanup, initiated by the developer. Finalizers are a fallback mechanism for unmanaged resources ifIDisposable.Dispose()was forgotten.-
The
Dispose(bool disposing)Pattern: The recommended pattern for implementingIDisposablein types that might also have a finalizer:class MyResource : IDisposable { private bool _disposed = false; private IntPtr _unmanagedHandle; // Represents an unmanaged resource public MyResource() { _unmanagedHandle = System.Runtime.InteropServices.Marshal.AllocHGlobal(1024); // Allocate unmanaged memory Console.WriteLine("MyResource created, unmanaged handle allocated."); } // Finalizer: Called by GC ~MyResource() { Console.WriteLine("Finalizer running (non-deterministic cleanup)."); Dispose(false); // Do NOT dispose managed resources here } // Public Dispose method: Called by user public void Dispose() { Console.WriteLine("Dispose() called (deterministic cleanup)."); Dispose(true); // Dispose managed AND unmanaged resources GC.SuppressFinalize(this); // Tell GC not to call finalizer } protected virtual void Dispose(bool disposing) { if (_disposed) return; if (disposing) { // Dispose managed resources here (e.g., other IDisposable objects) // if (_anotherManagedObject != null) _anotherManagedObject.Dispose(); Console.WriteLine("Disposing managed resources."); } // Always dispose unmanaged resources here if (_unmanagedHandle != IntPtr.Zero) { System.Runtime.InteropServices.Marshal.FreeHGlobal(_unmanagedHandle); _unmanagedHandle = IntPtr.Zero; Console.WriteLine("Disposing unmanaged handle."); } _disposed = true; } } void DemonstrateDisposePattern() { Console.WriteLine("--- Using block ---"); using (var res = new MyResource()) { // Work with resource } // Dispose() called here Console.WriteLine("--- Without using block, relying on GC (bad practice) ---"); MyResource res2 = new MyResource(); // res2 is never explicitly disposed. // Finalizer might run much later, or not at all before process exit. GC.Collect(); // Force GC for demo purposes, but this is non-deterministic in real apps GC.WaitForPendingFinalizers(); // Wait for finalizers to complete Console.WriteLine("End of demo."); }The
GC.SuppressFinalize(this)call is critical within thepublic Dispose()method. If a user explicitly disposes the object, there’s no need for the GC to later call the finalizer. Suppressing it improves performance.
10.4.4. Asynchronous Disposal (IAsyncDisposable, C# 8)
For resources that require asynchronous cleanup (e.g., closing an async network connection, flushing an async stream), C# 8 introduced IAsyncDisposable.
- Contract: Requires a single method:
ValueTask DisposeAsync(); -
Usage: Used with the
await usingstatement.class AsyncResource : IAsyncDisposable { public async ValueTask DisposeAsync() { Console.WriteLine("Simulating async cleanup..."); await Task.Delay(100); // Simulate async work Console.WriteLine("Async cleanup complete."); } } async Task DemonstrateAsyncDispose() { Console.WriteLine("Starting async using block..."); await using (var res = new AsyncResource()) { Console.WriteLine("Working with async resource..."); } // DisposeAsync() is awaited here Console.WriteLine("Async using block finished."); }ValueTaskis used as the return type for performance reasons, similar toIValueTaskSource, to avoid allocating an object if theDisposeAsyncoperation completes synchronously.
10.5. Mathematical and Numeric Interfaces (Generic Math)
Prior to C# 11, writing generic algorithms that operated on numeric types (e.g., Add(T a, T b)) was cumbersome or impossible without dynamic dispatch, reflection, or boxing. The lack of constraints for static members (like operators) meant you couldn’t express “T must have a ‘+’ operator.” C# 11, along with .NET 7+, introduced a suite of interfaces in the System.Numerics namespace that enable Generic Math. We already touched on this in Chapter 9, but here we’ll explore it in detail.
The Problem Statement
Consider trying to write a generic Sum method:
// How would you implement this before C# 11 Generic Math?
// T Sum<T>(IEnumerable<T> values)
// {
// T sum = default(T); // What is zero for T?
// foreach (T value in values)
// {
// sum = sum + value; // Error: Operator '+' cannot be applied to operands of type 'T' and 'T'
// }
// return sum;
// }
There was no way to constrain T to have an addition operator or a concept of “zero.” Developers resorted to specific overloads, dynamic, or reflection, all of which had drawbacks (boilerplate, performance, type safety).
The Solution: System.Numerics Interfaces
C# 11 introduced static abstract and static virtual members in interfaces (as detailed in Chapter 9). The System.Numerics namespace provides a rich set of interfaces that leverage this feature, allowing types (including built-in numeric types like int, double, decimal) to declare support for various mathematical operations.
-
The
TSelfConstraint: A crucial aspect is theTSelfconstraint, whereTSelfrefers to the implementing type itself (where TSelf : IMyInterface<TSelf>). This enables static methods to be called on the generic type parameter. -
Key Interfaces and Their Contracts (Examples):
INumber<TSelf>: The fundamental interface for all numeric types. It represents a real, integer, or complex number. It provides common static members likeOne,Zero,Parse,TryParse, and operators for+,-,*,/.// Key members in INumber<TSelf> (simplified) static abstract TSelf One { get; } static abstract TSelf Zero { get; } static abstract TSelf Parse(string s, IFormatProvider? provider); // ... and many more operators from inherited interfaces like IAdditionOperatorsIAdditionOperators<TSelf, TOther, TResult>: Defines the+operator.static abstract TResult operator +(TSelf left, TOther right);IMultiplyOperators<TSelf, TOther, TResult>: Defines the*operator.IDivisionOperators<TSelf, TOther, TResult>: Defines the/operator.ISignedNumber<TSelf>: Adds properties likeNegativeOne, and methods forAbs,Sign.IFloatingPoint<TSelf>: For floating-point specific operations (NaN,PositiveInfinity,Sin,Cos, etc.).IBinaryInteger<TSelf>: For integer-specific operations (bitwise, shifts).
-
How They Enable Generic Algorithms: By constraining a generic type parameter
Tto one or more of these interfaces, you can write generic code that directly uses operators and static methods onT, and the compiler will ensure thatTprovides those implementations.// Now this works with C# 11 and .NET 7+ static T SumAll<T>(IEnumerable<T> values) where T : System.Numerics.INumber<T> // T must implement INumber<T> (and implicitly IAdditionOperators<T,T,T>) { T sum = T.Zero; // Access static property 'Zero' on T foreach (T value in values) { sum += value; // Uses the static 'operator +' on T } return sum; } static T Average<T>(IEnumerable<T> values) where T : System.Numerics.INumber<T> { if (!values.Any()) return T.Zero; T sum = SumAll(values); T count = T.CreateChecked(values.Count()); // Convert int count to T return sum / count; // Uses static 'operator /' on T } void DemonstrateGenericMath() { Console.WriteLine($"Sum of ints: {SumAll(new List<int> { 1, 2, 3 })}"); // Output: 6 Console.WriteLine($"Sum of doubles: {SumAll(new double[] { 1.5, 2.5, 3.0 })}"); // Output: 7.0 Console.WriteLine($"Average of decimals: {Average(new List<decimal> { 10.0m, 20.0m, 30.0m })}"); // Output: 20.0 } -
Underlying Mechanism and Performance: The magic behind Generic Math lies in the JIT compiler. When a generic method like
SumAll<T>is compiled for a specificT(e.g.,int), the JIT compiler generates highly optimized machine code that directly calls theint’s specific static addition operator. There’s no boxing, no reflection overhead, and often performance is comparable to direct, non-generic calls. This is possible because thestatic abstractconstraint provides enough information at compile time for the JIT to link to the concrete static implementations.
Generic Math represents a significant leap forward in C# extensibility, allowing library authors to create highly performant, type-safe, and truly generic numeric algorithms that were previously impossible or highly inefficient.
Key Takeaways
- Core Value Type Interfaces (
IComparable<T>,IEquatable<T>,IFormattable,IParsable<T>,ISpanFormattable,ISpanParsable<T>): These enable standardized comparisons, structural equality, custom formatting, and efficient parsing for types. Always prefer generic versions (<T>) to avoid boxing, and correctly implementobject.Equalsandobject.GetHashCodewhen implementingIEquatable<T>. Here’s a short “Key Takeaways” list specifically for theIEnumerable<T>/IEnumerator<T>section: IEnumerable<T>vs.IEnumerator<T>:IEnumerable<T>defines what can be iterated (a data source) and is typically stateless, whileIEnumerator<T>defines how it’s iterated (the actual stateful object tracking position).foreachLoop’s Role: Theforeachloop is syntactic sugar that automatically handles obtaining anIEnumerator<T>, callingMoveNext(), accessingCurrent, and ensuringDispose()is called on the enumerator.- Iterators (
yield return): Theyield returnkeyword allows you to implementIEnumerable<T>andIEnumerator<T>effortlessly. The C# compiler transforms your method into a complex state machine behind the scenes. - Lazy Evaluation: Iterators enable lazy evaluation, meaning elements are produced and computations are performed only when
MoveNext()is called, making them efficient for large or infinite sequences. - Collection Interfaces (
IEnumerable<T>,ICollection<T>,IList<T>,ISet<T>IDictionary<TKey, TValue>): Define contracts for data structures, promoting polymorphic usage and flexible API design. Understand their hierarchy and performance characteristics to choose the appropriate collection. - Read-Only Collections (
IReadOnlyCollection<T>,IReadOnlyList<T>,IReadOnlySet<T>,IReadOnlyDictionary<TKey, TValue>): Essential for encapsulating internal collection state and providing safe, immutable views to consumers, enhancing API robustness. - Resource Management (
IDisposable,IAsyncDisposable):IDisposableenables deterministic cleanup of managed and unmanaged resources, primarily used with theusingstatement (orawait usingforIAsyncDisposable). Finalizers (~Class()) are non-deterministic fallbacks for unmanaged resources, typically combined withIDisposableusing theDispose(bool disposing)pattern andGC.SuppressFinalize. String: Immutable in C#, leading to thread safety, string pooling, and hash code caching. Be mindful of performance implications for frequent modifications (useStringBuilder). LeverageSpan<char>for allocation-free text processing. Always use explicitStringComparisonfor clarity and correctness.DateTimeandDateTimeOffset:DateTimeOffsetis generally preferred for storing absolute points in time due to its clear UTC offset, mitigating time zone ambiguities. Store UTC, convert for display. UseTimeZoneInfofor robust time zone conversions.Guid: Provides a virtually unique 128-bit identifier, excellent for distributed systems. Understand its random generation and use cases, and be aware of sequential GUID considerations for database performance.Enum: Provides named integral constants, improving readability. Use[Flags]for bitwise combinations, assign explicit values, and always validate external enum inputs.- Generic Math Interfaces (C# 11+): Interfaces like
INumber<TSelf>,IAdditionOperators<TSelf, TOther, TResult>, etc., inSystem.Numericsleveragestatic abstractinterface members to enable powerful, type-safe, and performant generic algorithms over numeric types, eliminating previous limitations.
11. Fundamental C# Types: Core Data Structures and Utilities
This chapter delves into essential BCL (Base Class Library) types that form the bedrock of almost every C# application. While seemingly simple, a deep understanding of their internal workings, performance characteristics, and best practices is crucial for writing robust, efficient, and maintainable software. We will explore their design rationale, memory implications, and how to leverage them effectively in modern C# development.
11.1. Strings: The Immutable Reference Type
In Chapter 3.4, we briefly touched upon System.String as a special reference type. While indeed a reference type (meaning variables store a memory address to an object on the heap), string possesses a unique characteristic: immutability. This property, coupled with its pervasive use in C# applications, profoundly impacts how we work with strings, influencing performance, memory management, and design patterns. This sub-chapter provides a comprehensive guide to understanding strings at a deeper level.
For general information on strings in C#, refer to Strings (C# Programming Guide).
11.1.1. The Nature of String Immutability
The most fundamental concept to grasp about System.String is its immutability. Once a string object has been created in memory, its content (the sequence of characters it represents) cannot be changed. Any operation that appears to modify a string actually results in the creation of a brand new string object in memory.
Consider this seemingly simple operation:
string original = "Hello";
string modified = original + " World"; // Concatenation
Console.WriteLine(original); // Output: Hello
Console.WriteLine(modified); // Output: Hello World
Behind the scenes, the original string object (containing “Hello”) remains untouched on the heap. The + operator, or any string manipulation method like ToUpper(), Replace(), or Substring(), creates a new string object ("Hello World" in this case) and returns a reference to it. The modified variable then points to this new object.
Visualizing Immutability:
Heap Memory:
+-------------------+ +-------------------+
| Address: 0x1000 | | Address: 0x2000 |
| Object Header | | Object Header |
| Data: "Hello" | <----| Data: "Hello World" |
+-------------------+ +-------------------+
^ ^
| |
Variable: original Variable: modified
If original were reassigned (original = original.Replace('H', 'J');), original would then point to yet another new string object, while the “Hello” object would eventually become eligible for garbage collection.
Why Immutability? (Design Rationale):
The immutability of string is a deliberate design choice that offers significant advantages:
- Thread Safety: Since string content never changes, multiple threads can safely read and access the same string object concurrently without any risk of data corruption or needing locks. This simplifies concurrent programming dramatically.
- Hash Code Stability: Strings are frequently used as keys in hash-based collections (like
Dictionary<string, T>orHashSet<string>). An immutable string guarantees that its hash code (which is often cached internally for performance) remains constant throughout its lifetime. If strings were mutable, their hash codes could change, breaking the integrity of hash collections. - Security: In many scenarios, strings represent critical data (e.g., file paths, database connection strings, user input that has been validated). Immutability ensures that once a string has been validated, its content cannot be maliciously altered by another part of the application.
- Predictability and Reliability: Knowing that a string’s content will never change means you can confidently pass string references around without worrying about unexpected modifications by other code.
11.1.2. String Internals: Memory Layout and Pooling
Understanding how strings are represented in memory and how the CLR optimizes their storage is key to writing memory-efficient C# code.
Underlying Representation:
At its core, a System.String object in .NET is essentially a managed wrapper around an array of 16-bit Unicode characters (UTF-16 code units). This internal char[] array holds the actual character data. Like all reference types, a string instance also includes an Object Header (as discussed in Chapter 7.1), which contains a pointer to its Method Table and other runtime information.
String Literals and the Intern Pool:
The CLR employs a crucial optimization for string literals (strings defined directly in your source code, e.g., "hello world") and other identical string values: string interning or string pooling.
- The Intern Pool: The CLR maintains a special cache in memory known as the intern pool (or string pool). When the JIT compiler encounters a string literal, it first checks if a string with the exact same sequence of characters already exists in the intern pool.
- If it exists, the existing interned string object’s reference is returned.
- If it doesn’t exist, a new string object is created, added to the intern pool, and its reference is returned.
This means that all identical string literals in your application (across different assemblies even) will typically refer to the exact same object in memory.
Visualizing String Interning:
Heap Memory (Intern Pool):
+-------------------+
| Address: 0x1000 |
| Object Header |
| Data: "Hello" | <-------
+-------------------+ |
|
+-------------------+ |
| Address: 0x2000 | |
| Object Header | |
| Data: "World" | |
+-------------------+ |
|
Variables: |
string s1 = "Hello"; --> 0x1000
string s2 = "Hello"; --> 0x1000 (Same object reference!)
string s3 = "World"; --> 0x2000
This optimization has two main benefits:
- Memory Saving: Reduces the overall memory footprint by avoiding duplicate string objects.
- Performance Optimization: Enables very fast equality checks using reference equality (
object.ReferenceEquals) for interned strings, thoughstring == stringstill performs value equality.
Manual Interning: string.Intern() and string.IsInterned()
While string literals are automatically interned, strings created at runtime (e.g., from user input, file reads, network streams) are generally not interned by default. You can explicitly intern such strings using string.Intern().
string.Intern(string str): Addsstrto the intern pool if it’s not already there and returns a reference to the interned string. Ifstris already interned, it simply returns the existing interned reference.string.IsInterned(string str): Checks if a given string object is already in the intern pool. Returns the interned reference if it exists, otherwisenull.
string dynamicString1 = new StringBuilder().Append("Dyn").Append("amic").ToString(); // "Dynamic"
string dynamicString2 = new StringBuilder().Append("Dyn").Append("amic").ToString(); // "Dynamic"
Console.WriteLine($"dynamicString1 == dynamicString2: {dynamicString1 == dynamicString2}"); // Output: True (Value equality)
Console.WriteLine($"ReferenceEquals(dynamicString1, dynamicString2): {ReferenceEquals(dynamicString1, dynamicString2)}"); // Output: False (Different objects on heap)
string internedString1 = string.Intern(dynamicString1);
string internedString2 = string.Intern(dynamicString2); // Will return the same interned object as internedString1
Console.WriteLine($"ReferenceEquals(internedString1, internedString2): {ReferenceEquals(internedString1, internedString2)}"); // Output: True
Trade-offs of Manual Interning:
- Benefit: Can save memory if you have many identical strings dynamically created, particularly for long-lived applications.
- Cost:
string.Intern()involves a lookup in a hash table (the intern pool), which can incur a performance overhead. Only use it when the memory savings genuinely outweigh the lookup cost, often for very frequently compared or frequently duplicated strings. For most applications, automatic interning of literals is sufficient.
11.1.3. String Creation and Initialization Methods
Strings can be created in several ways:
- String Literals:
string greeting = "Hello, C#!"; - Concatenation: Using the
+operator orstring.Concat(). Remember this creates new strings.string firstName = "John"; string lastName = "Doe"; string fullName = firstName + " " + lastName; // Creates new string "John Doe" string anotherFullName = string.Concat(firstName, " ", lastName); // Similar effect System.Text.StringBuilder: For efficient, mutable string building (covered in 3.8.4).-
stringConstructors: For more explicit control, such as creating a string from a character array, a pointer, or repeating a character.char[] chars = { 'A', 'B', 'C' }; string fromChars = new string(chars); // "ABC" string repeated = new string('x', 5); // "xxxxx" // From a char array, offset, and count string part = new string(chars, 1, 2); // "BC" string.Join(): For concatenating elements of an enumerable collection with a separator.string[] words = { "The", "quick", "brown", "fox" }; string sentence = string.Join(" ", words); // "The quick brown fox"
11.1.4. Efficient String Manipulation and Performance
The immutability of strings, while beneficial for safety and stability, can lead to significant performance bottlenecks if not handled correctly during manipulation, especially concatenation in loops.
The Concatenation Performance Trap (O(N^2)):
When you repeatedly concatenate strings using the += operator or string.Concat in a loop, you’re creating a new string object in memory with each iteration. Each new string requires a new memory allocation, and the contents of the previous string (which grows larger with each step) must be copied into the new, larger string. This leads to a quadratic time complexity, $O(N^2)$, where $N$ is the final length of the string.
Illustrative Example of the Problem:
// INEFFICIENT: Creates many intermediate strings and performs many copies
public string BuildStringInefficiently(int count)
{
string result = "";
for (int i = 0; i < count; i++)
{
result += "a"; // Each += creates a new string object
}
return result;
}
Memory Allocation with +=:
Iteration 1: "a" (alloc 1 byte, copy 0)
Iteration 2: "aa" (alloc 2 bytes, copy 1 byte)
Iteration 3: "aaa" (alloc 3 bytes, copy 2 bytes)
...
Iteration N: "a...a" (N times) (alloc N bytes, copy N-1 bytes)
Total Memory Allocations: 1 + 2 + 3 + ... + N = O(N^2)
Total Copy Operations: 0 + 1 + 2 + ... + (N-1) = O(N^2)
For small N, this might not be noticeable, but for larger N (e.g., thousands of concatenations), performance degrades rapidly, and it can lead to increased garbage collection pressure.
The Solution: System.Text.StringBuilder
For scenarios involving frequent string modification or concatenation, the System.Text.StringBuilder class is the correct and highly efficient solution.
- Purpose:
StringBuilderis a mutable sequence of characters. It avoids repeated string allocations by maintaining an internal, resizable character buffer (array). - Mechanism: When you append characters or strings to a
StringBuilder, it adds them to its internal buffer. If the buffer runs out of space, it automatically reallocates a larger buffer (usually doubling its capacity) and copies the existing contents. This reallocation happens far less frequently than with immutable string concatenation. - Performance: This strategy results in an amortized linear time complexity, $O(N)$, for building a string of final length N, which is significantly more efficient than $O(N^2)$.
Example using StringBuilder:
using System.Text; // Required namespace
// EFFICIENT: Uses StringBuilder to minimize allocations
public string BuildStringEfficiently(int count)
{
StringBuilder sb = new StringBuilder(); // Default capacity or specify one (e.g., new StringBuilder(count))
for (int i = 0; i < count; i++)
{
sb.Append("a"); // Appends to the internal buffer
}
return sb.ToString(); // Creates the final immutable string object once
}
// Fluent syntax example
StringBuilder fluentSb = new StringBuilder();
fluentSb.Append("Hello")
.Append(", ")
.Append("World!")
.AppendLine()
.AppendFormat("The answer is {0}.", 42);
string finalResult = fluentSb.ToString();
Console.WriteLine(finalResult);
Capacity Management:
StringBuilder has a Capacity property. You can specify an initial capacity in the constructor (new StringBuilder(initialCapacity)). If you have a good estimate of the final string length, setting an initial capacity can prevent some intermediate reallocations, further optimizing performance.
Other Efficient Methods:
string.Join(): As seen in 3.8.3, this method is highly optimized for concatenating elements of a collection with a separator, as it computes the final string length upfront and allocates the result string only once.List<string> items = new List<string> { "Apple", "Banana", "Cherry" }; string fruits = string.Join(", ", items); // Efficiently creates "Apple, Banana, Cherry"Span<char>/ReadOnlySpan<char>(Advanced, C# 7.2+): For extremely high-performance scenarios where you need to process parts of strings without any allocations,Span<char>(for mutable buffers) andReadOnlySpan<char>(for immutable buffers like strings) are invaluable. They provide a “view” into existing memory. While you can’t modify astringviaReadOnlySpan<char>, you can efficiently search, slice, and manipulate the characters without creating new string objects. These are part of “high-performance types” and will be discussed in depth in Chapter 8.5.
11.1.5. Comprehensive String Formatting
C# provides powerful mechanisms for formatting strings, from traditional string.Format to the modern and highly optimized interpolated strings.
-
string.Format(): This traditional static method uses composite formatting, where placeholders{0},{1}, etc., in a format string are replaced by the string representation of arguments.int age = 30; string name = "Alice"; string message = string.Format("Name: {0}, Age: {1}.", name, age); Console.WriteLine(message); // Output: Name: Alice, Age: 30. -
Interpolated Strings (
$"") (C# 6+): Introduced in C# 6, interpolated strings provide a more readable and concise syntax for string formatting. They are prefixed with a$character, and expressions are embedded directly within curly braces{}. The C# compiler translates these into calls tostring.Format()orstring.Concat().int age = 30; string name = "Bob"; string message = $"Name: {name}, Age: {age}."; // Much cleaner! Console.WriteLine(message); // Output: Name: Bob, Age: 30.Performance Enhancements:
DefaultInterpolatedStringHandler(C# 10+) Starting with C# 10, the compiler can apply significant optimizations to interpolated strings by usingSystem.Runtime.CompilerServices.DefaultInterpolatedStringHandler. Instead of translating all interpolated strings intostring.Format()(which can involve boxing value types and creating intermediateobject[]arrays) orstring.Concat(), for many common scenarios, the compiler can now:- Create an instance of
DefaultInterpolatedStringHandler(often aref struct, eliminating heap allocation for the handler itself). - Append parts of the interpolated string (literals, formatted values) directly to its internal
charbuffer. - Finally, call
handler.ToStringAndClear()to produce the finalstring.
This means that for simple interpolated strings, or those where the final string length can be pre-calculated, zero intermediate allocations might occur during the formatting process, leading to substantial performance improvements and reduced GC pressure.
Example where optimization likely applies (simple string + int):
string s = $"User ID: {userId}";Example where optimization might not apply (e.g., dynamic format strings, IFormatProvider, or many complex arguments):
string s = string.Format(CultureInfo.InvariantCulture, "The value is {0:N2}", someDouble);Or if you capture the interpolated string as anIFormattable:IFormattable formattable = $"Value: {value}"; // Optimization is often bypassed here. - Create an instance of
-
Format Specifiers (Deep Dive): Both
string.Format()and interpolated strings support format specifiers that control how values are converted to their string representation. A format specifier is placed after a colon within the curly braces:{expression:formatString}.-
Standard Numeric Format Strings:
Corc: Currency (e.g.,$1,234.50)Dord: Decimal (integer only, padding with leading zeros, e.g.,123,001)Eore: Exponential (e.g.,1.234560E+003)Forf: Fixed-point (e.g.,1234.56)Gorg: General (compact of F or E,1234.56or1.23E+003)Norn: Number (with group separators, e.g.,1,234.50)Porp: Percentage (multiplies by 100, e.g.,12.35 %)Xorx: Hexadecimal (e.g.,4D2or4d2)
double amount = 1234.567; Console.WriteLine($"Currency: {amount:C}"); // Output: $1,234.57 (culture dependent) Console.WriteLine($"Number: {amount:N1}"); // Output: 1,234.6 Console.WriteLine($"Hex: {255:X}"); // Output: FF -
Standard Date and Time Format Strings:
d: Short date pattern (e.g.,7/5/2025)D: Long date pattern (e.g.,Friday, July 5, 2025)t: Short time pattern (e.g.,8:37 PM)T: Long time pattern (e.g.,8:37:23 PM)o: Round-trip date/time pattern (ISO 8601, preserves timezone:2025-07-05T20:37:23.1234567Z) - Highly recommended for serialization/deserialization.s: Sortable date/time pattern (ISO 8601:2025-07-05T20:37:23) - No timezone.
DateTime now = DateTime.Now; Console.WriteLine($"Date: {now:d}"); Console.WriteLine($"Full: {now:o}"); // Good for serialization -
Custom Format Strings: Allow highly specific formatting using individual pattern characters. (e.g.,
"{0:yyyy-MM-dd HH:mm:ss}","{0:###,##0.00}"). For a comprehensive list of standard and custom format specifiers, refer to the Standard Numeric Format Strings and Standard Date and Time Format Strings documentation. -
Alignment and Padding: You can specify minimum field width and alignment.
alignmentis a signed integer: positive for right-alignment, negative for left-alignment.string name = "Alice"; int score = 123; Console.WriteLine($"|{name,-10}|{score,5}|"); // Output: |Alice | 123|
-
-
IFormattableandToString(string? format, IFormatProvider? formatProvider): Any type can implement theIFormattableinterface to provide custom string formatting behavior. TheToStringmethod withformatandformatProviderparameters is central to this. TheformatProvider(typically aCultureInfoobject) allows for culture-specific formatting.
11.1.6. CompositeFormat: Pre-parsing for Performance (New in .NET 8)
The traditional string.Format() method and even interpolated strings (prior to C# 10’s DefaultInterpolatedStringHandler optimizations, or in scenarios where those optimizations don’t apply) internally parse the format string on every call. For applications that frequently use the same format string, this repeated parsing can introduce unnecessary overhead, leading to increased CPU usage and potential garbage collection pressure from temporary allocations.
CompositeFormat, introduced in .NET 8, directly addresses this performance concern by allowing you to pre-parse a format string once and reuse its compiled representation for subsequent formatting operations.
- Purpose: To optimize string formatting performance by performing the parsing of the format string only once, eliminating repetitive runtime parsing overhead for frequently used format strings.
- Mechanism: Instead of passing a raw string literal to
string.Format(), you first pass it toCompositeFormat.Parse(). This method analyzes the format string (identifying placeholders, alignment, format specifiers) and creates an immutableCompositeFormatobject. This object encapsulates the parsed structure. Subsequent calls tostring.Format()(orStringBuilder.AppendFormat()) can then accept this pre-parsedCompositeFormatobject, skipping the parsing step. -
Usage Pattern:
- Parse the format string: Use
CompositeFormat.Parse()to create aCompositeFormatinstance. For format strings that require a specificIFormatProvider(e.g., for culture-specific numeric or date formatting), useCompositeFormat.Parse(string format, IFormatProvider provider). - Store and Reuse: Crucially, store the
CompositeFormatinstance in astatic readonlyfield. This ensures it’s parsed only once when the type is initialized and can be safely reused across multiple calls and threads. - Format with the parsed object: Call overloads of
string.FormatorStringBuilder.AppendFormatthat accept aCompositeFormatobject. These overloads are specifically designed to leverage the pre-parsed format.
using System.Buffers; // Needed for CompositeFormat using System.Text; // Needed for StringBuilder // Example class demonstrating CompositeFormat usage class PerformanceLogger { // Define a static readonly CompositeFormat instance for a frequently used log message format. // This format string is parsed only ONCE when PerformanceLogger is first accessed. private static readonly CompositeFormat _detailedLogFormat = CompositeFormat.Parse("[{0:yyyy-MM-dd HH:mm:ss.fff}] Thread: {1,-5} Level: {2,-8} Message: {3}"); public void LogMessage(string threadName, string level, string message) { // Use the pre-parsed CompositeFormat instance for efficient formatting. string logOutput = string.Format(_detailedLogFormat, DateTime.Now, threadName, level, message); Console.WriteLine(logOutput); } // For comparison, the unoptimized approach public void LogMessageUnoptimized(string threadName, string level, string message) { // The format string is parsed on *every* call to string.Format string logOutput = string.Format("[{0:yyyy-MM-dd HH:mm:ss.fff}] Thread: {1,-5} Level: {2,-8} Message: {3}", DateTime.Now, threadName, level, message); Console.WriteLine(logOutput); } } void DemonstrateCompositeFormatPerformance() { Console.WriteLine("--- Demonstrating CompositeFormat ---"); var logger = new PerformanceLogger(); logger.LogMessage("Main", "INFO", "Application started."); logger.LogMessage("Worker", "DEBUG", "Processing data batch."); Console.WriteLine("\n--- Performance Comparison (1,000,000 iterations) ---"); int iterations = 1_000_000; var stopwatch = new System.Diagnostics.Stopwatch(); // Test unoptimized formatting stopwatch.Start(); for (int i = 0; i < iterations; i++) { // Create dummy data for each iteration to simulate real-world variability DateTime current = DateTime.UtcNow.AddMilliseconds(i); string thread = (i % 2 == 0) ? "ThreadA" : "ThreadB"; string level = (i % 3 == 0) ? "INFO" : "DEBUG"; string msg = $"Operation {i} completed."; _ = string.Format("[{0:yyyy-MM-dd HH:mm:ss.fff}] Thread: {1,-5} Level: {2,-8} Message: {3}", current, thread, level, msg); } stopwatch.Stop(); Console.WriteLine($"Unoptimized string.Format took: {stopwatch.ElapsedMilliseconds} ms"); stopwatch.Reset(); // Test optimized CompositeFormat // The _detailedLogFormat is parsed only once at class load time, not in this loop. stopwatch.Start(); for (int i = 0; i < iterations; i++) { // Create dummy data DateTime current = DateTime.UtcNow.AddMilliseconds(i); string thread = (i % 2 == 0) ? "ThreadA" : "ThreadB"; string level = (i % 3 == 0) ? "INFO" : "DEBUG"; string msg = $"Operation {i} completed."; _ = string.Format(PerformanceLogger._detailedLogFormat, current, thread, level, msg); } stopwatch.Stop(); Console.WriteLine($"Optimized CompositeFormat took: {stopwatch.ElapsedMilliseconds} ms"); // On a typical machine, the optimized version should be noticeably faster, // often by 15-30% or more depending on the complexity of the format string and number of arguments. } - Parse the format string: Use
-
Benefits:
- Reduced CPU Overhead: The most significant benefit is the elimination of repeated parsing logic. For applications with high string formatting throughput (e.g., logging frameworks, network protocol serializers, high-frequency data processing), this translates directly into lower CPU utilization.
- Lower GC Pressure: By avoiding temporary parsing-related allocations for each call,
CompositeFormatcan contribute to reduced garbage collection activity, leading to more consistent performance and fewer pauses. - Clarity for Complex Formats: While
CompositeFormatdoesn’t change the readability of the format string itself, explicitly declaring it as astatic readonlyCompositeFormatobject clearly signals its intent for reuse and performance optimization.
- Considerations and Trade-offs:
- Initial Parsing Cost: There is a one-time cost when
CompositeFormat.Parse()is called. For format strings used infrequently, this initial parsing overhead might outweigh the benefits.CompositeFormatis best for format strings that are used many times. - Immutability and Thread Safety:
CompositeFormatinstances are immutable and inherently thread-safe, making them ideal forstatic readonlyfields. - Fixed Format Strings: It is primarily designed for fixed, known-at-compile-time format strings that are reused. It’s not intended for entirely dynamic format strings (e.g., format strings coming from user input) unless you have a specific pattern of frequently repeated dynamic formats you want to cache.
- Runtime Version: As a .NET 8 feature,
CompositeFormatrequires your application to target .NET 8 or newer.
- Initial Parsing Cost: There is a one-time cost when
CompositeFormat is a valuable tool in the arsenal of an experienced .NET developer, providing a clear path to optimizing string formatting in performance-critical sections of an application where traditional string.Format or even C# 9 and earlier interpolated strings might incur too much overhead.
11.1.7. String Utility Methods and Best Practices
The string class provides a rich set of utility methods for common operations.
-
Null and Empty Checks:
string.IsNullOrEmpty(string? value): Returnstrueifvalueisnullor an empty string (""). This is the most common and generally recommended check for “has content.”string.IsNullOrWhiteSpace(string? value): Returnstrueifvalueisnull,"", or consists only of whitespace characters (spaces, tabs, newlines, etc.). This is highly recommended for validating user input, as a string of spaces often isn’t meaningful.
string s1 = null; string s2 = ""; string s3 = " "; string s4 = "hello"; Console.WriteLine($"IsNullOrEmpty(s1): {string.IsNullOrEmpty(s1)}"); // True Console.WriteLine($"IsNullOrEmpty(s2): {string.IsNullOrEmpty(s2)}"); // True Console.WriteLine($"IsNullOrEmpty(s3): {string.IsNullOrEmpty(s3)}"); // False Console.WriteLine($"IsNullOrWhiteSpace(s3): {string.IsNullOrWhiteSpace(s3)}"); // True -
String Comparison: Comparing strings correctly, especially across cultures or when case-insensitivity is desired, is crucial.
-
==Operator forstring(Value Equality): Unlike most other reference types where==performs reference equality (checking if two references point to the exact same object in memory), the==operator forstringtypes is overloaded to perform value equality. This meanss1 == s2checks if the character sequences ofs1ands2are identical, not if they are the same object. This is a special and very convenient behavior for strings.string a = "test"; string b = "test"; string c = new StringBuilder().Append("test").ToString(); Console.WriteLine($"a == b: {a == b}"); // True (value equality, also likely reference equality due to interning) Console.WriteLine($"a == c: {a == c}"); // True (value equality) Console.WriteLine($"ReferenceEquals(a, c): {ReferenceEquals(a, c)}"); // False (different objects) -
string.Equals()Overloads andStringComparisonEnum: For precise control over string comparisons (case-sensitivity, culture-awareness, performance), always use thestring.Equals()method, especially the overloads that accept aStringComparisonenumeration member. This explicitly states your intent and avoids common pitfalls.StringComparison.Ordinal: Performs a simple byte-by-byte comparison. This is the fastest and most reliable for culture-insensitive comparisons (e.g., file paths, keys, protocol elements). Highly recommended for non-linguistic comparisons.StringComparison.OrdinalIgnoreCase: Ordinal comparison, ignoring case. Faster than culture-sensitive options for case-insensitive checks. Recommended for case-insensitive non-linguistic comparisons.StringComparison.CurrentCulture: Uses the rules of the current culture for comparison. This can be influenced by user settings and can lead to different results on different machines.StringComparison.CurrentCultureIgnoreCase: Current culture, ignoring case.StringComparison.InvariantCulture: Uses the culture-invariant comparison rules (a fixed, global culture). Useful for storing or comparing data consistently across cultures.StringComparison.InvariantCultureIgnoreCase: Invariant culture, ignoring case.
string s5 = "Straße"; // German for "Street" string s6 = "Strasse"; // Common transliteration // Current culture might treat them as equal Console.WriteLine($"CurrentCulture: {s5.Equals(s6, StringComparison.CurrentCulture)}"); // Output: True (in some German cultures) // Ordinal treats them as different characters Console.WriteLine($"Ordinal: {s5.Equals(s6, StringComparison.Ordinal)}"); // Output: False Console.WriteLine($"Case-insensitive (Ordinal): {"hello".Equals("HELLO", StringComparison.OrdinalIgnoreCase)}"); // Output: TrueBest Practice: Always specify
StringComparison.OrdinalorStringComparison.OrdinalIgnoreCaseunless you explicitly need culture-sensitive linguistic rules. This improves clarity, predictability, and often performance. -
string.Compare(): Provides a richer comparison (returns -1, 0, or 1) and also supportsStringComparisonfor ordering.
-
-
Other Manipulation Methods: C# strings offer a wealth of methods for common operations:
Contains(),StartsWith(),EndsWith(): For substring checks.IndexOf(),LastIndexOf(): For finding character/substring positions.Substring(): For extracting parts of a string.Replace(): For replacing characters or substrings.Trim(),TrimStart(),TrimEnd(): For removing leading/trailing whitespace.ToUpper(),ToLower(): For case conversion (culture-sensitive by default; useToUpperInvariant()/ToLowerInvariant()for culture-agnostic).
11.1.8. Encodings and Globalization for Strings
Strings are sequences of characters, but when interacting with external systems (files, networks, databases), these characters must be represented as bytes. This conversion process is handled by encodings.
-
Internal UTF-16: In .NET,
System.Stringinternally represents characters using UTF-16 encoding. Each character generally occupies 2 bytes (or 4 bytes for surrogate pairs representing characters outside the Basic Multilingual Plane). -
System.Text.Encoding: TheSystem.Text.Encodingclass and its derived types (e.g.,Encoding.UTF8,Encoding.ASCII,Encoding.Unicode) are responsible for converting between sequences of characters (strings) and sequences of bytes.using System.Text; string text = "Hello, world!"; byte[] utf8Bytes = Encoding.UTF8.GetBytes(text); // String to UTF-8 bytes string decodedText = Encoding.UTF8.GetString(utf8Bytes); // UTF-8 bytes back to string Console.WriteLine($"Original: {text}"); Console.WriteLine($"UTF-8 Bytes: {BitConverter.ToString(utf8Bytes)}"); Console.WriteLine($"Decoded: {decodedText}"); // Handling different encodings for files, network streams, etc. string someGermanText = "Straße"; byte[] isoLatin1Bytes = Encoding.GetEncoding("ISO-8859-1").GetBytes(someGermanText); Console.WriteLine($"ISO-8859-1 Bytes for 'Straße': {BitConverter.ToString(isoLatin1Bytes)}");Best Practice: Always be explicit about the encoding when converting between strings and bytes, especially when dealing with external data sources. UTF-8 (
Encoding.UTF8) is generally the recommended default for new applications due to its widespread compatibility and efficiency. -
Globalization and
CultureInfo: Many string operations (like comparison, casing, and formatting) are culture-sensitive. This means their behavior can depend on the current culture settings of the operating system or the application.System.Globalization.CultureInfo: Provides information about a specific culture (e.g., date formats, currency symbols, sorting rules, casing rules).- Culture-Sensitive vs. Culture-Invariant:
- Methods like
ToLower(),ToUpper(),string.Equals(other), orstring.Format()without aCultureInfoparameter will use the current culture. - For consistent behavior regardless of the user’s regional settings (e.g., for data storage, internal identifiers, or network protocols), use culture-invariant operations. This means specifying
StringComparison.InvariantCulture,ToString(..., CultureInfo.InvariantCulture), orToUpperInvariant()/ToLowerInvariant().
- Methods like
using System.Globalization; string turkishLower = "istanbul"; string turkishUpper = "İSTANBUL"; // Capital I with dot above // Default ToUpper() is culture-sensitive Console.WriteLine($"'i'.ToUpper() in current culture: {'i'.ToString().ToUpper()}"); // Output: I (often) Console.WriteLine($"'i'.ToUpper() in Turkish: {'i'.ToString().ToUpper(new CultureInfo("tr-TR"))}"); // Output: İ // For invariant operations Console.WriteLine($"'i'.ToUpperInvariant(): {'i'.ToString().ToUpperInvariant()}"); // Output: I Console.WriteLine($"'a'.Equals('A', StringComparison.InvariantCultureIgnoreCase): {("a").Equals("A", StringComparison.InvariantCultureIgnoreCase)}"); // TrueBest Practice: Be deliberate about your culture-awareness. For UI display, use current culture. For internal logic, data storage, or network communication, use culture-invariant or ordinal string operations to avoid unexpected behavior based on locale.
11.2. Enumerations (enum): Underlying Types, Flags, and Best Practices
Enumerations (enum) in C# provide a way to define a set of named integral constants. They enhance code readability, maintainability, and type safety by allowing you to represent a fixed set of related values with meaningful names, rather than using “magic numbers.”
11.2.1. Underlying Types of Enumerations
Every enum type implicitly has an underlying integral type, which is the actual data type used to store its members’ values. By default, this underlying type is int. However, you can explicitly specify any of the following integral types: byte, sbyte, short, ushort, int, uint, long, or ulong.
-
Default Behavior (
int): If no underlying type is specified,intis used. The compiler automatically assigns integer values to the enum members, starting from0and incrementing by1for each subsequent member, unless explicitly assigned.enum Color // Underlying type is int by default { Red, // 0 Green, // 1 Blue // 2 } enum Status { None = 0, Active, // 1 Inactive = 5, Pending // 6 (continues from 5) } void DemonstrateDefaultEnum() { Color myColor = Color.Green; Console.WriteLine($"My color: {myColor} ({(int)myColor})"); // Output: My color: Green (1) Status currentStatus = Status.Pending; Console.WriteLine($"Current status: {currentStatus} ({(int)currentStatus})"); // Output: Current status: Pending (6) } -
Explicitly Specifying Underlying Types: Choosing a smaller underlying type (e.g.,
byteorshort) can save memory, particularly when you have very large arrays or collections of enum values. However, the memory savings are often negligible for individual enum instances, andintis typically preferred for its balance of range and computational efficiency on most modern processors.longorulongare necessary for enums that need to represent very large ranges of values, especially when used with the[Flags]attribute for bitwise combinations.enum TinyStatusCode : byte // Uses byte as underlying type { Success = 0, Failure = 1, Timeout = 2 } enum LargeIdType : long // Uses long as underlying type { MinId = 0L, MaxId = 9_223_372_036_854_775_807L // Example large value } void DemonstrateExplicitEnumTypes() { TinyStatusCode code = TinyStatusCode.Success; Console.WriteLine($"Tiny status: {code} (size: {Unsafe.SizeOf<TinyStatusCode>()} byte)"); // Output: Tiny status: Success (size: 1 byte) LargeIdType id = LargeIdType.MinId; Console.WriteLine($"Large ID: {id} (size: {Unsafe.SizeOf<LargeIdType>()} bytes)"); // Output: Large ID: 0 (size: 8 bytes) }Note:
System.Runtime.CompilerServices.Unsafe.SizeOf<T>()can be used to check the actual memory size of a value type.
11.2.2. Flags Enumerations and Bitwise Operations
The [Flags] attribute is applied to an enum type to indicate that it can be treated as a bit field; that is, a set of flags that can be combined using bitwise OR operations. Each member of a [Flags] enum should be assigned a power-of-two value (1, 2, 4, 8, etc.) so that each flag corresponds to a unique bit position.
-
Purpose of
[Flags]:- To represent a combination of independent options or states.
- To allow
enummembers to be combined using bitwise logical operators (|for OR,&for AND,~for NOT,^for XOR). - To improve readability when printing combined enum values (e.g.,
Read | Writewill print as “Read, Write” instead of just “3” if the attribute is present).
-
Defining a Flags Enum: Assign powers of two to each member. A
NoneorZeromember with value0is common and represents no flags being set.[Flags] enum FileAccess : byte // byte is sufficient if max 8 flags { None = 0, Read = 1, // 0001 Write = 2, // 0010 Delete = 4, // 0100 Execute = 8, // 1000 // Combinations (optional, but can improve readability) ReadWrite = Read | Write, // 0011 (3) All = Read | Write | Delete | Execute // 1111 (15) } void DemonstrateFlagsEnum() { FileAccess userPermissions = FileAccess.Read | FileAccess.Write; Console.WriteLine($"User permissions: {userPermissions}"); // Output: User permissions: Read, Write // Checking if a specific flag is set (using bitwise AND) if ((userPermissions & FileAccess.Read) == FileAccess.Read) { Console.WriteLine("User has Read permission."); } // Checking if ANY of a set of flags is set if ((userPermissions & (FileAccess.Delete | FileAccess.Execute)) != 0) { Console.WriteLine("User has Delete or Execute permission."); // This will not print } // Removing a flag (using bitwise XOR or AND with NOT) userPermissions ^= FileAccess.Write; // Equivalent to userPermissions &= ~FileAccess.Write; Console.WriteLine($"Permissions after removing Write: {userPermissions}"); // Output: Permissions after removing Write: Read // Combining existing permissions with new ones userPermissions |= FileAccess.Delete; Console.WriteLine($"Permissions after adding Delete: {userPermissions}"); // Output: Permissions after adding Delete: Read, Delete } -
Best Practices for Flags Enums:
- Powers of Two: Always assign powers of two to individual flags (1, 2, 4, 8, 16, etc.) to ensure unique bit positions.
NoneMember: Include aNoneorZeromember with a value of0. This is useful for representing a state where no flags are set.- Combinations (Optional but Recommended): You can define composite members by bitwise OR-ing individual flags (e.g.,
ReadWrite = Read | Write). This improves readability. - Underlying Type: Choose an underlying type (
byte,short,int,long) large enough to accommodate all potential flag combinations.intis often sufficient, butlongmight be needed for more than 31 flags. -
Usage with
HasFlag(): For checking if an enum value has a specific flag, theHasFlag()method (available on all enums since .NET 4) is often more readable than manual bitwise AND operations. However, for performance-critical scenarios, direct bitwise operations (&) can be slightly faster asHasFlagmight involve a bit more overhead.FileAccess permissions = FileAccess.Read | FileAccess.Execute; // Using HasFlag if (permissions.HasFlag(FileAccess.Read)) { Console.WriteLine("Has Read flag (using HasFlag)."); } // Using bitwise AND (often preferred for direct check due to potential performance) if ((permissions & FileAccess.Execute) == FileAccess.Execute) { Console.WriteLine("Has Execute flag (using &)."); }
-
Pitfall: Checking for
NonewithHasFlag: Be cautious when checking for theNoneflag usingHasFlag.(A | B).HasFlag(None)will always returntruebecauseNone(0) is a subset of any combination. To check if no flags are set, simply compare the enum value to0orFileAccess.None:FileAccess noPermissions = FileAccess.None; Console.WriteLine($"No permissions has None flag: {noPermissions.HasFlag(FileAccess.None)}"); // True Console.WriteLine($"Read permissions has None flag: {(FileAccess.Read).HasFlag(FileAccess.None)}"); // True (!!!) Console.WriteLine($"No permissions is None: {noPermissions == FileAccess.None}"); // True (Correct way)
11.2.3. Best Practices for Defining and Consuming Enumerations
- Clarity and Naming:
- Use singular names for non-flags enums (e.g.,
Color,OrderStatus). - Use plural names for flags enums (e.g.,
FileAccess,Permissions,BindingFlags). - Ensure enum member names are PascalCase and descriptive.
- Use singular names for non-flags enums (e.g.,
- Avoid Exposed Underlying Values: While you can cast an enum to its underlying integer type, avoid relying on specific numeric values in your logic unless strictly necessary (e.g., for serialization to external systems or bitwise operations with flags). This makes your code more robust to changes in enum definitions.
-
Input Validation: When converting an integer to an enum type, always validate the input. An integer value that doesn’t correspond to a defined enum member is still a valid underlying value, but it represents an invalid enum state.
enum MyEnum { ValueA = 1, ValueB = 2 } int input = 99; MyEnum myEnumValue = (MyEnum)input; // This cast is always successful, but the value is invalid if (!Enum.IsDefined(typeof(MyEnum), input)) { Console.WriteLine($"Warning: {input} is not a defined value for MyEnum."); } // Use Enum.TryParse for safe parsing from string if (Enum.TryParse("ValueA", out MyEnum parsedEnum)) { Console.WriteLine($"Parsed enum: {parsedEnum}"); } - Extending Enums:
Enums cannot be extended directly. If you need to add more values over time, consider if an
enumis the right choice, or if a class hierarchy orconstfields with astaticclass might be more appropriate, especially if behavior is tied to the “enum” values. However, for a fixed set of constants,enumremains the idiomatic choice. - Source Generation for
Enum.ToString()andEnum.Parse()(C# 11+): CallingEnum.ToString()orEnum.Parse()(especially with string arguments) can incur boxing and reflection overhead, which may be slow in performance-critical loops. C# 11 and .NET 7 introduced enum source generators (available via NuGet packages or implicitly in some contexts) that generate highly optimized, allocation-free methods for converting enums to strings and vice-versa. This can significantly improve performance for these common operations. For example, you might useEnum.GetName<MyEnum>(value)orEnum.Parse<MyEnum>(string)which, with the source generator, will be optimized. Reference: Enum performance improvements in .NET 7
11.2.4. Enum Under the Hood
When an enum is compiled, it’s essentially a special kind of value type that wraps an integral type. The names you define (e.g., Red, Green) become named constants associated with specific integer values in the compiled assembly’s metadata.
- Boxing: When you treat an enum as an
object(e.g., passing it to a method expectingobject, or callingToString()without specific optimizations), it undergoes boxing, creating a new object on the heap. This can lead to allocations and GC pressure in performance-sensitive code. The source generators forToString()andParse()help mitigate this. - Casting: Casting between an enum and its underlying type is a direct bitwise conversion, incurring almost no overhead.
Color myColor = Color.Blue; int colorValue = (int)myColor; // No boxing, direct cast Color parsedColor = (Color)colorValue; // No boxing, direct cast
In summary, enumerations are powerful constructs for representing fixed sets of named constants. Understanding their underlying integral types, the proper use of the [Flags] attribute for bitwise combinations, and adhering to best practices ensures robust, readable, and performant code.
11.3. Arrays and List<T>: Memory, Performance, and Related Types
Arrays and List<T> are two of the most fundamental data structures in C# for storing collections of elements. While Array is a fixed-size, lower-level construct, List<T> provides a dynamic, higher-level abstraction. Understanding their internal mechanisms is key to optimizing memory usage and performance.
11.3.1. System.Array Internals
System.Array is the abstract base class for all array types in C#. All arrays in C# (e.g., int[], string[], MyClass[,]) implicitly derive from System.Array.
-
Fixed Size and Contiguous Memory:
- Once an array is created, its size is fixed and cannot be changed.
- Elements of an array are stored in a contiguous block of memory on the managed heap. This contiguous allocation allows for very fast, direct access to elements using an index (O(1) time complexity).
- When you create an array (e.g.,
new int[100]), the CLR allocates a block of memory for 100 integers, plus some overhead for the array object header (containing length, type information, etc.).
int[] numbers = new int[5]; // Allocates memory for 5 integers + overhead numbers[0] = 10; // Direct memory access numbers[4] = 50; // The following would cause an IndexOutOfRangeException: // numbers[5] = 60; -
Value Types vs. Reference Types in Arrays:
- Value Type Arrays (
int[],struct[]): The array directly stores the values of the elements. All elements are initialized to their default value (e.g.,0forint,nullforbool).int[] intArray = new int[3]; // intArray[0]=0, intArray[1]=0, intArray[2]=0 - Reference Type Arrays (
string[],MyClass[]): The array stores references (pointers) to objects on the heap. The actual objects are stored elsewhere on the heap. Elements are initialized tonullby default.csharp string[] stringArray = new string[2]; // stringArray[0]=null, stringArray[1]=null stringArray[0] = "Hello"; // "Hello" object on heap, stringArray[0] points to it.This distinction is crucial for understanding memory consumption. Astruct[]takes upsize_of_struct * countbytes (plus array overhead), while aclass[]takes upsize_of_reference * countbytes (typically 4 or 8 bytes per reference) plus the memory for each individual object pointed to.
- Value Type Arrays (
-
Multi-Dimensional Arrays: C# supports two types of multi-dimensional arrays:
- Rectangular Arrays (
int[,],string[,,]): These are single block of contiguous memory, and all rows/dimensions have the same length. Accessing elements is very efficient.int[,] matrix = new int[2, 3] { { 1, 2, 3 }, { 4, 5, 6 } }; Console.WriteLine($"Matrix element [0,1]: {matrix[0, 1]}"); // Output: 2 - Jagged Arrays (
int[][],string[][]): These are arrays of arrays. Each “row” can have a different length. They are less memory-contiguous than rectangular arrays (as each inner array is a separate object), but offer more flexibility.csharp int[][] jaggedArray = new int[3][]; jaggedArray[0] = new int[] { 1, 2, 3 }; jaggedArray[1] = new int[] { 4, 5 }; jaggedArray[2] = new int[] { 6 }; Console.WriteLine($"Jagged array element [0][1]: {jaggedArray[0][1]}"); // Output: 2Rectangular arrays are often faster for truly uniform grids, while jagged arrays are more flexible and can sometimes represent sparse data more efficiently.
- Rectangular Arrays (
-
Array Covariance (Reference Types Only): For arrays of reference types, C# supports array covariance, meaning if
Sis a subclass ofT, thenS[]can be implicitly converted toT[].object[] objArray = new string[5]; // Valid: string[] is covariant with object[] objArray[0] = "Hello"; // Valid // objArray[1] = 123; // Runtime error (ArrayTypeMismatchException): cannot put int into string arrayWhile seemingly convenient, array covariance for reference types is generally discouraged due to the runtime cost of type checks on writes (to prevent putting an incompatible type into the array) and the potential for
ArrayTypeMismatchException. It’s better to use generic collections (List<object>,List<string>) to maintain strong typing and avoid these runtime checks. Value type arrays are invariant (e.g.,int[]cannot be cast toobject[]).
11.3.2. List<T> Internals
List<T> is a generic collection that provides a dynamic, resizable array. It’s built on top of an underlying T[] (array), managing its size automatically.
-
Capacity vs. Count:
Count: The number of elements actually present in theList<T>.Capacity: The total number of elements that the internal array can hold before resizing is required. TheCapacityis always greater than or equal toCount.
-
Dynamic Resizing Mechanism: When you add an element to a
List<T>usingAdd()and itsCountreaches itsCapacity, theList<T>performs the following operations:- It allocates a new, larger internal array (typically doubling its current
Capacity). - It copies all existing elements from the old array to the new, larger array.
- It discards the old array (making it eligible for garbage collection).
- It then adds the new element to the new array.
List<int> numbers = new List<int>(); // Count = 0, Capacity = 0 (or some small default, typically 4) numbers.Add(1); // Count = 1, Capacity = 4 numbers.Add(2); // Count = 2, Capacity = 4 numbers.Add(3); // Count = 3, Capacity = 4 numbers.Add(4); // Count = 4, Capacity = 4 numbers.Add(5); // Count = 5, Capacity = 8 (new array allocated, old 4-element array copied)This doubling strategy leads to an amortized O(1) time complexity for
Add()operations. While an individualAdd()might be O(N) (due to reallocation and copying), over a sequence of N additions, the total cost averages out because reallocations happen exponentially less often. - It allocates a new, larger internal array (typically doubling its current
-
Performance Implications:
Add(): Amortized O(1). Fast on average, but occasional O(N) spikes during reallocations.Insert(index, item): O(N) because all subsequent elements fromindextoCount-1must be shifted to make room for the new element. This also applies if a reallocation is needed.Remove(item)/RemoveAt(index): O(N) because elements after the removed item must be shifted to fill the gap.- Indexer Access (
list[index]): O(1) as it’s direct array access. Contains(): O(N) as it performs a linear search (unlessTimplementsIEquatable<T>and you useHashSet<T>for lookup instead).
-
Optimizing
List<T>Performance:- Pre-allocate Capacity: If you know the approximate number of elements beforehand, initialize
List<T>with a sufficient initial capacity. This can significantly reduce the number of reallocations, improving performance.List<string> largeList = new List<string>(100_000); // Prevents many reallocations for (int i = 0; i < 100_000; i++) { largeList.Add($"Item {i}"); } AddRange(): UseAddRange()to add multiple elements from another collection efficiently. This allowsList<T>to resize once for the entire batch if needed, rather than one by one.- Avoid
Insert()/Remove()in Loops: For frequent insertions/deletions in the middle of a large list,LinkedList<T>or other data structures might be more appropriate. TrimExcess(): If you’ve added many elements and then removed a significant portion,Capacitymight still be much larger thanCount.TrimExcess()can be called to reduce theCapacitytoCount, freeing up memory. Use this sparingly, as it involves an O(N) copy operation.
- Pre-allocate Capacity: If you know the approximate number of elements beforehand, initialize
11.3.3. Interacting with Span<T> and ReadOnlySpan<T>
Span<T> and ReadOnlySpan<T> (introduced in C# 7.2) are powerful ref struct types that provide a type-safe, memory-efficient way to work with contiguous blocks of memory, including arrays and portions of arrays, without incurring allocations. They are critical for high-performance scenarios where copying data is a bottleneck.
-
AsSpan()Method: Arrays andList<T>(since .NET Core 2.1 / .NET Standard 2.1) provide anAsSpan()extension method (or direct method forArray) that creates aSpan<T>orReadOnlySpan<T>over their internal data. This operation is zero-allocation; it simply creates a newref structthat points to the existing memory. -
Efficient Slicing:
Span<T>andReadOnlySpan<T>allow you to create “slices” (sub-spans) of the original data. This also involves zero allocation, as the new span simply adjusts its internal pointer and length.int[] numbers = { 10, 20, 30, 40, 50, 60, 70, 80, 90, 100 }; Span<int> fullSpan = numbers.AsSpan(); // Span over the entire array Span<int> middleSpan = fullSpan.Slice(3, 4); // Slice from index 3, length 4 (40, 50, 60, 70) Console.WriteLine($"Middle Span: {string.Join(", ", middleSpan.ToArray())}"); // ToArray() *does* allocate // Modifying through a Span middleSpan[0] = 45; // This modifies the original 'numbers' array Console.WriteLine($"Original array after span modification: {string.Join(", ", numbers)}"); // Output: Original array after span modification: 10, 20, 30, 45, 50, 60, 70, 80, 90, 100 // List<T> also supports AsSpan() List<string> names = new List<string> { "Alice", "Bob", "Charlie", "David" }; ReadOnlySpan<string> nameSpan = names.AsSpan(1, 2); // ReadOnlySpan from index 1, length 2 (Bob, Charlie) Console.WriteLine($"Names Span: {string.Join(", ", nameSpan.ToArray())}"); - Benefits:
- Zero Allocations for Views: Enables operations like slicing, substring-like behavior, and passing portions of buffers to methods without creating new copies of the data. This drastically reduces heap allocations and garbage collection pressure.
- Performance: Avoiding allocations means less work for the GC, leading to faster execution times in tight loops or high-throughput scenarios.
- Type Safety: Provides strong type safety compared to raw pointers or
IntPtr. - Unified Abstraction:
Span<T>can abstract over arrays,stackallocmemory,Memory<T>, and even unmanaged memory, providing a consistent API.
-
Limitations:
Span<T>andReadOnlySpan<T>areref structs, meaning they can only exist on the stack. They cannot be stored in heap-allocated classes, captured by lambdas that become delegates, or used as generic type arguments for classes. This limitation prevents them from escaping the stack and becoming dangling pointers.ToArray()orToString()on a Span will cause an allocation if you need a heap-allocated copy.
- Cross-Referencing: For a more in-depth understanding of
ref structs andSpan<T>’s role in modern C# performance, refer to Chapter 8.5.
In conclusion, understanding the internal mechanics of Array and List<T> (their fixed vs. dynamic sizing, contiguous memory, and reallocation strategies) is crucial for selecting the right collection and optimizing its usage. The introduction of Span<T> and ReadOnlySpan<T> further enhances the ability to process array and list data with unparalleled memory efficiency.
11.4. Hash-Based Collections: Dictionary<TKey, TValue> and HashSet<T>
Dictionary<TKey, TValue> and HashSet<T> are two of the most commonly used collections in .NET, prized for their exceptional average-case performance in lookup, insertion, and deletion operations. Both are implemented using hash tables internally. A deep understanding of hashing, collision resolution, and their performance characteristics is vital for leveraging these collections effectively.
11.4.1. Hash Table Fundamentals
A hash table is a data structure that maps keys to values (for dictionaries) or simply stores unique elements (for sets) by using a hash function to compute an index, or hash code, into an array of buckets or slots.
- Hash Function: Takes an input object (the key or element) and returns an integer (the hash code). A good hash function:
- Is deterministic: always returns the same hash code for the same input.
- Is fast to compute.
- Distributes hash codes evenly across the possible range, minimizing collisions.
- Buckets (or Slots): The internal array where elements are stored. The hash code is typically used to determine the initial bucket index for an element (e.g.,
bucketIndex = hashCode % numberOfBuckets). - Collisions: A collision occurs when two different keys or elements produce the same hash code, or map to the same bucket index. This is inevitable with a finite number of buckets and an infinite (or very large) number of possible keys. Effective collision resolution is critical for performance.
11.4.2. Dictionary<TKey, TValue> Internals
Dictionary<TKey, TValue> is a hash table that stores key-value pairs, providing O(1) average-case performance for Add, Remove, ContainsKey, and indexed access (this[TKey]).
-
Key Requirements: For a type
TKeyto be used as a key inDictionary<TKey, TValue>, it must correctly implement:object.GetHashCode(): To produce a hash code for the key.object.Equals(object obj)orIEquatable<TKey>.Equals(TKey other): To compare keys for equality when a collision occurs (or to find the correct key if multiple keys hash to the same bucket). Note: Forstringkeys,GetHashCode()andEquals()are implemented efficiently. For custom reference types, ensure you override both or use a customIEqualityComparer<TKey>.
-
Collision Resolution (Chaining):
Dictionary<TKey, TValue>typically uses a technique called chaining (or separate chaining) to resolve collisions.- Each bucket in the internal array doesn’t store a single item but rather a reference to a linked list (or similar structure) of items that have hashed to that bucket.
- When adding an item:
- Compute the hash code for the key.
- Determine the bucket index.
- If the bucket is empty, place the item there.
- If the bucket is already occupied (a collision), traverse the linked list in that bucket. For each item in the list, use
Equals()to check if the key already exists. If it does, anArgumentExceptionis thrown (forAdd) or the value is updated (for indexerthis[TKey]). If it doesn’t, add the new item to the end of the list.
- When retrieving an item:
- Compute the hash code for the key.
- Determine the bucket index.
- Traverse the linked list in that bucket, using
Equals()to find the matching key.
-
Resizing (Rehashing): As more items are added, the number of collisions increases, leading to longer linked lists within buckets. This degrades performance, as lookups/adds become closer to O(N) (linear scan of a long list). To maintain O(1) average performance,
Dictionary<TKey, TValue>automatically resizes its internal bucket array when the load factor (number of items / number of buckets) exceeds a certain threshold (typically around 0.7-1.0).- Resizing involves allocating a new, larger array of buckets.
- All existing items must then be rehashed and redistributed into the new, larger set of buckets. This is an O(N) operation and can be expensive.
- If you know the approximate number of items upfront, initializing the dictionary with a sufficient
capacity(e.g.,new Dictionary<TKey, TValue>(initialCapacity)) can reduce or eliminate resizing operations, significantly improving performance.
void DemonstrateDictionary() { Dictionary<string, int> ages = new Dictionary<string, int>(); // Default capacity ages.Add("Alice", 30); ages.Add("Bob", 25); ages["Charlie"] = 35; // Add or update Console.WriteLine($"Alice's age: {ages["Alice"]}"); // Output: 30 if (ages.TryGetValue("David", out int davidAge)) { Console.WriteLine($"David's age: {davidAge}"); } else { Console.WriteLine("David not found."); } ages.Remove("Bob"); Console.WriteLine($"Contains Bob: {ages.ContainsKey("Bob")}"); // Output: False // Initializing with capacity Dictionary<int, string> preAllocated = new Dictionary<int, string>(1000); for (int i = 0; i < 1000; i++) { preAllocated.Add(i, $"Item {i}"); // No rehashes if capacity is sufficient } }
11.4.3. HashSet<T> Internals
HashSet<T> is a collection that stores unique elements. Like Dictionary<TKey, TValue>, it uses a hash table internally, providing O(1) average-case performance for Add, Remove, and Contains.
- Key Requirements: Similar to
Dictionary, the typeTused inHashSet<T>must correctly implementobject.GetHashCode()andobject.Equals()(orIEquatable<T>). - Collision Resolution & Resizing:
HashSet<T>employs the same chaining and resizing strategies asDictionary<TKey, TValue>. The primary difference is thatHashSet<T>only stores the element itself (which acts as its own key), not a separate value. -
Set Operations:
HashSet<T>excels at mathematical set operations, providing highly optimized implementations for:UnionWith(): All elements from both sets.IntersectWith(): Only elements common to both sets.ExceptWith(): Elements in the current set but not in the other.SymmetricExceptWith(): Elements present in either set, but not both.IsSubsetOf(),IsSupersetOf(),Overlaps(): For relationship checks. These operations are often implemented in O(N) or O(N+M) time complexity, where N and M are the sizes of the sets, making them far more efficient than implementing such logic with lists or arrays.
void DemonstrateHashSet() { HashSet<string> uniqueNames = new HashSet<string>(); uniqueNames.Add("Alice"); // Adds Alice uniqueNames.Add("Bob"); // Adds Bob uniqueNames.Add("Alice"); // Returns false, Alice is already present Console.WriteLine($"Contains 'Alice': {uniqueNames.Contains("Alice")}"); // Output: True Console.WriteLine($"Count of unique names: {uniqueNames.Count}"); // Output: 2 HashSet<string> teamA = new HashSet<string> { "Alice", "Charlie", "David" }; HashSet<string> teamB = new HashSet<string> { "Bob", "Charlie", "Eve" }; // Union teamA.UnionWith(teamB); // teamA now has { "Alice", "Charlie", "David", "Bob", "Eve" } Console.WriteLine($"Union: {string.Join(", ", teamA)}"); // Intersection (requires new HashSet if you want to preserve original teamA) HashSet<string> commonMembers = new HashSet<string>(teamA); // Copy teamA commonMembers.IntersectWith(teamB); Console.WriteLine($"Common members: {string.Join(", ", commonMembers)}"); // Output: Charlie }
11.4.4. IEqualityComparer<T>: Customizing Hashing and Equality
Sometimes, the default GetHashCode() and Equals() implementations of a type are not suitable for dictionary keys or set elements.
- For reference types,
object.GetHashCode()andobject.Equals()default to reference identity. If you want value equality for keys (e.g., twoPersonobjects are equal if theirIds are the same, even if they are different instances), you must override these methods or provide a custom comparer. - For types you don’t control (e.g., third-party classes) or when you need multiple different equality definitions for the same type (e.g., a
Persondictionary byIdand another byEmail), you can implement and provide anIEqualityComparer<T>.
An IEqualityComparer<T> defines two methods:
int GetHashCode(T obj): Returns a hash code for the specified object.bool Equals(T x, T y): Determines whether the specified objects are equal.
You can then pass an instance of your custom comparer to the constructor of Dictionary<TKey, TValue> or HashSet<T>.
record class Person(int Id, string Name);
// Custom comparer for Person based on Id
class PersonIdComparer : IEqualityComparer<Person>
{
public bool Equals(Person? x, Person? y)
{
if (ReferenceEquals(x, y)) return true;
if (ReferenceEquals(x, null) || ReferenceEquals(y, null)) return false;
return x.Id == y.Id;
}
public int GetHashCode(Person obj)
{
return obj.Id.GetHashCode(); // Hash based on Id
}
}
void DemonstrateCustomComparer()
{
var person1 = new Person(1, "Alice");
var person2 = new Person(2, "Bob");
var person3 = new Person(1, "Alicia"); // Different name, same ID as person1
// Dictionary using default equality (reference equality for Person class)
// Will treat person1 and person3 as different keys
Dictionary<Person, string> defaultDict = new Dictionary<Person, string>();
defaultDict.Add(person1, "Manager");
defaultDict.Add(person2, "Associate");
// defaultDict.Add(person3, "Lead"); // This would throw if Person didn't override Equals/GetHashCode by default
// Dictionary using custom comparer (Id-based equality)
// Will treat person1 and person3 as the SAME key
Dictionary<Person, string> idBasedDict = new Dictionary<Person, string>(new PersonIdComparer());
idBasedDict.Add(person1, "Manager");
idBasedDict.Add(person2, "Associate");
idBasedDict[person3] = "Lead"; // This will UPDATE the value for Id 1, not add a new entry
// As person3's Id is 1, it matches person1
Console.WriteLine($"Value for ID 1: {idBasedDict[person1]}"); // Output: Lead
}
- Cross-Reference: For a discussion of thread-safe hash tables, refer to
ConcurrentDictionaryin Chapter 20 (Concurrency).
In summary, Dictionary<TKey, TValue> and HashSet<T> are indispensable for efficient lookups and uniqueness guarantees, respectively. Their O(1) average performance hinges on effective hashing and collision resolution. Understanding these internals, along with the correct use of GetHashCode(), Equals(), and IEqualityComparer<T>, is fundamental to building high-performance .NET applications.
11.5. Tuples and ValueTuple: Structure, Memory, and Modern Usage
Tuples provide a convenient way to group a small number of related data elements into a single object without defining a custom class or struct. C# offers two primary tuple mechanisms: the older System.Tuple class and the modern System.ValueTuple struct, with language-level support.
11.5.1. System.Tuple (Reference Type)
- Introduced: .NET Framework 4.0
- Nature: It is a reference type (a class). This means
Tupleinstances are allocated on the managed heap, and working with them might incur memory allocation and garbage collection overhead. - Properties: Its properties are named
Item1,Item2, etc., which are not semantically meaningful and reduce readability. - Mutability:
System.Tupleinstances are immutable. Their values cannot be changed after creation. -
Usage:
// Creating a Tuple System.Tuple<string, int> personTuple = new System.Tuple<string, int>("Alice", 30); Console.WriteLine($"Name: {personTuple.Item1}, Age: {personTuple.Item2}"); // Returning multiple values from a method (less common now) System.Tuple<int, int> GetCoordinatesTuple() { return new System.Tuple<int, int>(10, 20); } - Limitations:
ItemNproperty names lead to less readable code.- Being a class, it incurs heap allocations and potential GC pressure, especially when used frequently or in performance-sensitive contexts.
- Limited to 8 elements (
Tuple<T1, T2, ..., T7, TRest>).
11.5.2. System.ValueTuple (Value Type) and C# Language Support
- Introduced: C# 7.0 and .NET Framework 4.7 / .NET Core 2.0 (via the
System.ValueTupleNuGet package for older frameworks). - Nature: It is a value type (a struct). This means
ValueTupleinstances are allocated on the stack (or inline within another object on the heap if part of a class), avoiding heap allocations and reducing GC pressure. - Named Fields: The C# compiler provides language-level support for named fields, making
ValueTuplefar more readable and semantically clear thanSystem.Tuple. The names are only visible at compile time (they are compiler-generated[TupleElementNames]attributes in the metadata) and do not change the underlying structure. - Mutability:
ValueTupleinstances are mutable by default if their fields are not read-only. However, for best practice and consistency withrecord structprinciples,ValueTupleis often treated as immutable. - Deconstruction:
ValueTuples can be easily deconstructed back into individual variables. -
Usage:
// Creating a ValueTuple with named fields (syntactic sugar for ValueTuple<...>) (string Name, int Age) person = ("Bob", 25); Console.WriteLine($"Name: {person.Name}, Age: {person.Age}"); // Deconstructing a ValueTuple (string name, int age) = person; Console.WriteLine($"Deconstructed: {name}, {age}"); // Using ValueTuple for multiple return values (double Sum, double Average) CalculateStats(IEnumerable<double> data) { double sum = 0; int count = 0; foreach (var item in data) { sum += item; count++; } return (sum, count > 0 ? sum / count : 0); } (double total, double avg) = CalculateStats(new[] { 10.0, 20.0, 30.0 }); Console.WriteLine($"Total: {total}, Average: {avg}"); // ValueTuple mutability (can be considered a pitfall if not intended) (int X, int Y) point = (1, 2); point.X = 5; // Modifies the X field directly (since ValueTuple is a struct) Console.WriteLine($"Modified point: {point.X}, {point.Y}"); // Output: 5, 2 - Memory and Performance:
- Being a value type,
ValueTupleis typically allocated on the stack for local variables and method parameters, or inline if it’s a field of another struct or class. This avoids heap allocations and associated GC overhead. - This makes
ValueTupleideal for lightweight data aggregation, especially when passing multiple return values from methods or for temporary groupings of data. - Boxing: Like any value type, if a
ValueTupleis cast toobjector to one of the non-genericSystem.Tupletypes (which it implicitly converts to for backward compatibility withTuple.Create), it will be boxed onto the heap. Avoid this in performance-sensitive code.
- Being a value type,
11.5.3. Comparison and Best Practices
| Feature | System.Tuple (Class) |
System.ValueTuple (Struct) |
|---|---|---|
| Type | Reference type (heap allocated) | Value type (stack/inline allocated) |
| Memory | Higher GC pressure (heap, allocations) | Lower GC pressure (stack, no allocations for locals) |
| Mutability | Immutable | Mutable by default (fields are mutable if not readonly struct) |
| Property Names | Item1, Item2, etc. (fixed) |
Named fields (Name, Age) via C# language support |
| Syntax | new Tuple<T1, T2>(v1, v2) |
(T1 Name, T2 Age) = (v1, v2) or (v1, v2) |
| Deconstruction | No direct language support (can do manually) | Direct language support ((var name, var age) = person;) |
| Best Use Cases | Interop with older code, small, infrequent uses | Primary choice for new code, especially multiple return values, temporary data grouping. Highly performant. |
| Generics Limit | Up to 8 elements (TRest for more) |
Effectively unlimited (nesting ValueTuples internally) |
Best Practices:
- Prefer
ValueTuple: For almost all new code in modern C# (7.0+), preferValueTupledue to its value-type semantics, named fields, and deconstruction support, leading to better performance and readability. - Avoid
System.Tuple: Only useSystem.Tuplewhen interoperating with older codebases that specifically expect it, or when you explicitly need heap allocation for the tuple itself. - Readability: Use meaningful names for
ValueTuplefields to make your code self-documenting. - Conciseness: Tuples are excellent for lightweight data aggregation where defining a full-blown class or struct would be overkill. However, for complex data structures with behavior or invariants, a dedicated class/struct is still appropriate.
- Boxing Awareness: Be mindful that converting a
ValueTupletoobjectwill box it, negating its memory benefits. This commonly happens when storingValueTuples in non-generic collections or using them whereobjectis expected.
11.6. I/O Streams and Readers/Writers
The .NET Framework provides a rich and flexible model for input/output (I/O) operations, built around the abstract Stream class. This model allows you to interact with various data sources and destinations (files, memory, network sockets) in a consistent manner, regardless of the underlying medium. For character-based I/O, StreamReader and StreamWriter build upon the stream abstraction to handle encodings and buffering.
11.6.1. Stream Base Class and Derivatives
The System.IO.Stream class is the abstract base class that defines the fundamental contract for reading and writing sequences of bytes. It abstracts the specifics of the underlying storage medium.
-
Core Concepts:
- Byte-oriented: Streams deal exclusively with bytes, not characters. Encoding/decoding is handled by higher-level abstractions (
StreamReader/StreamWriter). - Position: Many streams have a current position within the stream, which can be read (
Positionproperty) and set (Seek()method). - Read/Write Capabilities: Streams can be read-only, write-only, or read-write, indicated by
CanRead,CanWrite, andCanSeekproperties. IDisposable: Streams hold valuable resources (file handles, network connections) and must be properly disposed of. Always useusingstatements ortry-finallyblocks to ensureDispose()is called.
- Byte-oriented: Streams deal exclusively with bytes, not characters. Encoding/decoding is handled by higher-level abstractions (
-
Key Abstract Methods (implemented by derived classes):
Read(byte[] buffer, int offset, int count): Reads a sequence of bytes from the current stream and advances the position. Returns the number of bytes read (0 if end of stream).Write(byte[] buffer, int offset, int count): Writes a sequence of bytes to the current stream and advances the position.Seek(long offset, SeekOrigin origin): Sets the position within the current stream.Flush(): Clears all buffers for this stream and causes any buffered data to be written to the underlying device.Length: Gets the length of the stream in bytes.
-
Common Stream Derivatives:
-
FileStream: For reading from and writing to files on a file system. It’s the primary way to perform binary I/O with files.void DemonstrateFileStream() { string filePath = "example.bin"; byte[] data = { 1, 2, 3, 4, 5 }; // Writing to a file using (FileStream fsWrite = new FileStream(filePath, FileMode.Create, FileAccess.Write)) { fsWrite.Write(data, 0, data.Length); Console.WriteLine($"Wrote {data.Length} bytes to {filePath}"); } // Reading from a file using (FileStream fsRead = new FileStream(filePath, FileMode.Open, FileAccess.Read)) { byte[] readData = new byte[data.Length]; int bytesRead = fsRead.Read(readData, 0, readData.Length); Console.WriteLine($"Read {bytesRead} bytes: {string.Join(", ", readData)}"); } } -
MemoryStream: For reading from and writing to a stream that resides in memory (backed by a byte array). Useful for in-memory data manipulation without file system interaction.void DemonstrateMemoryStream() { byte[] originalBytes = { 0x48, 0x65, 0x6C, 0x6C, 0x6F }; // "Hello" in ASCII using (MemoryStream ms = new MemoryStream()) { ms.Write(originalBytes, 0, originalBytes.Length); ms.Seek(0, SeekOrigin.Begin); // Reset position to read from beginning byte[] readBytes = new byte[originalBytes.Length]; ms.Read(readBytes, 0, readBytes.Length); Console.WriteLine($"Read from MemoryStream: {Encoding.ASCII.GetString(readBytes)}"); } } NetworkStream: Provides data streams for network socket connections.BufferedStream: A decorator stream that wraps another stream (FileStream,NetworkStream) to provide internal buffering, improving performance for small read/write operations by reducing calls to the underlying stream.GZipStream/DeflateStream: Decorator streams for compressing and decompressing data.
-
-
Asynchronous I/O (
ReadAsync,WriteAsync): All stream derivatives also offer asynchronous methods (e.g.,ReadAsync,WriteAsync,CopyToAsync). These are crucial for non-blocking I/O operations, especially in UI applications (to prevent freezing) or server-side applications (to maximize throughput by not blocking threads while waiting for I/O to complete).
11.6.2. StreamReader and StreamWriter
While Stream objects handle raw bytes, text-based I/O requires converting characters to bytes and vice-versa, according to a specific character encoding. StreamReader and StreamWriter provide this functionality, along with internal buffering for efficiency.
- Purpose: To simplify reading and writing of characters (text) to and from streams, handling character encoding and buffering transparently.
- Encoding: They use an
Encodingobject to perform the character-to-byte conversions.StreamReaderandStreamWriterhave constructors that allow you to specify the encoding (e.g.,Encoding.UTF8,Encoding.ASCII). If no encoding is specified,UTF8Encodingis used by default (with aStreamReaderdetecting byte order marks for common encodings). Always explicitly specify the encoding to avoid subtle data corruption issues, especially when dealing with non-ASCII characters or cross-platform data. -
Buffering: Both classes maintain internal buffers. This means small
Read()/Write()operations on theStreamReader/StreamWriterdo not immediately result in calls to the underlyingStream. Instead, data is accumulated in the buffer and written/read in larger chunks, significantly improving performance by reducing syscalls.StreamWriter.Flush(): Forces any buffered data to be written to the underlying stream.StreamReader.Peek(): Allows you to look at the next character without consuming it.
-
Key Methods:
StreamReader:Read(),ReadLine(),ReadToEnd(),Peek().StreamWriter:Write(),WriteLine(),Flush().
void DemonstrateStreamReaderAndWriter() { string filePath = "example.txt"; string text = "Hello, C# I/O!\nThis is a test with some special characters: Straße, αβγ."; // Writing text to a file with explicit UTF-8 encoding using (StreamWriter writer = new StreamWriter(filePath, false, Encoding.UTF8)) { writer.WriteLine(text); writer.WriteLine("Another line."); writer.Flush(); // Ensure data is written immediately } Console.WriteLine($"Wrote text to {filePath} with UTF-8 encoding."); // Reading text from a file with explicit UTF-8 encoding using (StreamReader reader = new StreamReader(filePath, Encoding.UTF8)) { string content = reader.ReadToEnd(); Console.WriteLine($"\nRead from {filePath}:\n{content}"); } } - Resource Management: Like streams,
StreamReaderandStreamWriteralso implementIDisposableand must be disposed of. Usingusingstatements is the preferred pattern. Disposing aStreamWriterwill automatically flush its buffer and dispose of the underlying stream (unless the constructor specified not to close the stream).
11.6.3. StringReader and StringWriter
These are specialized classes that inherit from TextReader and TextWriter respectively. They provide in-memory character-based I/O operations, useful when you need to treat a string as a stream of characters or build a string incrementally, without involving file system or network operations.
StringReader: Reads characters from astring. Useful for parsing large strings as if they were files, without creating actual temporary files.void DemonstrateStringReader() { string data = "Line 1\nLine 2\nLine 3"; using (StringReader reader = new StringReader(data)) { string? line; while ((line = reader.ReadLine()) != null) { Console.WriteLine($"StringReader: {line}"); } } }StringWriter: Writes characters to aStringBuilder. It provides aTextWriterinterface over a mutableStringBuilder, allowing you to use methods designed forTextWriter(likeWriteLine,Write,Format) to build a string efficiently. It’s often used with classes that require aTextWriteras an output sink.void DemonstrateStringWriter() { StringBuilder sb = new StringBuilder(); using (StringWriter writer = new StringWriter(sb)) // Writes to the StringBuilder { writer.WriteLine("Hello from StringWriter!"); writer.Write("The answer is "); writer.Write(42); } string result = sb.ToString(); // Get the final string from StringBuilder Console.WriteLine($"StringWriter result: {result}"); }- Use Cases:
- Parsing:
StringReadercan parse configuration strings, log entries, or serialized data directly from memory. - Building Dynamic Strings:
StringWritercan be used withXmlWriteror other text formatters that expect aTextWriterto build XML, JSON, or other text formats in memory efficiently, leveragingStringBuilder’s performance.
- Parsing:
In essence, the .NET I/O model is layered: Stream provides the low-level byte-oriented foundation, StreamReader/StreamWriter add character encoding and buffering for text, and StringReader/StringWriter specialize this for in-memory string manipulation. Proper resource management (using statements) and explicit encoding are paramount across all these layers.
11.7. Date, Time, and Unique Identifiers: DateTime, DateTimeOffset, DateOnly, TimeOnly, and Guid
Handling temporal data and unique identifiers correctly is critical in almost every application. C# provides several robust types for this purpose, each with its specific use cases and underlying considerations.
11.7.1. Temporal Data: DateTime, DateTimeOffset, DateOnly, and TimeOnly
Dealing with dates and times can be surprisingly complex, especially when considering time zones, daylight saving time, and different cultural calendars. .NET offers a comprehensive set of types to manage these complexities.
-
DateTime(Legacy, but Still Common): Represents a date and time. While widely used,DateTimehas some inherent ambiguities due to itsKindproperty.-
DateTimeKind:Unspecified: TheDateTimeis not specified as either UTC or local time. This is the default when parsing strings or creatingDateTimefrom parts without explicitly setting theKind. Avoid this where possible as it leads to ambiguity.Utc: TheDateTimerepresents Coordinated Universal Time (UTC).Local: TheDateTimerepresents local time (adjusted for the current system’s time zone and daylight saving time).
-
Ambiguities and Pitfalls: The primary pitfall of
DateTimeis mixingUnspecified,Local, andUtckinds without careful conversion.- Operations like
AddDays(),Subtract(), or comparingDateTimevalues generally ignore theKind. - Converting between local and UTC (
ToLocalTime(),ToUniversalTime()) can produce incorrect results if the originalKindwasUnspecifiedor if theDateTimefalls into a daylight saving time transition “gap” or “overlap.” - Serialization: Serializing
DateTimevalues asLocalorUnspecifiedcan lead to issues when deserialized on a system in a different time zone or with different DST rules. Always serialize as UTC.
- Operations like
-
Best Practices for
DateTime:- Store and Transmit UTC: For all internal operations, data storage, and network communication, always convert
DateTimevalues toDateTimeKind.UtcusingDateTime.UtcNoworsomeDateTime.ToUniversalTime(). This avoids time zone and DST ambiguities. - Convert to Local for Display: Only convert to
DateTimeKind.LocalusingToLocalTime()just before displaying to the end-user. - Parsing: When parsing date/time strings, if the source indicates UTC, use
DateTimeStyles.AdjustToUniversal. Otherwise, be extremely careful withUnspecifieddates.
- Store and Transmit UTC: For all internal operations, data storage, and network communication, always convert
void DemonstrateDateTime() { DateTime utcNow = DateTime.UtcNow; // Get current UTC time DateTime localNow = DateTime.Now; // Get current local time Console.WriteLine($"UTC Now: {utcNow} (Kind: {utcNow.Kind})"); Console.WriteLine($"Local Now: {localNow} (Kind: {localNow.Kind})"); // Convert between kinds DateTime localFromUtc = utcNow.ToLocalTime(); Console.WriteLine($"UTC to Local: {localFromUtc} (Kind: {localFromUtc.Kind})"); DateTime utcFromLocal = localNow.ToUniversalTime(); Console.WriteLine($"Local to UTC: {utcFromLocal} (Kind: {utcFromLocal.Kind})"); // Pitfall: Adding to an Unspecified date DateTime unspecifiedDate = new DateTime(2025, 7, 1, 10, 0, 0); // Kind is Unspecified DateTime convertedToLocal = unspecifiedDate.ToLocalTime(); // Converts based on machine's TZ, but original was Unspecified Console.WriteLine($"Unspecified date to Local: {unspecifiedDate} -> {convertedToLocal}"); } -
-
DateTimeOffset(Recommended for Time Zone Awareness): Represents a date and time value, together with its offset from UTC. This type is superior toDateTimefor most time-zone-aware applications because it explicitly captures the time zone context.- Structure: A
DateTimeOffsetvalue stores aDateTimevalue (internally, itsDateTimecomponent is alwaysDateTimeKind.UnspecifiedorUtc) and aTimeSpanrepresenting its difference from UTC. - Ambiguity Resolution:
DateTimeOffsetvalues are unambiguous. A specific point in time has only oneDateTimeOffsetvalue, regardless of the time zone.2025-07-05 10:00:00 -04:00clearly defines a specific instant in time. -
Mathematical Operations: Arithmetic operations (
Add,Subtract) correctly maintain the offset relative to UTC. Comparisons are based on the actual instant in time. - Best Practices for
DateTimeOffset:- Prefer
DateTimeOffsetoverDateTimewhen your application deals with time zones, scheduling, or needs to store points in time unambiguously (e.g., event timestamps, logging). - Store and Transmit UTC: Still a good practice to store
DateTimeOffsetvalues in a normalized form (e.g., adjusted to UTC offset usingToUniversalTime()) in databases, thoughDateTimeOffsetitself always contains enough information to correctly reconstruct the original. - Conversion: Easily convert to/from
DateTimeif necessary, but understand the implications (loss of offset).
- Prefer
void DemonstrateDateTimeOffset() { DateTimeOffset nowOffset = DateTimeOffset.Now; // Current local time with offset DateTimeOffset utcNowOffset = DateTimeOffset.UtcNow; // Current UTC time with 0 offset Console.WriteLine($"Local Time with Offset: {nowOffset}"); Console.WriteLine($"UTC Time with Offset: {utcNowOffset}"); // Create an offset for a specific time zone (e.g., New York, EST/EDT) // Note: This requires System.TimeZoneInfo which is more complex TimeSpan newYorkOffset = TimeZoneInfo.FindSystemTimeZoneById("America/New_York").GetUtcOffset(DateTimeOffset.Now); DateTimeOffset specificTimeInNY = new DateTimeOffset(2025, 1, 15, 10, 0, 0, newYorkOffset); Console.WriteLine($"Specific time in NY: {specificTimeInNY}"); // Convert to UTC DateTimeOffset specificTimeInNY_Utc = specificTimeInNY.ToUniversalTime(); Console.WriteLine($"Specific time in NY (UTC equivalent): {specificTimeInNY_Utc}"); // Comparison: They represent the same instant in time Console.WriteLine($"Are 'nowOffset' and 'utcNowOffset.ToLocalTime() (as DateTimeOffset)' the same instant? {nowOffset == utcNowOffset.ToLocalTime()}"); } - Structure: A
-
DateOnlyandTimeOnly(C# 10 / .NET 6+): These new types address common scenarios where you only care about the date part or only the time part, without any time zone orDateTimeKindcomplexities. They are structs, making them efficient.DateOnly: Represents a date (year, month, day) without a time component. Useful for birthdays, anniversaries, or business days.void DemonstrateDateOnly() { DateOnly today = DateOnly.FromDateTime(DateTime.Now); DateOnly newYear = new DateOnly(2026, 1, 1); Console.WriteLine($"Today: {today}, New Year: {newYear}"); Console.WriteLine($"Is today before New Year? {today < newYear}"); // Output: True Console.WriteLine($"Day of week: {today.DayOfWeek}"); }TimeOnly: Represents a time of day without a date component. Useful for recurring schedules (e.g., “open at 9:00 AM”, “close at 5:00 PM”).void DemonstrateTimeOnly() { TimeOnly nowTime = TimeOnly.FromDateTime(DateTime.Now); TimeOnly openingTime = new TimeOnly(9, 0, 0); // 9:00 AM TimeOnly closingTime = new TimeOnly(17, 0, 0); // 5:00 PM Console.WriteLine($"Current Time: {nowTime}"); Console.WriteLine($"Is store open? {nowTime >= openingTime && nowTime <= closingTime}"); }- Interoperability:
DateOnlyandTimeOnlycan be easily converted to/fromDateTime(though time or date information might be lost respectively).
11.7.2. Unique Identifiers: Guid
A System.Guid (Globally Unique Identifier), also known as a UUID (Universally Unique Identifier), is a 128-bit number used to create values that are practically guaranteed to be unique across all computers and networks.
- Structure: A
Guidis represented as a 128-bit integer, typically displayed as a 32-character hexadecimal string divided into five groups separated by hyphens (e.g.,xxxxxxxx-xxxx-4xxx-yxxx-xxxxxxxxxxxx). The4xxxindicates a version 4 UUID (randomly generated). - Guaranteed Uniqueness (Probabilistic):
Guids are not guaranteed to be unique in a strict mathematical sense, but the probability of twoGuids being identical is astronomically low. For practical purposes, they are considered unique. - Generation:
Guid.NewGuid(): The most common way to generate a newGuid. It uses a cryptographically strong random number generator to produce version 4 UUIDs. This is the simplest and safest way to get unique IDs.
- Use Cases:
- Primary keys in databases (especially distributed systems).
- Unique identifiers for objects, sessions, or messages in distributed applications.
- File names or temporary resource names to avoid collisions.
- Comparison:
Guids can be compared using the==operator orEquals()method, which perform value equality. -
Performance and Storage:
Guids are 16 bytes. While larger than a typicalintorlong, they are very efficient for database lookups when indexed properly.- When used as clustered primary keys in SQL Server, randomly generated
Guids can lead to page fragmentation (due to insertions in random locations), impacting write performance. For such scenarios, sequentialGuids (e.g., usingnewid()in SQL Server, or custom algorithms likeCOMBGuids) are sometimes preferred, though this compromises strict randomness. - String Conversion: Converting
Guidtostringand back can be slower than integer conversions and consumes more memory (36 characters forstringrepresentation).
void DemonstrateGuid() { Guid id1 = Guid.NewGuid(); Guid id2 = Guid.NewGuid(); Guid id3 = id1; // id3 refers to the same Guid value as id1 Console.WriteLine($"ID 1: {id1}"); Console.WriteLine($"ID 2: {id2}"); Console.WriteLine($"ID 1 == ID 2: {id1 == id2}"); // Output: False (very likely) Console.WriteLine($"ID 1 == ID 3: {id1 == id3}"); // Output: True // Parse from string string guidString = "a1b2c3d4-e5f6-7890-abcd-ef1234567890"; Guid parsedGuid = Guid.Parse(guidString); Console.WriteLine($"Parsed Guid: {parsedGuid}"); }
In summary, choosing the correct temporal type (DateTime, DateTimeOffset, DateOnly, TimeOnly) is paramount for avoiding time zone ambiguities and ensuring correct temporal logic. Guid provides a robust, virtually guaranteed unique identifier system for distributed systems and general object identification.
11.8. Lazy<T>: Deferred Initialization and Resource Management
The System.Lazy<T> class provides a standardized and thread-safe way to perform deferred initialization (also known as lazy initialization). This means that an object’s instance is created only when it’s first needed, rather than at the time the Lazy<T> wrapper itself is constructed.
-
Purpose:
- Performance Optimization: Avoid creating expensive objects or computing values until they are actually required. This can significantly improve application startup time or reduce resource consumption if an object is only used in certain execution paths.
- Resource Management: Deferring the creation of resource-intensive objects (e.g., database connections, large arrays, heavy services) until absolutely necessary.
- Thread Safety: Provides built-in mechanisms to ensure that the initialization logic runs exactly once, even if accessed concurrently by multiple threads.
-
How it Works: You provide
Lazy<T>with a delegate (aFunc<T>) that encapsulates the logic for creating the instance ofT. The actual instance ofTis not created until theLazy<T>.Valueproperty is accessed for the first time. -
Initialization Modes (Thread Safety): The
Lazy<T>constructor allows you to specify the thread-safety mode usingLazyThreadSafetyModeenum:LazyThreadSafetyMode.PublicationOnly(Default): The factory method can be called multiple times by different threads ifValueis accessed concurrently. However, only the value from the first successful execution will be cached and returned. Other concurrent executions of the factory method are discarded. This is the fastest option if you don’t care about the factory being invoked multiple times.LazyThreadSafetyMode.ExecutionAndPublication: (Most common for thread-safe lazy init). Ensures that only one thread can execute the factory method at a time. The first thread to accessValuewill cause the factory method to be executed. Other threads that concurrently accessValuewill block until the initialization is complete and then receive the initialized value. This provides full thread safety for both factory execution and publication.LazyThreadSafetyMode.None: No thread safety. The factory method might be called multiple times, and multiple values might be created, or an exception could be thrown ifValueis accessed by multiple threads concurrently. Use only when you are certain thatValuewill only be accessed by a single thread, or if you provide your own external synchronization. This is the fastest mode as it avoids all locking overhead.
class ExpensiveResource { public string Name { get; } public ExpensiveResource(string name) { Name = name; Console.WriteLine($"ExpensiveResource '{Name}' created at {DateTime.Now:HH:mm:ss.fff}"); // Simulate heavy work Thread.Sleep(100); } } void DemonstrateLazy() { Console.WriteLine("Lazy initialization demo:"); // Default mode (ExecutionAndPublication if no mode specified in constructor) Lazy<ExpensiveResource> lazyResource = new Lazy<ExpensiveResource>( () => new ExpensiveResource("DefaultLazy"), LazyThreadSafetyMode.ExecutionAndPublication); // Explicitly setting for clarity Console.WriteLine("Lazy object created, but resource not yet initialized."); // Resource is created only when Value is accessed for the first time Console.WriteLine($"Accessing resource 1st time: {lazyResource.Value.Name}"); Console.WriteLine($"Accessing resource 2nd time: {lazyResource.Value.Name}"); // No new creation // Demonstrate PublicationOnly (factory may run multiple times) Console.WriteLine("\nLazyThreadSafetyMode.PublicationOnly demo:"); Lazy<ExpensiveResource> publicationOnlyLazy = new Lazy<ExpensiveResource>( () => new ExpensiveResource("PublicationOnlyLazy"), LazyThreadSafetyMode.PublicationOnly); List<Task> tasks = new List<Task>(); for (int i = 0; i < 3; i++) { tasks.Add(Task.Run(() => Console.WriteLine($"Task accessing PublicationOnly: {publicationOnlyLazy.Value.Name}"))); } Task.WhenAll(tasks).Wait(); // Wait for all tasks to complete // You might see "ExpensiveResource 'PublicationOnlyLazy' created" multiple times, // but only the first completed value is returned by publicationOnlyLazy.Value. } -
Key Properties and Methods:
Value: (TypeT) Gets the lazily initialized value. Accessing this property triggers the initialization if it hasn’t occurred yet.IsValueCreated: (Typebool) Gets a value that indicates whether a value has been created for thisLazy<T>instance.
-
Use Cases:
- Caching: When an object or data structure is expensive to compute or load, but its value might not always be needed.
- Configuration Objects: Deferring the loading of complex configuration until the configuration is actually accessed.
-
Singleton Pattern:
Lazy<T>provides a simple and thread-safe way to implement singletons, ensuring the instance is created only once on demand.public class SingletonService { private static readonly Lazy<SingletonService> _instance = new Lazy<SingletonService>(() => new SingletonService(), LazyThreadSafetyMode.ExecutionAndPublication); private SingletonService() { /* Private constructor */ } public static SingletonService Instance => _instance.Value; public void DoSomething() => Console.WriteLine("Singleton service doing something."); } void DemonstrateSingletonLazy() { SingletonService.Instance.DoSomething(); SingletonService.Instance.DoSomething(); // Same instance used } - Dependency Injection: Deferring the creation of less frequently used dependencies.
-
Limitations:
- The
Lazy<T>instance itself is an object and incurs a small allocation on the heap. For very simple values or extremely high-frequency, trivial initializations, the overhead ofLazy<T>might exceed the benefits. - It’s designed for “one-time” lazy initialization. If you need to re-initialize an object (e.g., after a dispose), you’d typically need a new
Lazy<T>instance.
- The
Lazy<T> is a highly valuable tool for optimizing resource consumption and startup performance by embracing demand-driven object instantiation, all while providing robust thread-safe guarantees.
11.9. Random: Pseudorandomness, Seeding, and Thread Safety
The System.Random class is used to generate pseudorandom numbers. Understanding its behavior, particularly concerning seeding and thread safety, is crucial for obtaining truly varied sequences and avoiding common pitfalls in concurrent applications.
-
Pseudorandom Number Generation:
System.Randomgenerates numbers that appear random but are, in fact, entirely deterministic. They are generated by a complex algorithm based on an initial starting value called the seed. If you use the same seed, you will always get the same sequence of “random” numbers. -
Seeding:
- Default Constructor (
new Random()): If you create aRandominstance with its default constructor (new Random()), it uses a time-dependent seed. Specifically, it uses the system clock to determine the seed. This typically ensures that consecutiveRandominstances created shortly after each other will produce different sequences of numbers, but this is not always guaranteed if they are created very close in time or in rapid succession. - Parameterized Constructor (
new Random(int seed)): You can explicitly provide an integer seed. This is useful for:- Reproducibility: When you need to reproduce a sequence of random numbers for testing, debugging, or simulations.
- Distributed Systems: Ensuring consistent “random” behavior across different machines if they share the same seed.
void DemonstrateRandomSeeding() { Console.WriteLine("--- Default Seeding ---"); Random rand1 = new Random(); // Seed based on time Random rand2 = new Random(); // Seed based on time (might be same or different if called quickly) Console.WriteLine($"Rand1 first number: {rand1.Next(100)}"); Console.WriteLine($"Rand2 first number: {rand2.Next(100)}"); // Often different, but sometimes identical if called in very rapid succession Console.WriteLine("\n--- Explicit Seeding (Reproducible) ---"); Random rand3 = new Random(123); // Same seed Random rand4 = new Random(123); // Same seed Console.WriteLine($"Rand3 first number: {rand3.Next(100)}"); // Will be same as Rand4 first number Console.WriteLine($"Rand4 first number: {rand4.Next(100)}"); // Will be same as Rand3 first number // Output: Identical sequences if seeds are identical } - Default Constructor (
-
Common Pitfall: Rapid Instantiation in Loops: A very common mistake is to create a new
Randominstance inside a tight loop or a frequently called method:// Pitfall: Inefficient and often generates identical numbers due to time-based seeding void GenerateManyNumbersBadly(int count) { Console.WriteLine("\n--- Bad Random Generation ---"); for (int i = 0; i < count; i++) { Random badRand = new Random(); // New instance with time-based seed on each iteration Console.Write($"{badRand.Next(100)} "); } Console.WriteLine(); }If the loop runs very quickly (within the resolution of the system clock), multiple
Randominstances will be created with the same seed, resulting in identical sequences of “random” numbers (e.g.,42 42 42 42...). -
Best Practice: Single
RandomInstance: The recommended approach is to create a singleRandominstance and reuse it throughout your application or within a specific scope.// Best Practice: Reuse a single Random instance private static readonly Random _globalRandom = new Random(); // Static for application-wide reuse void GenerateManyNumbersWell(int count) { Console.WriteLine("\n--- Good Random Generation ---"); for (int i = 0; i < count; i++) { Console.Write($"{_globalRandom.Next(100)} "); } Console.WriteLine(); } -
Thread Safety (
System.Randomis NOT Thread-Safe):System.Randominstances are not thread-safe. If multiple threads access the sameRandominstance concurrently, it can lead to:- Incorrectly generated sequences (non-random or biased results).
- Race conditions that cause internal state corruption.
-
In extreme cases,
IndexOutOfRangeExceptionor other exceptions. -
Solutions for Thread Safety:
-
Locking: Use a
lockstatement to protect access to a sharedRandominstance. This is simple but can introduce contention in high-concurrency scenarios.private static readonly Random _syncRandom = new Random(); private static readonly object _syncLock = new object(); public int GetRandomNumberThreadSafeLocked() { lock (_syncLock) { return _syncRandom.Next(); } } -
Thread-Local
RandomInstances: A common and often superior approach is to create aRandominstance per thread. UseThreadLocal<Random>or ensure each thread maintains its ownRandomobject. This avoids contention.private static readonly ThreadLocal<Random> _threadLocalRandom = new ThreadLocal<Random>(() => new Random(Guid.NewGuid().GetHashCode())); // Use unique seed per thread public int GetRandomNumberThreadSafeThreadLocal() { return _threadLocalRandom.Value!.Next(); } -
System.Security.Cryptography.RandomNumberGenerator: For cryptographically secure random numbers (e.g., for security-sensitive applications like key generation, token creation), useRandomNumberGenerator. This class provides true randomness and is designed to be thread-safe. It’s slower and consumes more entropy, so it’s not for general-purpose pseudorandom number generation. Reference: Cryptographically secure random numbers
-
-
Random.Shared(New in .NET 6): .NET 6 introducedRandom.Sharedwhich provides a static, thread-safeRandominstance that is suitable for general-purpose use cases where you need a quick pseudorandom number and don’t need reproducible sequences or high-performance concurrent generation from the same generator. It internally handles thread-safe access.void DemonstrateRandomShared() { Console.WriteLine("\n--- Random.Shared (Thread-Safe, convenient) ---"); // No need to instantiate, just use it Console.WriteLine($"Random.Shared number: {Random.Shared.Next(100)}"); List<Task> tasks = new List<Task>(); for (int i = 0; i < 5; i++) { tasks.Add(Task.Run(() => Console.WriteLine($"Task {Task.CurrentId} random: {Random.Shared.Next(100)}"))); } Task.WhenAll(tasks).Wait(); }Random.Sharedis a good default for simple, non-security-critical random number needs in modern .NET applications.
In conclusion, System.Random is for pseudorandom numbers based on a seed. Avoid rapid instantiation in loops. For concurrent scenarios, either use lock for shared instances, create thread-local instances, or leverage Random.Shared (for .NET 6+). For security-critical randomness, always use System.Security.Cryptography.RandomNumberGenerator.
11.10. Regex: Regular Expression Compilation and Performance
The System.Text.RegularExpressions.Regex class provides a powerful, flexible, and highly optimized engine for pattern matching in text using regular expressions. Understanding its compilation modes and performance considerations is crucial for efficient text processing.
-
What are Regular Expressions? Regular expressions (regex) are sequences of characters that define a search pattern. They are used for sophisticated text searching, “find and replace” operations, input validation, and parsing structured text.
-
RegexObject Creation: The most common way to useRegexis to instantiate aRegexobject with a pattern string.using System.Text.RegularExpressions; void DemonstrateBasicRegex() { string text = "The quick brown fox jumps over the lazy dog."; string pattern = @"\b[qQ]\w+\b"; // Matches words starting with 'q' or 'Q' Regex regex = new Regex(pattern); // Compiles the pattern internally MatchCollection matches = regex.Matches(text); Console.WriteLine($"Text: \"{text}\""); Console.WriteLine($"Pattern: \"{pattern}\""); Console.WriteLine("Matches:"); foreach (Match match in matches) { Console.WriteLine($"- {match.Value}"); // Output: - quick } bool hasDigit = Regex.IsMatch("abc123def", @"\d+"); Console.WriteLine($"Contains digit: {hasDigit}"); // Output: True }
11.10.1. Regex Compilation Modes
The Regex class offers different compilation modes that affect its startup time and execution speed. This is controlled by the RegexOptions enum passed to the constructor.
-
Interpreted (Default):
RegexOptions.None(Default): The regex engine interprets the pattern each time it attempts a match.- Characteristics:
- Fast Startup: The
Regexobject is created quickly because no heavy compilation occurs upfront. - Slower Execution: Each match operation requires the engine to re-interpret the pattern, leading to slower execution, especially for complex patterns or many match attempts.
- Best For: Patterns used only once or very infrequently.
- Fast Startup: The
-
Compiled:
RegexOptions.Compiled: The regex engine compiles the pattern into IL (Intermediate Language) bytecode. This bytecode is then JIT-compiled into native machine code.- Characteristics:
- Slower Startup: Initial creation of the
Regexobject is slower because of the compilation step. - Faster Execution: Subsequent match operations are much faster as they execute native code directly, avoiding interpretation overhead.
- Best For: Patterns that are used frequently (e.g., in a loop, a high-throughput server, or a long-running application).
- Slower Startup: Initial creation of the
void DemonstrateRegexCompilation() { string pattern = @"^[a-zA-Z0-9]+$"; // Alphanumeric only string testString = "HelloWorld123"; int iterations = 1_000_000; var sw = new System.Diagnostics.Stopwatch(); // --- Interpreted Mode --- sw.Start(); for (int i = 0; i < iterations; i++) { Regex regexInterpreted = new Regex(pattern, RegexOptions.None); // Re-creates and re-interprets each time _ = regexInterpreted.IsMatch(testString); } sw.Stop(); Console.WriteLine($"Interpreted (repeated creation): {sw.ElapsedMilliseconds} ms"); sw.Reset(); // --- Interpreted Mode (reused instance) --- // This is typically how you'd use interpreted if you don't use Compiled. Regex regexInterpretedReused = new Regex(pattern, RegexOptions.None); sw.Start(); for (int i = 0; i < iterations; i++) { _ = regexInterpretedReused.IsMatch(testString); // Reuses the interpreter } sw.Stop(); Console.WriteLine($"Interpreted (reused instance): {sw.ElapsedMilliseconds} ms"); sw.Reset(); // --- Compiled Mode (reused instance) --- Regex regexCompiled = new Regex(pattern, RegexOptions.Compiled); // One-time compilation sw.Start(); for (int i = 0; i < iterations; i++) { _ = regexCompiled.IsMatch(testString); // Executes compiled code } sw.Stop(); Console.WriteLine($"Compiled (reused instance): {sw.ElapsedMilliseconds} ms"); // Expected results: // Interpreted (repeated creation) will be slowest. // Compiled (reused) will be fastest. // Interpreted (reused) will be in between. The difference between reusable interpreted and compiled // depends on pattern complexity and input string length. For very simple patterns, interpreted might be fine. } -
Source Generation (
RegexGeneratorAttribute) (New in .NET 7 / C# 11): For even higher performance and compile-time validation, .NET 7 introduced theRegexGeneratorsource generator. This attribute (applied to apartialmethod) causes the C# compiler to generate the underlyingRegeximplementation directly into your assembly at compile time.RegexOptions.Compiledtaken to the next level: Instead of generating IL at runtime, the pattern is analyzed at compile time, and highly optimized C# code is generated, eliminating all runtime interpretation overhead and potentially creating more efficient machine code than the JIT-compiledRegexOptions.Compiled.- Compile-time Validation: If your regex pattern is invalid, you’ll get a compile-time error, catching bugs earlier.
- Zero Startup Cost (for Regex creation): The
Regexobject is essentially “baked in” at compile time. - Best For: Extremely performance-critical scenarios where regex is a hot path, and the pattern is known at compile time.
using System.Text.RegularExpressions; using System.Runtime.CompilerServices; // For [GeneratedRegex] attribute public partial class MyRegexContainer { // The source generator will generate an optimized method implementation for this partial method [GeneratedRegex(@"^\d{3}-\d{3}-\d{4}$", RegexOptions.Compiled)] public static partial bool IsValidPhoneNumber(string input); } void DemonstrateGeneratedRegex() { Console.WriteLine("\n--- Generated Regex (C# 11 / .NET 7+) ---"); Console.WriteLine($"Is '123-456-7890' a valid phone number? {MyRegexContainer.IsValidPhoneNumber("123-456-7890")}"); // True Console.WriteLine($"Is 'abc-def-ghij' a valid phone number? {MyRegexContainer.IsValidPhoneNumber("abc-def-ghij")}"); // False // Performance benefits are similar to Compiled, but with even less startup overhead and better compile-time safety. }Reference: Regex source generators
11.10.2. Performance Optimization Strategies for Regex
- Reuse
RegexInstances: Always create aRegexobject once and reuse it. Never createnew Regex(pattern)inside a loop or frequently called method. If you use static methods likeRegex.IsMatch(), they internally cache recent patterns, but for repeated use of the same complex pattern, explicitRegexinstance reuse is best. - Choose
RegexOptions.Compiled(orGeneratedRegex): For patterns used more than a few times,RegexOptions.Compiledis generally preferred for its execution speed. For ultimate performance and compile-time safety, useGeneratedRegexin .NET 7+. - Optimize Patterns Themselves:
- Specificity: Make your patterns as specific as possible to reduce backtracking (e.g., use
\dinstead of.if you expect digits). - Anchors (
^,$): Use anchors to fix the match to the start/end of the string/line if appropriate. This helps the engine fail fast. - Possessive Quantifiers (
*+,++,?+): For some patterns, possessive quantifiers (e.g.,a*+binstead ofa*b) can prevent catastrophic backtracking by not giving up matches once they’ve been made, but they can also prevent a match if used incorrectly. - Atomic Groups (
(?>...)): Similar to possessive quantifiers, atomic groups prevent backtracking into the group. - Non-Capturing Groups (
(?:...)): Use these when you need to group parts of a pattern but don’t need to capture the matched text. This saves a small amount of overhead. - Alternation (
|): Order choices from most to least likely to be matched.
- Specificity: Make your patterns as specific as possible to reduce backtracking (e.g., use
RegexOptions.ExplicitCapture: Can be used to prevent all groups from capturing unless explicitly marked with(?<name>...)or(?:...), potentially saving allocations if you only need a few specific captures.- Timeout (
RegexOptions.None,TimeSpan timeout): For patterns that might be subject to “Regex Denial of Service (ReDoS)” attacks due to catastrophic backtracking on malicious input, always specify a timeout (new Regex(pattern, options, timeout)). This prevents the regex engine from consuming excessive CPU time. Regex.Escape()andRegex.Unescape(): Use these static methods when you need to treat user input as literal text within a regex pattern or to convert regex escape sequences back to literal characters.
Regular expressions are incredibly powerful for text processing but can be performance-intensive if used carelessly. By understanding compilation modes, Regex instance reuse, and pattern optimization techniques, developers can harness their full power efficiently.
Key Takeaways
- strings are immutable sequences of characters, optimized for memory and performance. Use
StringBuilderfor mutable string operations to avoid excessive allocations. enumFundamentals: Enums map meaningful names to underlying integral values (defaultint). Choose the smallest suitable integral type to optimize memory where collections of enums are large.- Flags Enums for Bitwise Operations: Use
[Flags]with powers-of-two values for members to enable bitwise combinations of independent options. PreferHasFlag()for readability or direct bitwise&for performance. - Array Basics: Arrays are fixed-size, contiguous memory blocks providing O(1) indexed access. Understand the difference between value type and reference type arrays for memory implications. Avoid array covariance for reference types.
List<T>Internals:List<T>is a dynamic array that grows by reallocating a larger internal array and copying elements (amortized O(1)Add). Pre-allocate capacity when possible to minimize reallocations.InsertandRemoveare O(N).Span<T>for Zero-Allocation Views: UseArray.AsSpan()orList<T>.AsSpan()to create high-performance, allocation-free views over array orList<T>data for slicing and processing.- Hash-Based Collections (Dictionary, HashSet): Offer O(1) average-case performance for lookups, insertions, and deletions using hash tables. Performance depends on good hash functions and effective collision resolution.
- Custom Hashing and Equality: Implement
IEqualityComparer<T>or overrideGetHashCode()andEquals()for custom types used as dictionary keys or set elements, ensuring correct value-based equality. ValueTuple(Modern Tuple): PreferValueTuple(struct) overSystem.Tuple(class) for its stack/inline allocation, named fields, and deconstruction, leading to better performance and readability for lightweight data grouping.- I/O Stream Layers:
Streamis the byte-oriented base.StreamReader/StreamWriteradd buffering and encoding for text.StringReader/StringWriterprovide in-memory text I/O. AlwaysDispose()streams and specifyEncoding. - Temporal Data (
DateTime,DateTimeOffset,DateOnly,TimeOnly):DateTimecan be ambiguous due toKind; preferDateTimeOffsetfor time zone-aware applications, especially for storage and transmission (normalize to UTC).DateOnlyandTimeOnly(C# 10+) simplify date-only and time-only scenarios without time zone complexities.
Guidfor Unique IDs:Guid.NewGuid()generates virtually unique 128-bit identifiers, ideal for distributed systems. Be mindful of their size and potential database fragmentation with random keys.Lazy<T>for Deferred Initialization: UseLazy<T>to create expensive objects only when they are first accessed. Choose the appropriateLazyThreadSafetyModefor concurrent scenarios (ExecutionAndPublicationfor full safety,PublicationOnlyorNonefor performance if applicable).RandomPseudorandomness & Thread Safety: Create a singleRandominstance and reuse it to avoid identical sequences.System.Randomis NOT thread-safe; uselock,ThreadLocal<Random>, orRandom.Shared(.NET 6+) for concurrent access. For cryptographic randomness, useRandomNumberGenerator.RegexCompilation & Performance: ReuseRegexinstances. UseRegexOptions.Compiledfor frequently used patterns. For ultimate performance and compile-time validation, leverage the[GeneratedRegex]source generator (.NET 7+). Optimize regex patterns themselves to avoid catastrophic backtracking.
Where to Go Next
- Part I: The .NET Platform and Execution Model: Delving into the foundational environment of .NET and how C# code is compiled and executed.
- Part II: Types, Memory, and Core Language Internals: Exploring the fundamental concepts of C# types, memory management, and the Common Language Runtime’s inner workings.
- Part IV: Advanced C# Features: Generics, Patterns, LINQ, and More: Unlocking C#’s powerful and expressive features, delving into new programming paradigms, dynamic capabilities, and low-level compiler interactions.
- Part V: Concurrency, Performance, and Application Lifecycle: Covering critical aspects of building and maintaining high-performance C# applications, including asynchronous programming, optimization, debugging, and deployment.
- Part VI: Architectural Principles and Design Patterns: Understanding the overarching principles and established design patterns for structuring robust, maintainable, and scalable C# systems.
- Appendix: A collection of resources, practical checklists, and a glossary to support the learning journey.